

Javascript Object Notation (JSON) is becoming the standard log format, with most modern applications and services taking advantage of its flexibility for their logging needs. However, the great flexibility for developers quickly turns into complexity for the DevOps and Data Engineers responsible for ingesting and processing the logs. That’s why we developed JSON FLEX: a scalable analytics solution for complex, nested JSON data. JSON FLEX® empowers enterprise CloudOps, security, data engineers, and business analysts with powerful new tools for extracting data from complex JSON files/events.
Watch this quick demo to learn more:
In our blog this week, we’re giving readers an insider’s look at our JSON FLEX® capabilities. Keep reading to discover just how simple it is to flexibly process, store and analyze JSON data.
Getting Started: Introduction to JSON CloudTrail Logs
Let's take AWS CloudTrail logs for a JSON file structure example: CloudTrail is the audit trail of AWS, and any action you take over the AWS console or via API will be recorded on CloudTrail. That’s why it is a key resource to better monitor changes in your AWS accounts, investigate anomalous actions or trace a cyber attack against your environment.
AWS CloudTrail writes logs in JSON format and periodically generates JSON log data with specific characteristics. JSON supports two well-known data structures: key value pairs (called objects) and ordered lists of values (called arrays). Each JSON event consists of a single array at the root called “Records,” where each element in the array is a record of either a Management Event or a Data Event on AWS.
Each record is a JSON Object consisting of multiple key value pairs with information about the event, but you’ll also see inner elements within each record, such as Nested JSON Objects and Nested Arrays.
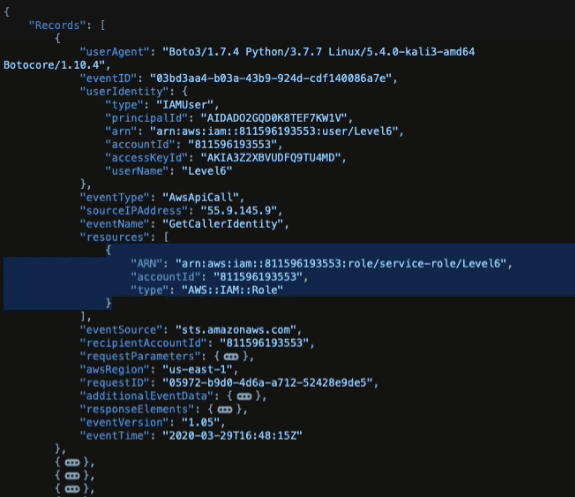
Nested structure of CloudTrial log file
Records in CloudTrail log files include nested JSON objects and nested arrays. To properly store and analyze JSON data, some sort of flattening technique is necessary to expand the arrays and convert it to a tabular format.
WATCH: How to Tame Your Cloud Service Logs
JSON Flattening: The Key to Analyzing Complex JSON Logs
There are two ways to flatten JSON documents, each having their own advantages and trade-offs. In this section, we'll talk about Vertical and Horizontal flattening. Flattening levels will be discussed in the next section.
Vertical Flattening creates a new row for every value in an array. This makes it possible to query the data, but it also means that each log will occupy many rows within the table instead of just one. In this way, vertical flattening tends to multiply the size of the data, which can increases index or query time and data storage costs.
Horizontal Flattening creates a new column for each value in an array. This type of JSON flattening results in faster indexing and queries but can also lead to column explosion (having too many columns of data, even up to the software limit), which makes it difficult to write proper queries.
Flattening JSON into a tabular format is necessary for enabling data analysts to work with JSON, but both vertical and horizontal flattening can lead to unacceptable outcomes such as high storage costs or querying difficulties. Plus, not all data fields are important for every analysis, so it isn’t always necessary to flatten every array or nested object within a record.
What enterprise DevOps teams need is a flexible solution that provides a range of options for flattening JSON as needed based on the specific use case. Let’s take a closer look at four ways to analyze complex JSON files like this one using JSON FLEX.
4 Ways to Analyze Complex Log Events with JSON FLEX
1. Selectively Flattening JSON Logs on Ingest
When it’s time to index log data, administrators can control JSON flattening with the parameter “Array Flattening Depth” in the ChaosSearch console. Administrators can decide whether or not to flatten the arrays and also choose the flatten depth.

