

If you are like me, I always look forward to reading (here writing) a company's Year in Review and this year is no different. However, as I reflect back on 2022, I realized we achieved a five year anniversary. An anniversary of completing a very big vision of transforming customer’s cloud object storage such as AWS S3 into the first stream-based Search+SQL Analytic Database. Initially providing access via the Elastic (Search) API, then Presto (SQL), at scale and in production. And still the only solution that is 100% native object storage: no expensive memory caching, ssd storage, or even data movement.
This idea and vision at the time was big. The belief that cloud object storage would become what it is today and be an analytic foundation, to say the least, was a crazy idea. Everyone we talked to, from market analysis, to venture capitalist, to thought leaders, all thought it did not make sense. However, we knew it was the future, we just needed a few (ok several) codes to be cracked via new technology and architecture. So in 2016, my colleagues and I set out on this mission.
Chaos Messaging in 2017
Originally thinking SQL access would be our first go to market, going after business intelligence; we began to see a bigger opportunity in logs at scale, which required Search style access. As a result, in 2018 we focused on log management use-cases replacing the ELK stack when cost and complexity of Elasticsearch got way too painful (think TB to PB type scale); all the while not requiring customers to change their application and/or tooling. And yet, this vision of reimagining the entire data journey, on cloud object storage, has stayed the same since 2017, we just swapped Search for SQL first.
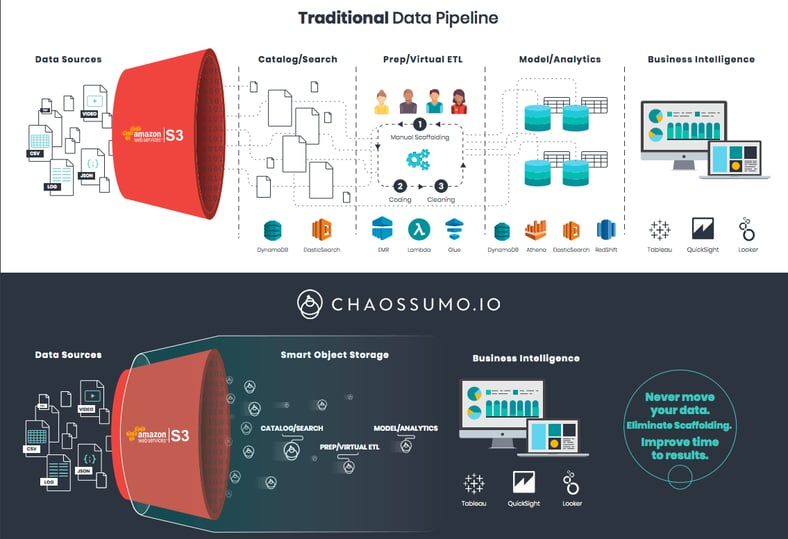
In the early days of log analytics, there was some explanation of why one would want to manage logs with such a platform, such a vision. However, we found that companies were already sending their data to S3, due to fear that their data pipeline and/or database might fail. As a result, we just activated this data. And every year since, the market more and more saw and got what we were doing and why. Today the market analysis and venture capitalist simply ask, "how did you know?" For us chaosians, it was obvious, we just needed to show it in action. We just needed to turn S3 (or equivalent) into a live/native analytic database.
Chaos Messaging in 2022
Since those early days, we have continued to extend the ChaosSearch platform to include workloads such as Observability, Security, & App Insights, where we continue to provide unlimited retention, streamlining/automating the entire data journey (from raw source into operational / business value).
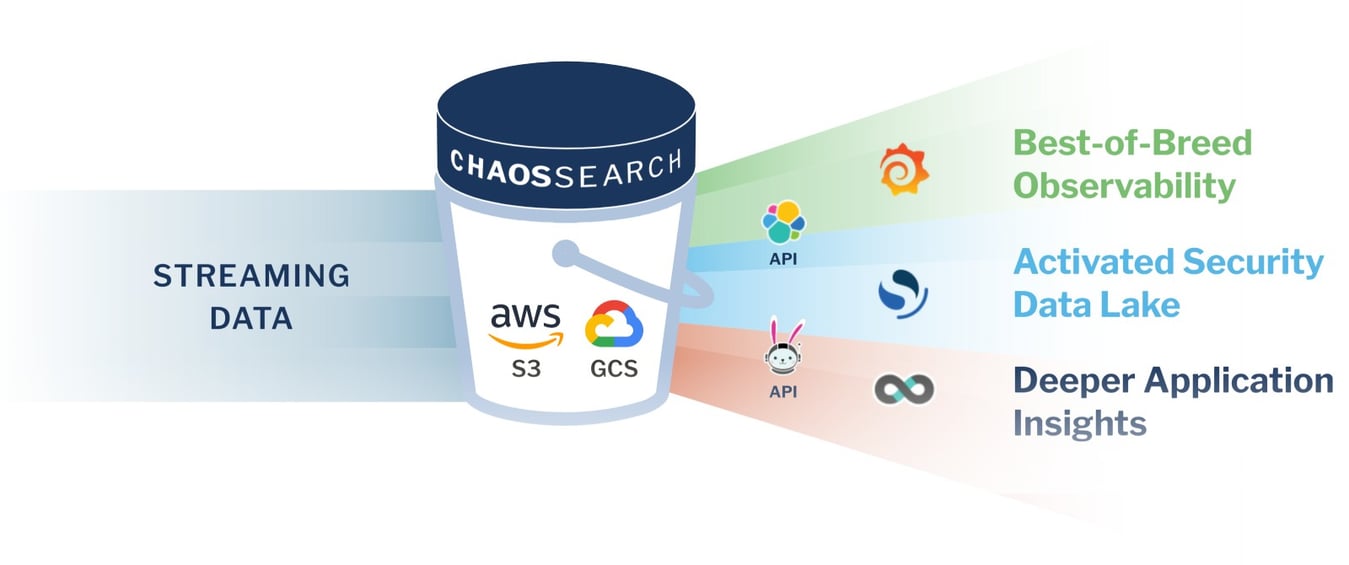

Acknowledging this five year journey & anniversary is of some note; however, it's really just the beginning, just the foundation of more to come. For 2023 will be the year that Smart Object Storage® comes into its own, where ChaosSearch is leading the charge for both operational and business intelligence use-cases.

