

With its simplicity, flexibility, and cost-efficient characteristics, Amazon Simple Storage Service (Amazon S3) cloud object storage has become the preferred platform for collecting, analyzing, and retaining today’s growing mountain of diverse and disjointed enterprise data.
And as Amazon Web Services (AWS) continues to grab market share in the hyperscale IaaS/PaaS/SaaS marketplace, organizations of every size are leveraging Amazon S3 to underpin a variety of use cases, such as:
- Running cloud-native and mobile applications/web services,
- Archiving data for regulatory and compliance purposes,
- Enabling disaster recovery from the cloud,
- Establishing enterprise security data lakes to reduce SIEM costs and improve visibility, and
- Centralizing log data from cloud applications and services to enable application observability and deeper user insights
This blog features an in-depth look at the current state of Amazon S3 object storage. You’ll discover exactly what Amazon S3 cloud storage is, why it’s become so popular, and the key benefits and challenges enterprises face when storing data with the world’s leading cloud storage platform.

What is Amazon S3 Cloud Object Storage?
Amazon S3 is a high-performing cloud object storage service offered by AWS. Although the concept of object storage has been around since the mid-1990s, it only began to gain true popularity after AWS began offering it as their first cloud service in 2006.
Unlike traditional databases that store relational data in a structured format (rows and columns), Amazon S3 object storage uses a flat, non-hierarchical data structure that enables the storage and retention of enormous volumes of unstructured data.
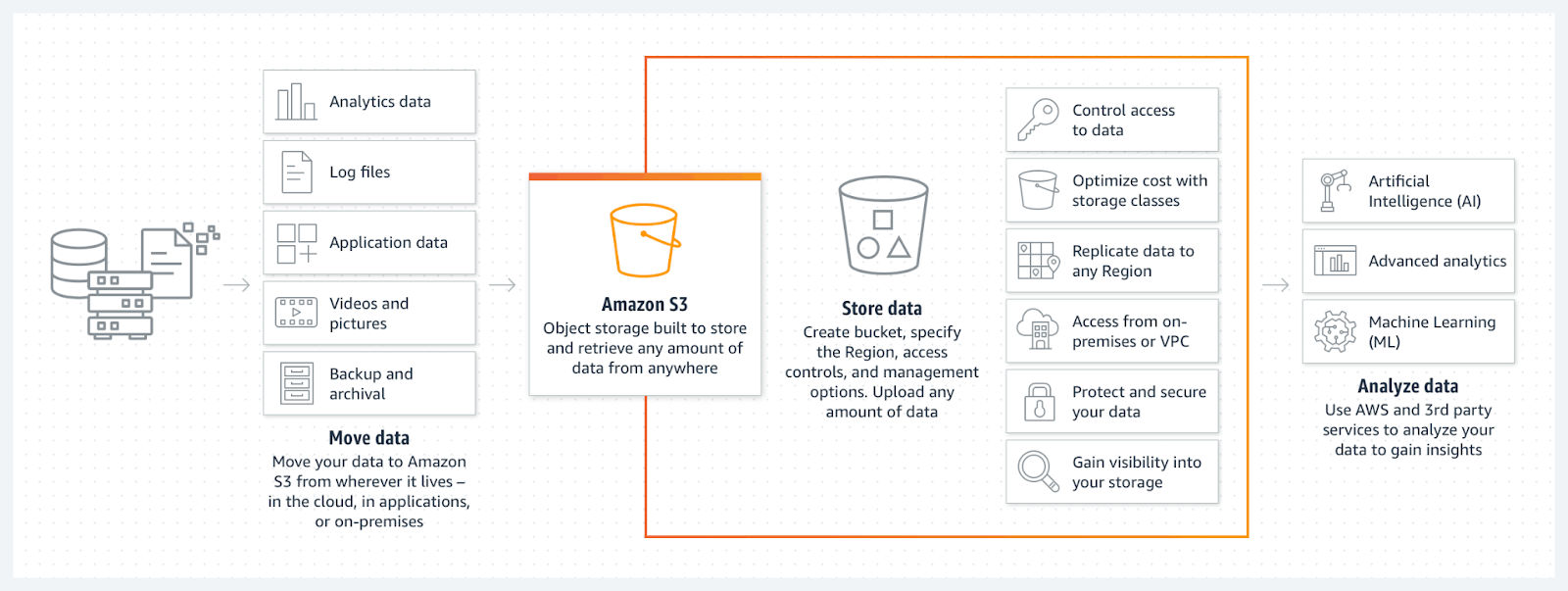
With Amazon S3 object storage, AWS customers can aggregate structured and unstructured data from a variety of sources, securely store data in the public cloud, and analyze the data using both AWS and 3rd-party analytics services.
