

JavaScript Object Notation (JSON) has become the de facto standard format for writing cloud infrastructure and web application log data - and for good reason. Structured logging with JSON reduces the cost and complexity of extracting valuable insights from log data.
While plain text logs can support use cases like application performance monitoring and security analysis, writing log messages in an unstructured format makes it both time-consuming and costly for data engineers to parse, index, and analyze those logs. With JSON, logs are parsed automatically and stored in a structured format that can be converted into a table (tabularized) to support querying and analytics applications.
But despite the benefits of writing and storing logs in JSON format, data engineers still encounter technical challenges and trade-offs when indexing and querying JSON logs with complex data structures (e.g. multiple nesting levels, nested arrays, and sibling arrays).
In this blog, you’ll discover how analysis of custom and nested JSON poses a challenge for data engineers, how enterprises are solving this problem today, and the best way to index and query JSON logs.

Why JSON Logging?
JSON is a lightweight data interchange format derived from the JavaScript/ECMAScript programming language.
JSON is becoming an increasingly common choice for developers when it comes to writing, storing, and analyzing logs from web applications and cloud infrastructure. Several AWS web services (e.g. AWS CloudTrails, AWS Transfer Family, etc.) now deliver logs in a structured JSON format, and AWS customers can also use Amazon CloudWatch to monitor JSON-formatted logs.
Here’s why developers are choosing JSON logging:
JSON Logs are Human Readable
In plain-text log files, each log entry includes a timestamp and an unstructured string of characters that can be difficult to interpret without prior knowledge of the logging format. Logs written in the JSON schema are formatted in key:value pairs, making it much easier for developers and analysts to read and interpret the data.
JSON Supports Multiple Data Types
A JSON value can be a string, a number, a JSON object, an array, a boolean, or null. Support for nested JSON objects and nested arrays give developers a lot of flexibility to capture valuable data from web applications in their logs.
JSON Logs are Easier to Parse
Plain-text log files are difficult to parse for analysis because all of the data is combined into one string. But because JSON logs are formatted with key:value pairs, the data can readily be converted into a table to support relational querying. As a result, analyzing JSON data is faster, cheaper, and less complex than analyzing other types of unstructured log files.

Why is it so hard to Query JSON?
As JSON logs increase in complexity — with nested objects, nested arrays, and multiple nested levels — fully indexing those logs results in either:
- Row Explosion, which increases index time and leads to prohibitively high data storage costs, or
- Column Explosion, which makes it increasingly difficult and time-consuming to write clear queries that generate useful insights.
To understand why this is the case, let’s explain the concept of JSON Flattening.
What is JSON Flattening?
To make JSON logs available for querying and analytics, engineers convert the logs into a table. But when logs contain nested objects, they must be transformed into a flat data structure before they can be tabularized. This process is known as JSON flattening.
JSON flattening transforms JSON logs with nested objects and arrays into a tabular format, but it also results in explosive data growth and unwieldy queries that make it difficult to analyze the data.
To illustrate why, we’ll show you a series of examples detailing exactly what log flattening is doing with nested JSON objects and arrays.
Consider the following, simple/inherently flat JSON object structure to represent employees:

Here’s what it would look like if we took the JSON example shown above and indexed it into a tabular format:
|
first_name |
last_name |
|
John |
Smith |
|
Sally |
Walker |
The flat data structure yields a simple employee index where the field names from JSON objects are conceptually translated into columns of a table and the field values are translated into row data.
Now let’s see what happens when we encounter nested fields. Consider the following example of employee records with multiple layers of nested fields:

When we encounter nested JSON objects in logs, we can use JSON flattening techniques to convert the data into a tabular format. Nested fields will be represented as columns within the same physical row, and will be prefixed with the parent JSON object to clarify their identity.
Here’s how the data in the above example would look after JSON flattening:
|
employee.first_name |
employee.last_name |
employee.address.city |
employee.address.street |
|
John |
Smith |
Chicago |
2 Pine St. |
|
Sally |
Walker |
Seattle |
1 Oak St. |
Every outer-level JSON object can be horizontally flattened into a single column in tabular format, so we still have a manageable number of columns and rows in our data representation relative to the raw data size.
Now let’s see what happens when we add an array of phone numbers to our JSON log and try to flatten the data into a table. Consider the following example:

In this example, John’s employment record has three phone numbers associated with it. If we want to associate each of John’s phone numbers with all other columns in the flattened row representation, we must choose between two approaches: vertical flattening and horizontal flattening.
If we choose vertical flattening, each element in the phone_numbers array will be represented as a separate row:
|
employee.first_name |
employee.last_name |
employee.address.city |
employee.address.street |
employee.phone_numbers |
|
John |
Smith |
Chicago |
2 Pine St. |
5551112222 |
|
John |
Smith |
Chicago |
2 Pine St. |
5553334444 |
|
John |
Smith |
Chicago |
2 Pine St. |
5556667777 |
If we choose horizontal flattening, our data representation will include an additional column for each value in the phone_numbers array:
|
employee.first_name |
employee.last_name |
employee.address.city |
employee.address.street |
employee.phone_numbers.0 |
employee.phone_numbers.1 |
employee.phone_numbers.2 |
|
John |
Smith |
Chicago |
2 Pine St. |
5551112222 |
5553334444 |
5556667777 |
Vertical and horizontal JSON flattening each have their own advantages and disadvantages at the time of indexing and at query-time.
Vertical flattening is necessary to perform aggregations over values in an array, but also means that individual JSON objects will be seen as multiple rows. Row explosion increases the size of the data, increasing index time and multiplying data storage costs.
Queries are simpler when vertical flattening is used, but the expansion of rows when flattening sibling arrays can result in misleading results during aggregation.
Horizontal flattening results in both faster indexing and faster queries, but leads to column explosion that makes it increasingly difficult to write clear and constructive queries without using wildcard naming.
As JSON logs get more complicated, the negative effects of JSON flattening also increase. To illustrate how, let’s extend our JSON flattening example to include a sibling array:

Now, our JSON example has an array of phone numbers and an array of addresses at the same nesting level. How will this sibling array look when we flatten it? Again, we’ll need to choose between the vertical and horizontal JSON flattening approaches.
Here’s what a vertical flattening approach would look like:
|
employee.first_name |
employee.last_name |
employee.addresses.city |
employee.addresses.street |
employee.phone_numbers |
|
John |
Smith |
Chicago |
2 Pine St. |
5551112222 |
|
John |
Smith |
Chicago |
2 Pine St. |
5553334444 |
|
John |
Smith |
Chicago |
2 Pine St. |
5556667777 |
|
John |
Smith |
Boston |
3 Willow St. |
5551112222 |
|
John |
Smith |
Boston |
3 Willow St. |
5553334444 |
|
John |
Smith |
Boston |
3 Willow St. |
5556667777 |
We now begin to see the concerns of representing data with a vertical flattening approach. As sibling arrays are encountered in the data, we will end up increasing the number of rows so that all possible combinations can later be associated and queried.
What started as a single JSON object to represent a single employee, has turned into 6 'rows' of data. Furthermore, adding a 4th phone number and a 3rd address would expand this out to 12 rows. Adding another sibling array to represent employee children would further expand the row count, and so on.
To avoid row explosion, we might try a horizontal flattening approach instead:
|
employee.first_name |
employee.last_name |
employee.addresses.0.city |
employee.addresses.0.street |
employee.addresses.1.city |
employee.addresses.1.street |
employee.phone_numbers.0 |
employee.phone_numbers.1 |
employee.phone_numbers.2 |
|
John |
Smith |
Chicago |
2 Pine St. |
Boston |
3 Willow St. |
5551112222 |
5553334444 |
5556667777 |
Horizontal flattening has a distinct advantage in that we only ever see John as a single row in our dataset, but we’re still running into column explosion that results in unwieldy queries as we try to find all addresses and/or phone numbers for John.
As a final example of how JSON flattening leads to trade-offs between explosive data growth and complex querying, let’s see what happens when we use JSON flattening to tabularize an array nested inside another array:

Each employee now has an array of children, who in turn each have an array of phone numbers. As we can see, our simple employee record is now becoming very difficult to represent in tabular format. Here’s what happens when we use a vertical JSON flattening approach:
|
employee.first_name |
employee.last_name |
employee.addresses.city |
employee.addresses.street |
employee.phone_numbers |
employee.children.name |
employee.children.phone_numbers |
|
John |
Smith |
Chicago |
2 Pine St. |
5551112222 |
Ted |
5557777777 |
|
John |
Smith |
Chicago |
2 Pine St. |
5551112222 |
Ted |
5558888888 |
|
John |
Smith |
Chicago |
2 Pine St. |
5551112222 |
Marie |
5559999999 |
|
John |
Smith |
Chicago |
2 Pine St. |
5553334444 |
Ted |
5557777777 |
|
John |
Smith |
Chicago |
2 Pine St. |
5553334444 |
Ted |
5558888888 |
|
John |
Smith |
Chicago |
2 Pine St. |
5553334444 |
Marie |
5559999999 |
|
John |
Smith |
Chicago |
2 Pine St. |
5555556666 |
Ted |
5557777777 |
|
John |
Smith |
Chicago |
2 Pine St. |
5555556666 |
Ted |
5558888888 |
|
John |
Smith |
Chicago |
2 Pine St. |
5555556666 |
Marie |
5559999999 |
|
John |
Smith |
Boston |
3 Willow St. |
5551112222 |
Ted |
5557777777 |
|
John |
Smith |
Boston |
3 Willow St. |
5551112222 |
Ted |
5558888888 |
|
John |
Smith |
Boston |
3 Willow St. |
5551112222 |
Marie |
5559999999 |
|
John |
Smith |
Boston |
3 Willow St. |
5553334444 |
Ted |
5557777777 |
|
John |
Smith |
Boston |
3 Willow St. |
5553334444 |
Ted |
5558888888 |
|
John |
Smith |
Boston |
3 Willow St. |
5553334444 |
Marie |
5559999999 |
|
John |
Smith |
Boston |
3 Willow St. |
5555556666 |
Ted |
5557777777 |
|
John |
Smith |
Boston |
3 Willow St. |
5555556666 |
Ted |
5558888888 |
|
John |
Smith |
Boston |
3 Willow St. |
5555556666 |
Marie |
5559999999 |
As our JSON example increases in complexity, a vertical JSON flattening approach begins to rapidly increase the number of rows in our data table.
Here’s what happens when we use horizontal JSON flattening instead:
|
employee.first_name |
employee.last_name |
employee.addresses.0.city |
employee.addresses.0.street |
employee.addresses.1.city |
employee.addresses.1.street |
employee.phone_numbers.0 |
employee.phone_numbers.1 |
employee.phone_numbers.2 |
employee.children.0.name |
employee.children.0.phone_numbers.0 |
employee.children.0.phone_numbers.1 |
employee.children.1.name |
employee.children.1.phone_numbers.0 |
|
John |
Smith |
Chicago |
2 Pine St. |
Boston |
3 Willow St. |
5551112222 |
5553334444 |
5555556666 |
Ted |
5557777777 |
5558888888 |
Marie |
5559999999 |
As our JSON example increases in complexity, a horizontal flattening approach begins to widen the table, resulting in column explosion and awkward field names that lead to confusing queries.
The JSON Querying Challenge TL;DR
Indexing JSON logs with nested objects and arrays requires data engineers to flatten the JSON files. But JSON flattening results in an explosion in database size or the necessity of writing complex queries to get value from the data. Or, they treat the JSON objects as strings and miss out on valuable insights.

How Do Enterprises Analyze Nested JSON Today?
Enterprise DevOps, SecOps, and CloudOps teams that utilize JSON logging regularly encounter the nested JSON analysis problem when dealing with complicated JSON logs.
Here’s an example of a typical AWS CloudTrail log that a SecOps team might want to analyze:

AWS CloudTrail monitors account activity on AWS infrastructure and writes logs in structured JSON format. These logs contain a wealth of information that can be analyzed to gain insights into system security and user behavior.
SecOps teams might want to query AWS CloudTrail logs in order to:
- Check the source IP address of authenticated users with root privileges vs. blacklisted IPs (1, 3, 6).
- Check what that user did (5, 7, 8, 9).
- Check any other anomalous behavior in the system around the same time (4).
- Check what other things the root user and the new user accessed (2, 8).
- Check what other things the same user accessed around the same timeframe (2, 4).
The ideal approach would be to fully index these logs, but AWS CloudTrail logs are complex, with nested objects and arrays in multiple levels. Indexing these logs will require JSON flattening, which means either blowing up the size of the data (row explosion) or making the index harder to query (column explosion).
To avoid explosive data growth and complex queries, enterprises instead choose one of two alternative approaches to analyzing nested JSON:
- Data Engineering Approach: Instead of fully indexing complex JSON logs, data engineers can create dedicated data pipelines that pre-process the log data and store only the structured data that is relevant for known analyses.
To prepare a JSON pipeline, data engineers must know the relevant fields for analytics in advance — and anything non-essential will be discarded. In the above example, each question the SecOps team wants to ask requires a dedicated pipeline. That’s a lot of time and work required of data Ops teams. And the need to pre-configure data for analytics means that valuable insights are lost. - Point Search Approach: Point searches allow the SecOps teams to search for specific information in a specific time period within JSON logs — they’re only useful if you know what you’re looking for and where to look for it.
A point search approach might answer the immediate query, but wouldn’t be able to answer the 3rd question above and look for other anomalous behavior in the system around the same time. Just like the data engineering approach, point search reduces the volume of data analyzed and results in lost insights.
Whether choosing the data engineering approach or a point search approach to analyze complex JSON logs, the end result is the same: lost insights that prevent organizations from extracting the full value of structured JSON logs.
Thankfully, there is now a better approach.
How to Get the Most Out of Your Nested JSON Logs
JSON FLEX, a ChaosSearch proprietary technology, solves the Nested JSON Analysis Problem.
JSON FLEX allows customers to process, store, and query JSON as if it were structured at different nested levels — with no data explosion, no complex and unwieldy queries, and no lost insights. Our approach is to maintain the smallest possible data representation at index time, while allowing our users full customization at query time to materialize the data.
Watch this quick demo to learn more:
Here’s how it works:
Chaos Index® detects and indexes JSON automatically, without any configuration from the user. Our proprietary index format supports multi-model data access (search, SQL, and ML) in one representation with unparalleled compression ratios of up to 95%, while maintaining performance.
As a result, our users can store all of their JSON logs in full native format with no costly data explosion and without losing fidelity of insights.

