

As organizations increasingly adopt serverless architectures and embrace the benefits of microservices, managing logs in this dynamic environment presents unique challenges.
In this blog, we’re taking a closer look at the differences between serverless and traditional log management, as well as 8 challenges associated with log management for serverless microservices.

Log Management from Monolithic Applications to Serverless Microservices
Log Management for Monolithic Applications
Before the proliferation of cloud computing in the mid-2000s, enterprise developer teams designed and delivered software products with a traditional monolithic architecture.
Monolithic applications combine the user interface and data access layers for multiple features and capabilities into a single unified application. A typical monolithic application consists of a client-side UI, a server-side database (often in an RDBMS), and a server-side application that could handle customer requests, execute business logic, and update or retrieve data from the database. The applications would be deployed on a server in the organization’s data center with IT Ops teams responsible for maintaining the server and ensuring service availability.
Because they consist of a single executable, log management for monolithic applications is relatively simple. The log data can be captured from the application and written into a log file, which developers may access and analyze to diagnose application issues or investigate anomalous behavior.

Log Management for Microservice Applications
By the early 2010s, enterprise development teams were transitioning to microservice architectures as a means of overcoming the software development challenges associated with monolithic applications.
Because monolithic apps were structured as a single executable, all components of the application had to scale together. This resulted in inefficient resource utilization. The components of a monolithic app were tightly coupled and often interdependent, which was slowing down release cycles and making it difficult to introduce new features or technologies. Whenever a new feature was introduced, developers had to extensively test the entire application to ensure that every other feature was still working. All of these factors slowed down the application development life cycle, stifled collaboration, and locked developers into using the same technologies for the entire application lifecycle.
Unlike monolithic applications where the entire application is a single executable, microservice applications are composed of small, distributed services that communicate with each other through APIs and may be independently developed, tested, and deployed.
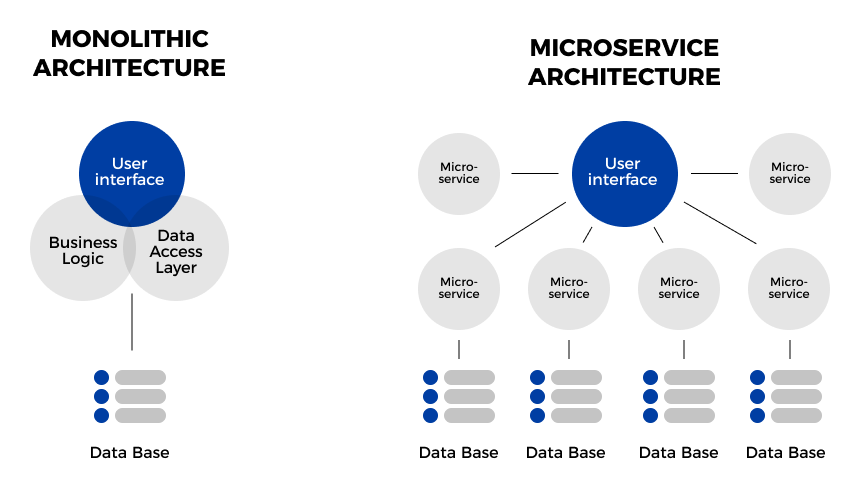
In a typical microservice-based architecture, each microservice component corresponds to a specific application feature and delivers a self-contained piece of business functionality. This means that developers can update or modify individual services without having to make changes to other parts of the application.
Adopting a microservices architecture gave enterprise developers more agility, allowing for faster development cycles and accelerating innovation and time-to-market. Not only that, but the emergence of cloud computing meant that microservices could be deployed on cost-effective and highly scalable public cloud infrastructure instead of being hosted in enterprise data centers.
Log management for microservice applications is more complex than for traditional monolithic applications. We have multiple independent services running and communicating with each other to support application features, and generating their own logs along the way. To analyze this data, developers need a distributed logging infrastructure that can capture logs from multiple sources, aggregate and centralize them, then transform and process the data to enable log analytics applications.
Serverless Computing: A New Way to Run Your Application
While microservice architecture changed how applications were designed and developed, serverless computing changed how applications - including microservice applications - could be deployed and operated in the cloud.