Three key factors have contributed to the dramatic rise and ongoing popularity of object storage:
- Adoption of Cloud Computing - The killer application for object storage is unquestionably cloud computing. An object stored in the cloud is given an address that allows external systems to find it no matter where it’s stored, and without knowing its physical location in a server, rack, or data center.
- Meeting Compliance Requirements - Object storage includes metadata that represents an instruction manual for users. For compliance regimes that demand strict constraints on data use, object storage metadata represents an essential guardrail.
- Unstructured Data Growth - Over the past decade, enterprises have seen exponential growth in unstructured data from a variety of sources. Object storage can store data in “any/all formats” that wouldn’t otherwise fit into the rows and columns of a traditional relational database, such as emails, photos, videos, logs, and social media.
5 Strengths of Amazon S3 Object Storage
1. Scalability
Amazon S3 object storage provides a highly scalable repository for all kinds of unstructured data. AWS’s pay-as-you-go model for data storage in S3 means that organizations can start small and scale their usage over time, with AWS’s global network of data centers providing what essentially amounts to unlimited storage space.
And it isn’t just your storage space that scales - it’s also your ability to execute requests on your S3 buckets. S3 automatically scales to manage high request rates of up to 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in a bucket.
AWS users can also use partitioning and parallelization techniques to further scale read/write operations in Amazon S3.
2. Data Protection and Storage Durability
Data protection is all about safeguarding your data against corruption, compromise, or loss. Amazon S3 object storage provides excellent data protection by storing all objects redundantly on multiple devices across a minimum of 3 discrete AWS data centers (each with redundant power, networking, and connectivity) in an AWS Region. Storage redundancy prevents data loss in the event of a device failure.
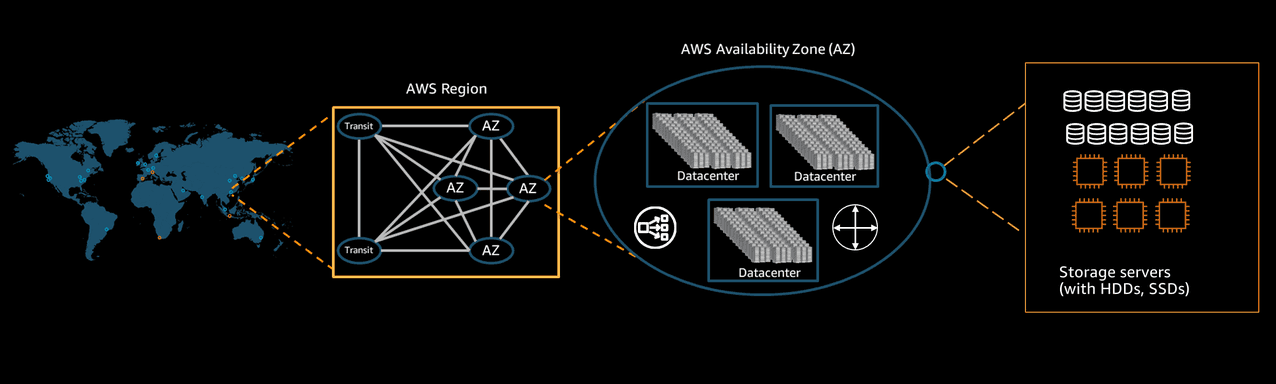
Amazon uses the concept of Availability Zones (AZs) to ensure that data in cloud object storage can survive an entire facility failure. Each AZ consists of one or more physically separated data centers in the same Metropolitan area. By replicating objects across multiple AZs, Amazon ensures that customers can always access their data with 0 downtime - even in the event of a total site failure.
