

Serverless services on AWS allow IT and DevSecOps teams to deploy code, store and manage data, or integrate applications in the cloud, without the need to manage underlying servers, operating systems, or software. Serverless computing on AWS eliminates infrastructure management tasks, helping IT teams stay agile and reducing their operational costs - but it also introduces the new challenge of serverless log management.
In the past, IT teams could install a logging agent on each of their servers to collect logs and send them to a centralized location for analysis. But when it comes to logging in a serverless architecture, there’s no access to that underlying infrastructure. Instead, IT teams must capture logs directly from individual AWS services to support use cases like application monitoring, cloud observability, and security operations.
In this week’s blog, we’re taking a closer look at serverless log management and the four challenges you’ll encounter in the course of collecting and managing serverless logs on AWS.

What is Serverless Log Management in AWS?
Serverless log management is the process of capturing, aggregating, normalizing, and analyzing log data from serverless AWS services. It also includes securing log data against unauthorized access and managing log data retention for cost management and compliance purposes.
In traditional log management, IT teams can gather log data from the servers, OS, and software applications they operate. But in serverless environments, IT teams can’t access these logs and are limited to gathering logs directly from AWS serverless services.
Serverless technologies on AWS fall into three categories:
- Data Storage (Amazon S3, EFS, DynamoDB, RDS Proxy, Aurora, Redshift, and Neptune),
- Compute (AWS Lambda and Fargate)
- Application Integration (Amazon EventBridge, SQS, SNS, and API Gateway, AWS Step Functions and AppSync).
How Does Serverless Log Management Work in AWS?
Serverless log management in AWS depends on Amazon CloudTrail, a cloud-based service that automatically captures, aggregates, and manages logs from serverless applications on AWS. CloudTrail is enabled by default on newly-created Amazon accounts, with CloudTrail event data being retained for a default period of 90 days.
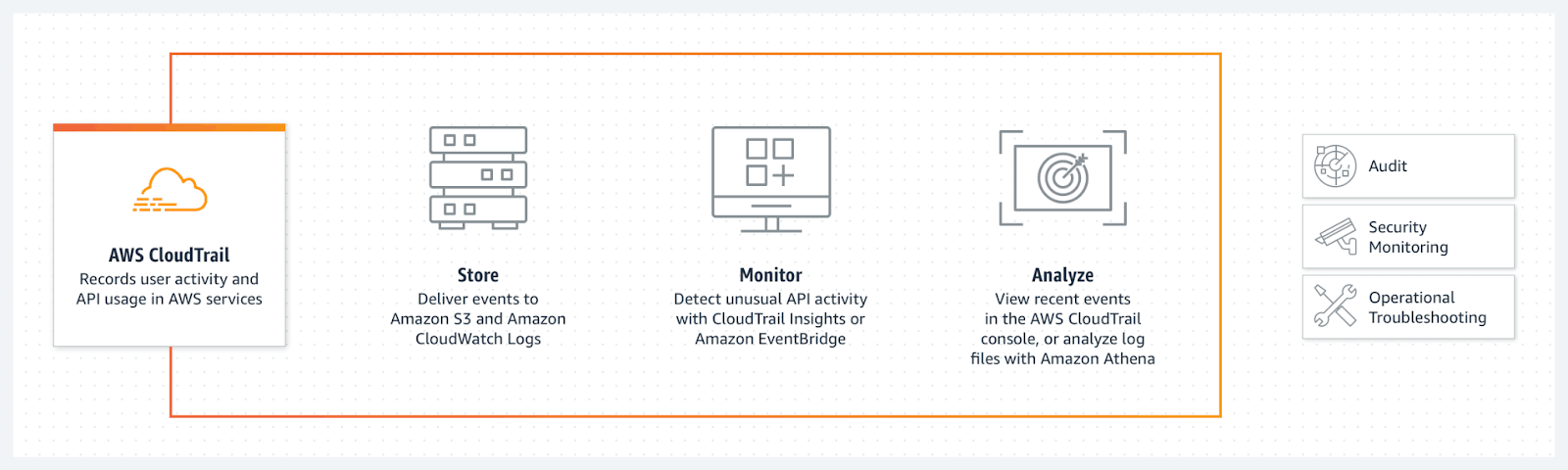
CloudTrail allows AWS customers to log user activity and API usage across serverless AWS services.
With CloudTrail, user activity and API calls from across your AWS infrastructure are logged as CloudTrail which can be viewed in the CloudTrail console. CloudTrail records two types of events:
- Management Events - Control plane actions on resources, such as creating or deleting a bucket in Amazon S3.
- Data Events - Data plane actions without a resource, such as writing a new object in an Amazon S3 bucket.
Once an event has been logged in Amazon CloudTrail, AWS customers have several ways to consume the data.
CloudTrail allows AWS customers to view a 90-day history of control plane actions on their account. Another way to consume the data is by enabling AWS CloudTrail Lake, a managed data lake that allows AWS customers to run SQL-based queries on events.
Additionally, AWS users can build customized “trails”, similar to data pipelines, that deliver event data from Amazon CloudTrail to a different application or service. Users can deliver event data to storage services like Amazon S3, cloud resource monitoring services like Amazon CloudWatch Logs or EventBridge, log analysis tools like Amazon Athena, or third party tools like Splunk or Sumo Logic.
For DevOps teams logging serverless applications, AWS Lambda monitors Lambda functions automatically and pushes the logs directly to Amazon CloudWatch. CloudWatch is a cloud monitoring and management service where IT organizations can centralize their log data, monitor their full technology stack, and configure customized alerts to take automated actions.