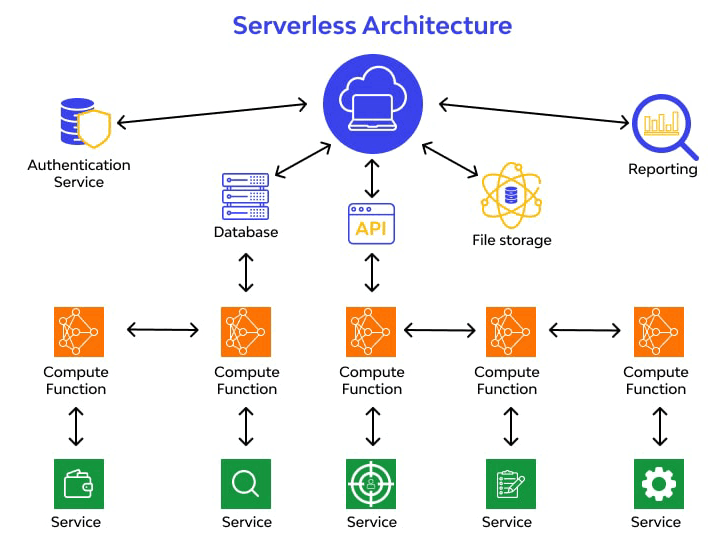
In a serverless execution model, application code is converted into serverless functions that can be executed on-demand by a serverless compute service (e.g. AWS Lambda, Azure Functions, etc.) in response to an HTTP request, database update, or any other event pre-configured by the developer.
The term “serverless” doesn’t mean that servers aren’t involved - rather, it indicates that public cloud providers automatically provision and manage all of the underlying servers and infrastructure needed to execute the function. In this way, serverless computing reduces the operational overhead associated with running microservice applications and enables developers to focus their efforts on feature updates and innovation instead of maintenance and operations.
Log Management for Serverless Microservices
A serverless microservice is a microservice (an independent component of an application with a specified role) that developers set up to run as a serverless function, executing automatically in response to a predetermined event or trigger.
Serverless microservices combine the advantages of microservice architecture (e.g. granular functionality, loose coupling with other application components, easier development and testing, etc.) with the advantages of serverless computing (e.g. scalable on-demand execution, low operational overhead, etc.) to streamline the software development process, enable CI/CD, and reduce operational costs for DevOps teams.
When it comes to log management in serverless environments, developers can choose between synchronous or asynchronous logging. The former uses a logging library or service (e.g. Winston, loglevel, NLog, etc.) to send logs to a centralized logging system as the serverless function finishes executing. The latter uses cloud-native applications like Amazon CloudWatch to stream logs from serverless functions into a persistent storage location.

8 Challenges of Log Management for Serverless Microservices
Adoption of microservices architecture and serverless computing technology has changed how organizations develop, deploy, and monitor cloud-native applications.
Below, we highlight 8 log management challenges associated with serverless microservices.
1. Cold Start Delays
Serverless functions experience cold starts when they are invoked after a period of inactivity - usually between 5 and 30ish minutes depending on the platform. When a cold start takes place, you'll experience some latency before your function is invoked while your serverless computing platform (e.g. AWS lambda or Azure Functions) downloads the code for your function and spins up an execution environment. This period of latency is known as a cold start delay and can last for as little as 100ms or up to 1s or more.
Cold start delays can impact log collection and timing accuracy. They can also negatively impact the performance of your applications, especially in cases where real-time or near real-time processing is required.
2. Distributed Nature
The distributed nature of serverless microservices makes serverless log management more complex compared to managing logs from monolithic applications.
Unlike a monolithic architecture where you have a single application running on one server, a serverless microservices architecture incorporates multiple cloud-native microservices with multiple functions that may be spread across several cloud providers and regions.
Instead of collecting and analyzing log data from a singular monolithic source, developers working with serverless microservices must capture and centralize log data from numerous sources to support downstream analytics and enable true application observability.
3. Log Formats
When developing applications in a microservices architecture, enterprise DevOps teams can choose different programming languages and runtime environments for each microservice based on its specific needs and functionality.
This also means that the various microservices in a serverless architecture may be using different logging frameworks or writing their logs in different formats. A lack of consistent logging formats between serverless microservices makes it more complex, costly, and time-consuming to parse and normalize the log data.
4. Scale
Serverless microservices are hosted on highly scalable public cloud infrastructure and can rapidly scale up or down in response to changes in demand for a service. Whether a function is triggered just one time or 100,000 times in a given time period, serverless computing platforms in the cloud have the necessary resources to execute every request.
However, the inherent scalability of serverless microservices also means that enterprises need scalable logging infrastructure that can capture log data from all of these function executions, no matter the level of demand.
5. Cost
Runaway costs are a significant challenge associated with serverless log management.