AWS defines durability as the probability that an object in cloud storage will remain intact and accessible after a period of one year. Across all storage tiers, Amazon S3 object storage delivers 99.999999999% durability. In practice, this means that if you stored 10,000 objects in S3, you could expect to lose a single object every 10,000,000 years.
Highly durable AWS object storage is a hair's-breadth away from making data loss events a thing of the past. Features like secure access permissions, versioning, backups, and cross-region replication allow organizations to essentially remove the possibility of a data loss event that impacts operations or compliance.
3. Accessibility
Data stored in the AWS cloud can be accessed over the Internet from anywhere in the world. S3 buckets are highly secure and private by default, but users can also choose to make their S3 buckets publicly available with a few simple configuration changes.
There’s also the Amazon S3 API, which enables programmatic access to data stored in S3 buckets, allowing external developers to write code that uses S3 functionality or accesses data in their cloud object storage.
4. Cost
Cloud computing has made us all richer. By moving data storage from on-prem servers and into the cloud, organizations have been able to reduce their capital costs and accelerate innovation. Massive data centers give AWS powerful economies of scale, making Amazon S3 object storage the most cost-effective storage option for enterprise data.
S3 Storage Classes allow AWS customers to lower their data storage costs even further, with six classes of cost-optimized object storage that satisfy a full spectrum of data access and resiliency requirements.
At one end of the spectrum, Amazon S3 Standard is generally the best choice for regularly accessed data. At the other end, S3 Glacier Deep Archive offers the lowest cost storage for long-term archive data and data preservation use cases.
READ: Eliminate Data Transfer Fees from Your AWS Log Costs
5. Data Security
Amazon S3 object storage delivers a range of security capabilities that help enterprises control and manage data access.
Amazon S3 buckets can be configured to block public access, a setting that’s enabled by default for all newly created buckets. Amazon S3 automatically encrypts all data uploaded to Amazon S3 buckets. From there, administrators can manage data access with features like Identity and Access Management (IAM), Access Control Lists (ACL), S3 Access Points, and S3 Object Ownership.