Selective flattening JSON array configuration
Next, administrators can choose between horizontal or vertical flattening, indicating whether they want to expand the arrays into columns or rows, according to the analysis requirements and use cases, as well as the flattening level (i.e. depth). A level of None treats the entire object as a string where Regex and JPath transformations can be description on views within the Chaos Refinery®.
Additionally, ChaosSearch provides the ability to define and upload a schema filter (JSON file), with granular field processing options.
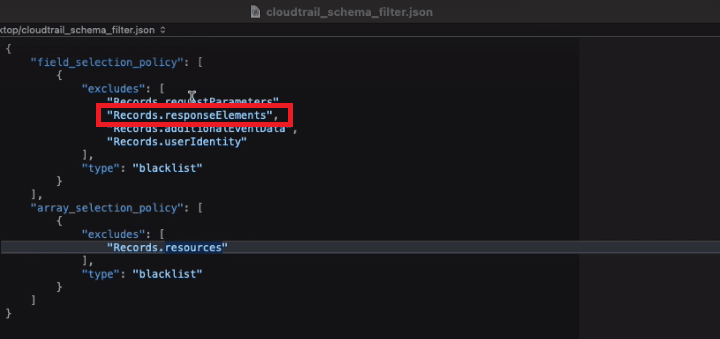
Schema filter example
Schema filters provide a level of customization that goes beyond simply choosing an array flattening depth. They allow administrators who work with JSON to choose exactly which fields, arrays, or nested JSON objects will be expanded at index time and which may be kept as a string (data type that stores a sequence of characters).
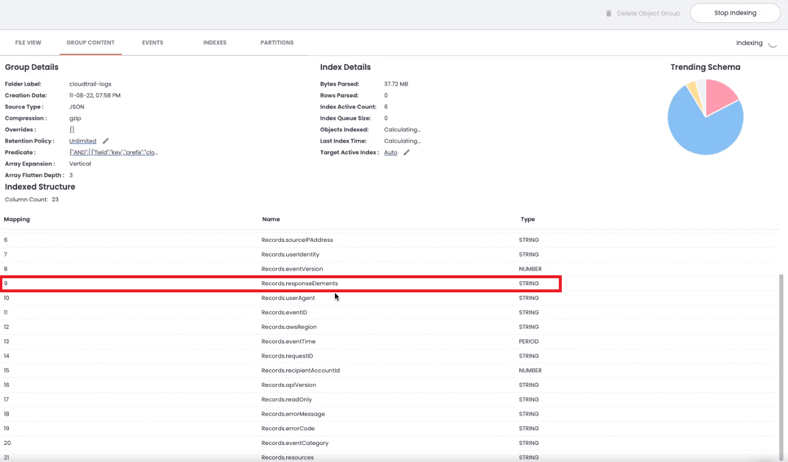
JSON array indexed as a string example
Once a schema filter is uploaded and applied to the log data, the white/blacklisted fields or arrays will be kept as a string instead of being expanded. This allows administrators to get access to the data they need from logs while minimizing column/row explosion that can result from JSON flattening at index time.
2. Virtually Flattening JSON Arrays in Chaos Refinery®
After your JSON log data is indexed, you may want to change how certain data fields are flattened to unlock more analytical flexibility. Chaos Refinery gives users the flexibility to expand arrays virtually using either vertical or horizontal expansion using Views.
With Chaos Refinery, you can create multiple virtual Views that point to the same indexed data, but have their own customized array expansion strategy. Views allow data analysts to freely manipulate the complex data structures of JSON files to support any particular analytics needed without having to change, move or duplicate the indexed data.
3. Materializing JSON Fields in Chaos Refinery
A third option for analyzing complex JSON at scale is to virtually flatten JSON logs by applying transformation on specific fields using Views in Chaos Refinery®.
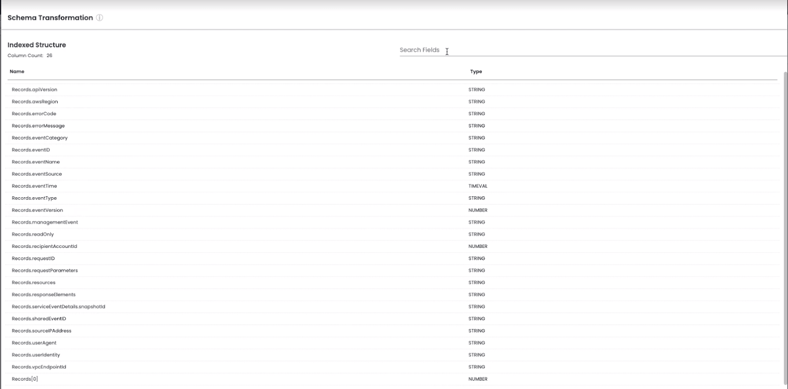
Creating a Virtual View in Chaos Refinery
Refinery gives you several transformation options to change data types/schema and extract values from ingested data.