4 Serverless Log Management Challenges You’ll Encounter
1. Non-Standard Logging Formats
Serverless AWS services produce many different kinds of logs with no standardized format. Services like Amazon S3 and E2C generate logs in a structured format, while developers often use unstructured logging for AWS Lambda functions. The lack of a standardized format means that logs must be parsed and normalized before they can be queried in a systematic way.
2. Complex Log Management Infrastructure
Serverless log management on AWS scales in complexity based on the number of sources and the number of destinations for log data. A complex serverless log management architecture could include:
- Initially capturing logs in CloudTrail,
- Consuming some logs in CloudTrail Event History,
- Consuming some logs in AWS CloudTrail Lake,
- Delivering some logs to Amazon CloudWatch for resource monitoring and observability,
- Using Amazon Kinesis Firehose to manage data transformation and delivery,
- Delivering some logs to a third-party security tool for short-term monitoring and alerting,
- Delivering some logs to Amazon OpenSearch for interactive querying,
- Delivering some logs to Amazon Redshift for SQL-based analysis,
- Delivering some logs to Amazon S3 for long-term data storage that fulfills compliance and long-term threat detection use cases,
- And more…
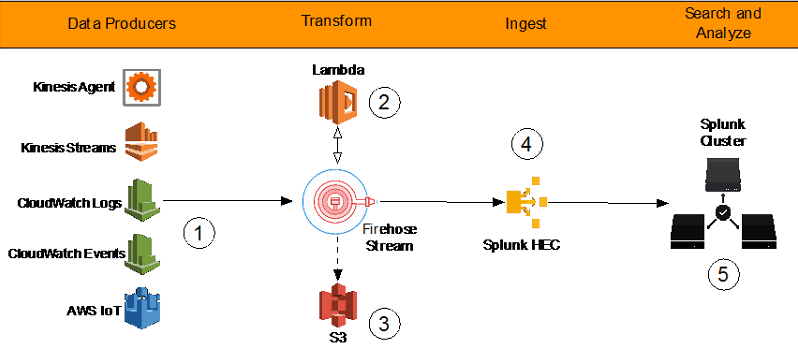
Log management infrastructure scales in complexity with the number of data sources and destinations.
As the number of data sources and destinations increases, so too does the management burden of maintaining data pipelines and writing Regex expressions or filters to format logs correctly and send them to the right destination.
Read: Troubleshooting Cloud Services and Infrastructure with Log Analytics
3. Data Movement and Duplication Costs
A third challenge of serverless log management in AWS is the potentially high cost of data movement and duplication. Storing your logs in CloudTrail, sending a copy to Amazon S3, and sending additional copies to third-party analytics or security tools means you’ll be incurring data transfer and storage costs multiple times over on the same set of data.
4. High Cost of Data Retention
As organizations deploy an increasing number of applications and services in the cloud, they also generate an increasing volume of logs. This growing volume of log data results in ballooning data retention costs, especially for IT teams that are already duplicating log data across multiple applications or data stores.
The default retention period for logs in Amazon CloudTrail is 90 days. For logs that are delivered to Amazon CloudWatch, the default retention period is indefinite. Lengthy data retention periods can become cost-prohibitive as the daily volume of log data increases. Devs can reduce log data retention windows to reduce storage costs, but it is often difficult to know ahead of time which logs will be needed and which can be discarded.
Optimize Serverless Logging Workflows with ChaosSearch
The ChaosSearch data lake platform delivers an innovative approach to serverless log management on AWS, helping IT organizations overcome key challenges to achieve robust and cost-effective serverless log management.
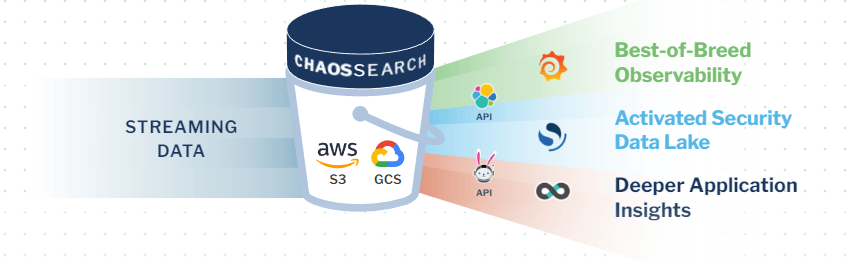
ChaosSearch delivers a simplified process for serverless log management in AWS.
ChaosSearch connects directly to Amazon S3, transforming your cloud object storage into a hot data lake for serverless log analysis. The process is simple:
- Capture serverless logs using Amazon CloudTrail and CloudWatch.
- Deliver log data to Amazon S3.
- Leverage our proprietary Chaos Index® technology to index your log data for fully searchability with up to 20x data compression.
- Build virtual views in Chaos Refinery® to query and analyze log and event data with full-text search and SQL-based queries.
- Visualize your data and build dashboards with built-in Kibana Open Distro.
ChaosSearch uses a schema-on-read approach to log analysis, allowing organizations to index log data at scale without normalizing the data or creating schema beforehand.
Chaos Index® data compression shrinks your log data, removing practical limitations on data retention and enabling long-term log analytics use cases like advanced persistent threat detection, root cause analysis, and security compliance. Indexed log data is cost-effectively stored and analyzed directly in Amazon S3 with no data duplication and no unnecessary data movement.
Ready to learn more?
Start a Free Trial of ChaosSearch and discover the new best way to analyze and manage logs from serverless services on AWS.