Streamlining the process of JSON flattening with JSON Flex makes it easier for dev teams to support log analytics use cases like user behavior monitoring, security log analytics, optimizing cloud observability, and achieving better CloudWatch log insights.
For users who may not want to index every field in their JSON logs, we deliver two functions that make it easy to customize what gets indexed:
- JSON Include/Exclude - Users can specify a blacklist and/or a whitelist to easily configure which logs will be indexed and which may be excluded.
- JSON Nesting Levels - Users can reduce the combination of nested array expansions to omit irrelevant data and optimize their JSON index for downstream querying.
After indexing and processing JSON logs with Chaos Index, users can explore the data and query JSON logs by creating dynamic virtual views in Chaos Refinery®.
With Chaos Refinery, we give our users complete flexibility to easily customize index views in whatever representation they choose, even switching between vertically and horizontally flattened views depending on what makes sense for each query.
ChaosSearch Array Shaping even allows users in Chaos Refinery to choose vertical flattening for arrays that are relevant to a specific query while keeping the rest in horizontal format. These decisions are maintained in ChaosSearch’s lightweight views representation and materialized at query-time with no need for re-indexing.
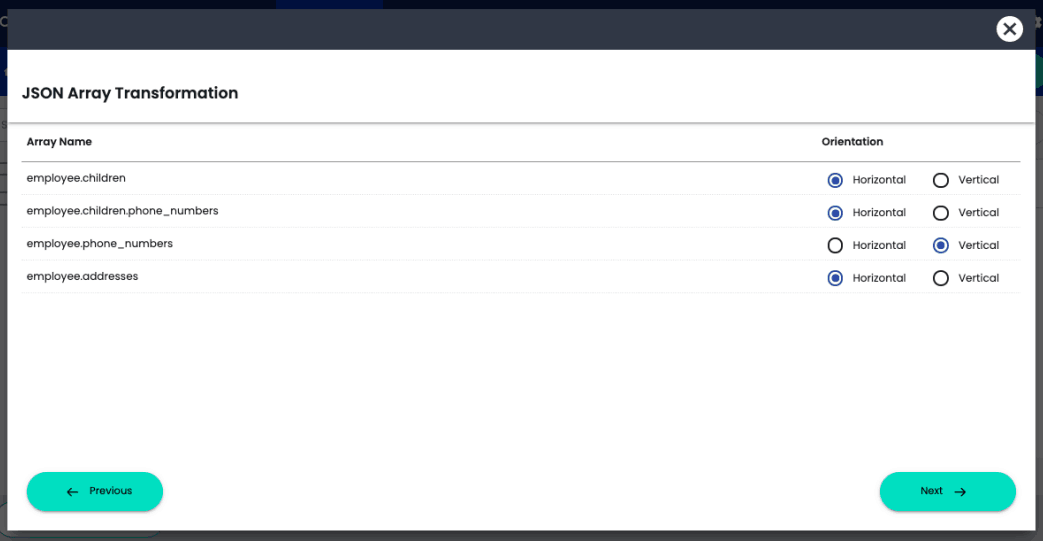
JSON array transformation with ChaosSearch Array Shaping in Chaos Refinery
With JSON FLEX, ChaosSearch users can fully index and analyze even the most complex JSON logs with no explosive data growth, no unwieldy queries, no trade-offs, and no lost insights.
Unlock the Full Potential of JSON Logging
You’re just minutes away from experiencing the seamless flexibility of JSON FLEX and unlocking the full potential of structured JSON logging. Here’s what to do next:
- Register for our free trial experience
- Start landing JSON structured logs in your own cloud storage buckets
- Use ChaosSearch to index and analyze structured JSON logs at scale with no data explosions, no data movement, no re-indexing, no trade-offs, and no compromises.
Want to learn more?
View our free on-demand webinar Unlock JSON Files for Analytics at Scale in ChaosSearch to see JSON Flex in action!

Additional Resources
View Documentation: JSON Flex Behavior Summary (Behaviors and Advantages)
Read the Blog: Log Analytics 2023 Guide
Download the White Paper: Ultimate Guide to Log Analytics: 5 Criteria to Evaluate Tools