For this example, we’re going to materialize data from the “Records.userIdentity” field that was kept as a string instead of expanding during ingestion.
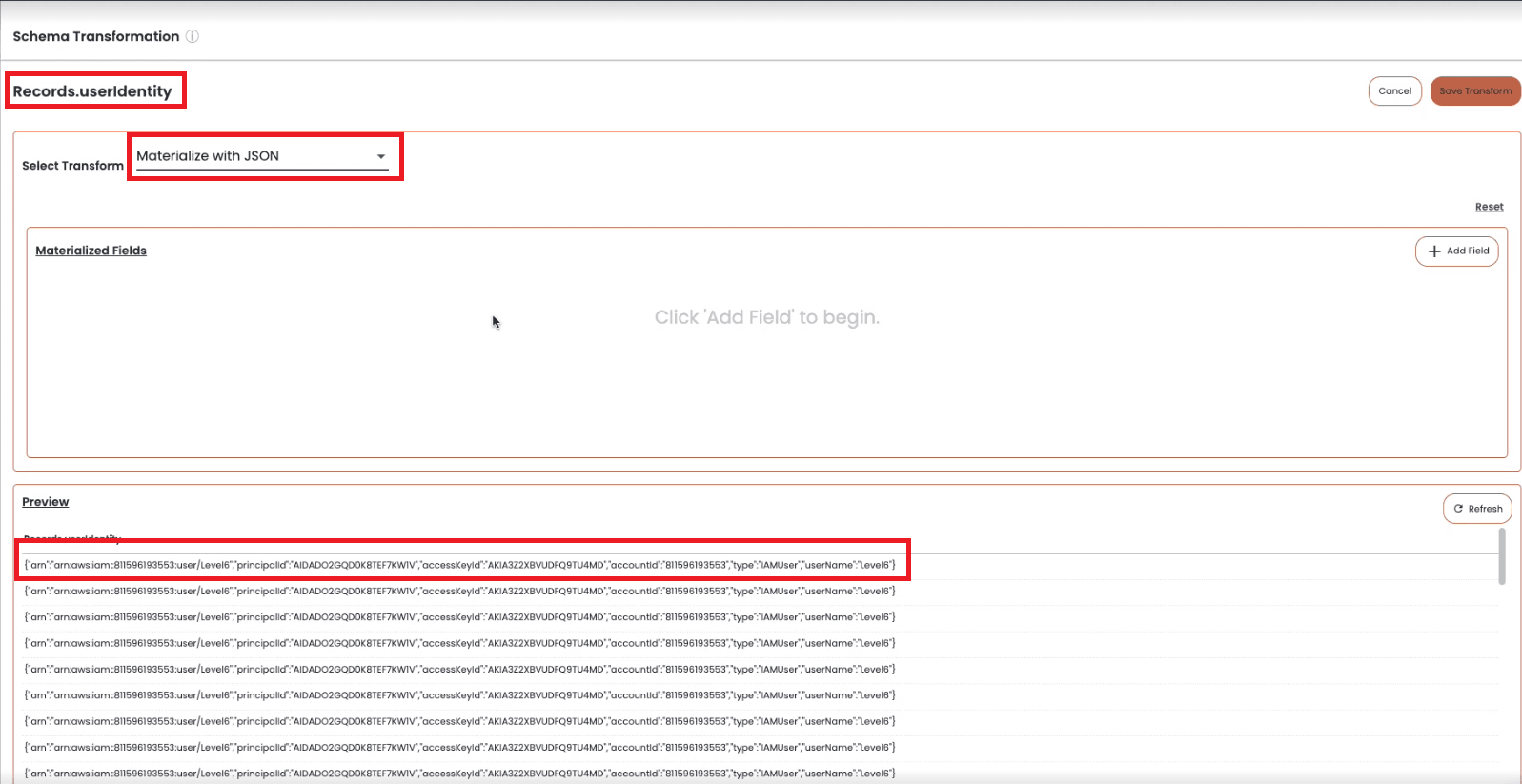
The Records.userIdentity field, a JSON Object saved as a string, contains multiple data fields that we can materialize with Chaos Refinery.