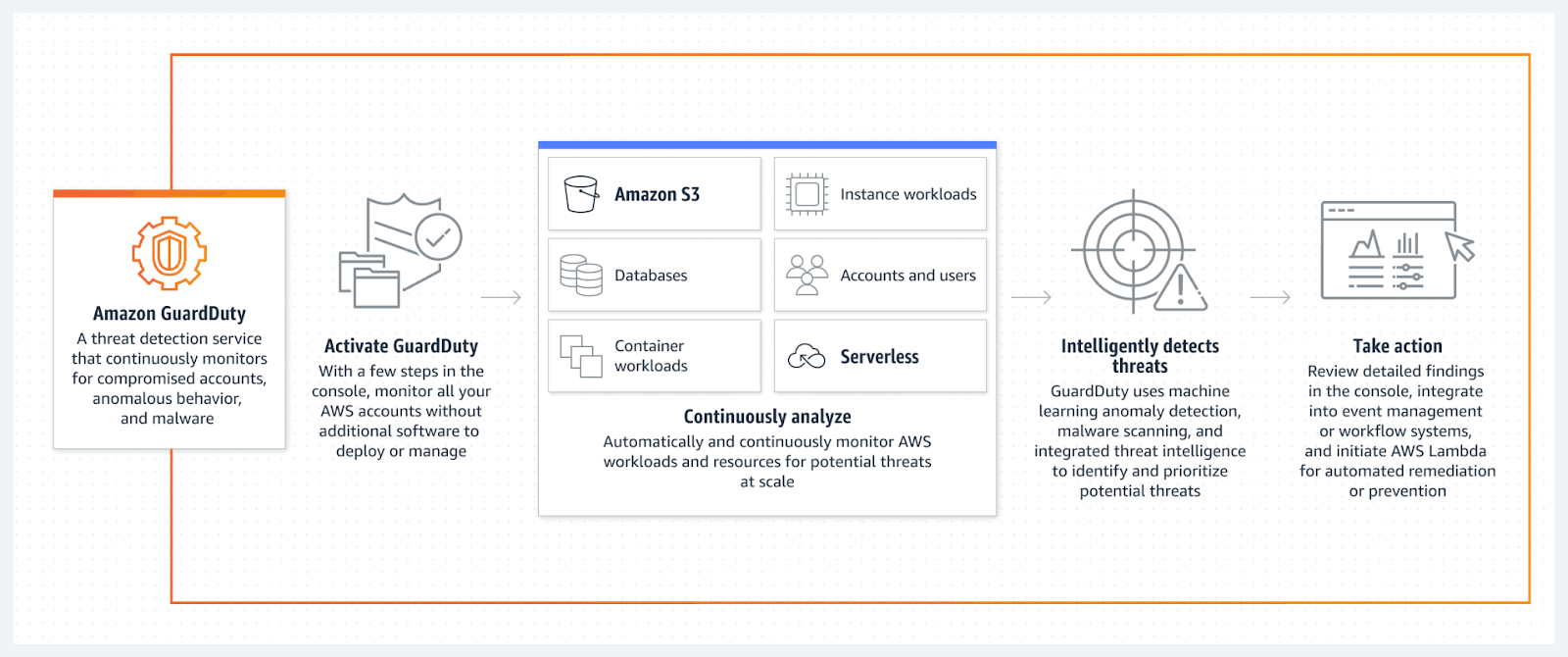
Along with access management features like IAM and ACLs, AWS S3 deployments can be continuously monitored for malware and cyber threats using the Amazon GuardDuty threat detection service.
Enterprises with stringent compliance needs can also use S3 Object Lock to enforce data retention rules, or verify the integrity of their data with any of four supported checksum algorithms.

S3 Analytics: 3 Potential Pitfalls of Object Storage
Benefits like cost-effectiveness and scalability have driven enterprise organizations to start using Amazon S3 object storage for their data needs.
Yet despite the growing popularity of S3, data-driven organizations have historically faced challenges when it comes to identifying, standardizing, and analyzing log data in S3 object storage.
Three major factors can make object storage analytics feel complicated and distant for enterprise organizations.
1. Data Visibility Challenges
Data lakes have always been a promising use case for Amazon S3 object storage, but as organizations ingest exponentially more data into S3 buckets, it becomes more complex and time-consuming to catalog the data or implement features like metadata tags that help data scientists know what data is available in S3 buckets.
The term “data swamp” was coined to describe this exact situation, where an influx of unstructured, untagged, poorly organized, or poorly managed data slows down data lake operations and prevents organizations from leveraging their data to its full potential.
READ: 10 AWS Data Lake Best Practices
2. Unstructured Data Format
Amazon S3 object storage is not a traditional database.
While traditional database applications were designed and developed to meet yesterday’s requirements for managing structured and relational data in tables (columns and rows), Amazon S3 was designed to meet today’s requirements for storing and managing diverse and unstructured data from a variety of disparate sources.
There’s no problem with using a relational database for structured data and Amazon S3 for unstructured data, but note the following: Most data analytics and business intelligence (BI) tools are set up to analyze data in relational databases. Since the data you store in Amazon S3 object storage is not relationally formatted, most architectures require you to process and transform it before it can be efficiently analyzed.
3. Data Movement and ETL
Data movement and the ETL process are among the biggest barriers when it comes to leveraging Amazon S3 object storage for analytics.