The inherent scalability of serverless microservices means that your logging costs can scale as well. As the demand for a serverless microservice grows and the number of serverless function invocations per time period increases, the cost of capturing, aggregating, storing, transforming, and analyzing the log data increases exponentially. This is especially true if your log management software charges based on the volume of data you ingest - and most do.
Another potential cause of high log management costs is unnecessary data movement and duplication. Storing logs in multiple locations (e.g. inside your log monitoring software, in a security operations data lake, and in a third-party log management tool) means that you’ll be paying data egress and storage costs multiple times for the same set of data.
6. Context
Context is crucial for developers seeking to make sense of log data from serverless applications.
Since serverless functions are independent and execute in response to predetermined events, developers often need additional context in their logs to effectively trace requests through multiple microservices or investigate the root cause of an application performance issue or software bug.
AWS Lambda uses a context object that allows serverless functions to access contextual information from the platform at runtime, such as the current process instance and unique identifier code for the request that triggered the function. This information makes it easier to correlate logs from a specific function invocation with events from across the microservices architecture to support log analytics use cases.
7. Complexity
We've already discussed how the distributed nature of microservices architecture necessitates more complex infrastructure for capturing and aggregating logs from multiple sources - but what about after that? As it turns out, sending your log data to multiple destinations for consumption can also be a huge driver of complexity.
A complex log management architecture for serverless microservices might include a cloud-native log monitoring service, an ETL service that manages data transformation and delivery, and multiple destinations for log data (e.g. a data lake or long-term data storage repository, data warehouse solution, cloud security tools, or a log analytics tool like Amazon Opensearch Service, etc.).
Sending logs to multiple destinations in a complex log management architecture increases the operational overhead associated with building data pipelines and transforming the log data to enable analytics.
8. Data Storage and Retention Limits
As demand for applications increases and daily log ingestion reaches terabyte scale, storing and retaining log data for long periods gets increasingly expensive and even cost-prohibitive. This is especially true when logs are being ingested, stored, and consumed by multiple applications.
To help control costs, developers may impose data retention limits and reduce the log retention window from the default ~90 days of most log management applications to as little as 3-7 days. Shortening log retention reduces storage costs, but it also eliminates the possibility of analyzing that data in the future to support long-term use cases like advanced persistent threat (APT) hunting or root cause analysis.
Developers can also try to save money by capturing fewer logs from the application infrastructure. This reduces the cost of storing log data, but it can also bury potentially valuable insights and reduce application observability.
Manage Logs from Serverless Microservices with ChaosSearch
ChaosSearch attaches directly to your cloud object storage, enabling a simplified log management architecture that’s highly scalable, cost-effective, and purpose-built to address the challenges of log management for serverless microservices.
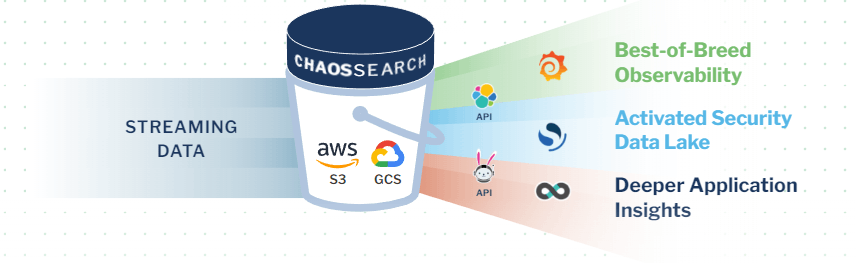
With ChaosSearch, developers can implement an asynchronous approach to serverless logging, streaming logs directly from serverless functions into cloud object storage (e.g. Amazon S3 or GCS) with tools like Amazon CloudWatch.
Once the log data lands in cloud object storage, ChaosSearch automatically indexes the log data for relational queries or full-text search with up to 95% data compression. From there, developers and IT analysts can use our Chaos Refinery® tool and built-in Kibana Open Distro to apply data filtering and transformations, construct virtual views, and visualize their log data to monitor the performance of cloud services, investigate security issues, and gain deeper application insights.
ChaosSearch eliminates unnecessary data movement and duplication, reduces the cost and complexity of log analytics, allows developers to easily normalize logs in different formats, and enables cost-effective data retention to support long-term analytics use cases.
Ready to Learn More?
Check out our free white paper Beyond Observability: The Hidden Value of Log Analytics to discover how you can enhance application observability and gather insights from your logs without paying enormous data storage costs.