Before you can run analytics on unstructured data in your cloud object storage, you’ll need to invest valuable time and resources to clean and prepare your data, transform it into an analytics-friendly format, and load it into your cloud data warehouse, analytics platform, or business intelligence tool - a process known as ETL.
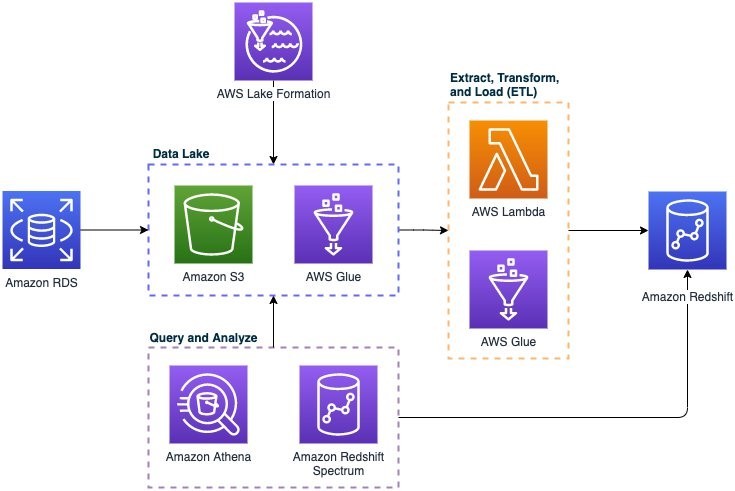
In this AWS S3 analytics architecture, Amazon S3 is used as a data lake storage backing for an Amazon Redshift data warehouse. Cloud data warehouses like Amazon Redshift can provide excellent performance for analytics queries, but the ETL process makes it complex, costly, and time-consuming to move data into the data warehouse - especially at scale.
Not only is ETL time-consuming, with data cleaning and preparation taking up to 80% of the total time to perform data analytics, it introduces additional complexity, increases compute and storage costs, creates data privacy and compliance gaps, and delays insights, ultimately limiting the value of your data.

A Modern Way to Activate Your Amazon S3 Object Storage for Analytics
Introducing Chaos LakeDB, a new way to overcome AWS S3 analytics challenges and activate your S3 object storage for analytics without any physical data movement. While other AWS S3 analytics solutions require costly and time-consuming ETL, Chaos LakeDB integrates directly with Amazon S3 to enable seamless analytics on top of data lake storage capabilities and eliminate the need for ETL.
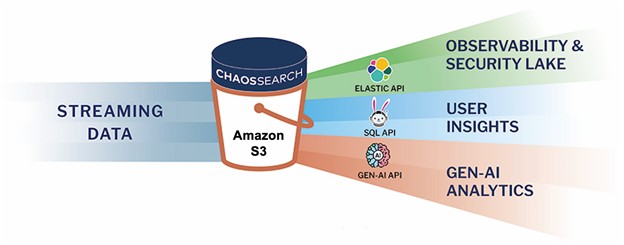
Chaos LakeDB transforms your Amazon S3 or GCP cloud object storage into a live analytics database with support for full-text search, SQL, and GenAI workloads, with no data movement and unlimited data retention.
Chaos LakeDB leverages our innovative proprietary technology to aggregate diverse data streams into one data lake database, automate data pipelines and schema management, and enable both real-time and historical insights with lower management overhead, no stability issues, no data retention tradeoffs, and up to 80% cheaper than alternatives like Elasticsearch.
READ: Optimize Your AWS Data Lake with Data Enrichment and Smart Pipelines
Ready to learn more?
Watch our free webinar Data Architecture Best Practices for Advanced Analytics to learn more about developing your cloud analytics architecture with Amazon S3 and Chaos LakeDB.
Additional Resources:
Read the Blog: Understanding Amazon Security Lake: Enhancing Data Security in the Cloud
Watch the Webinar: Choosing an Analytical Cloud Data Platform: Trends, Strategies, and Tech Considerations