For fields containing JSON objects or arrays in particular, administrators can use standard JSON Path syntax to extract values, objects, or entire arrays, and materialize new fields.
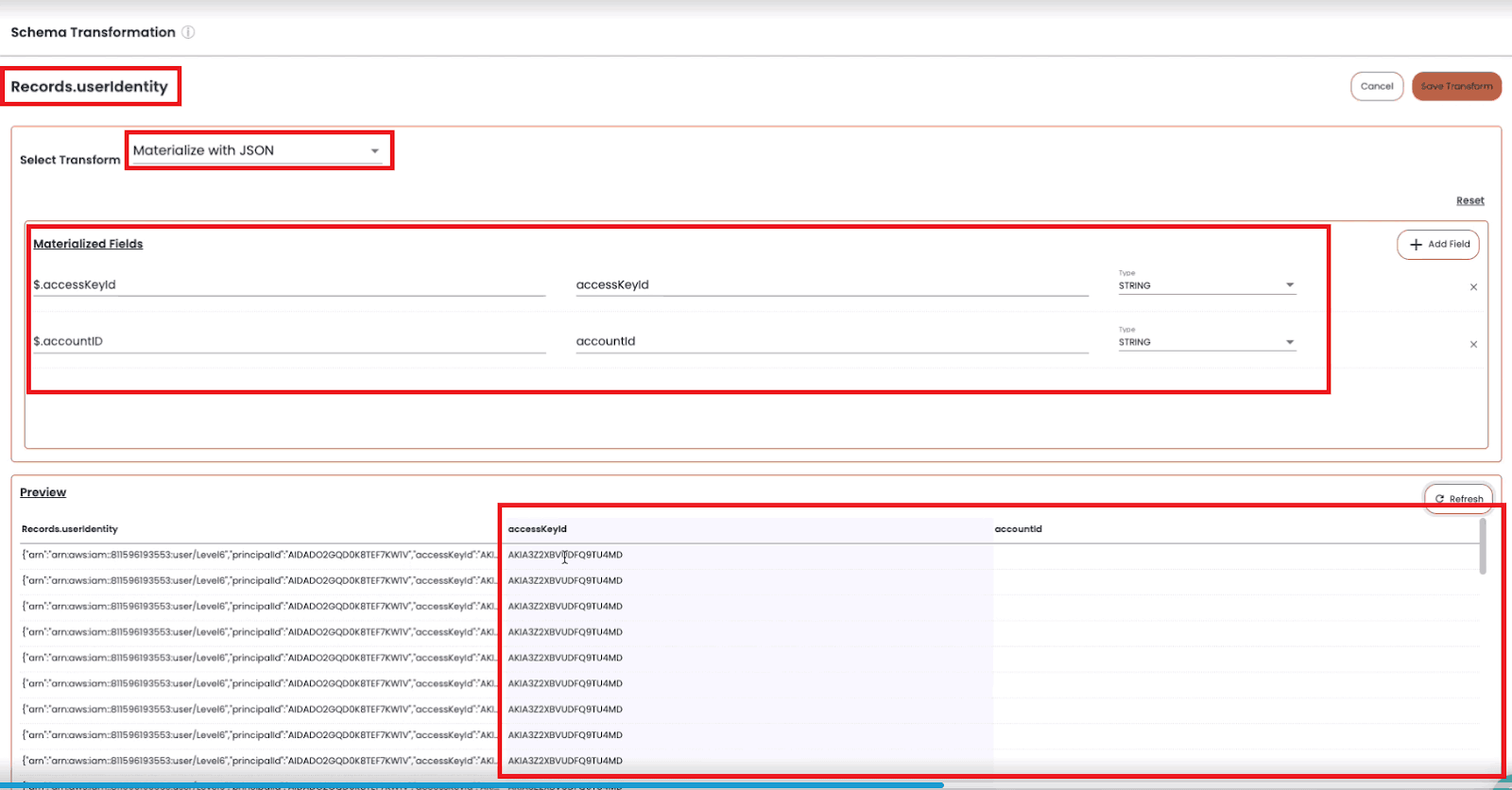
Materialize fields with JSON transformation
Materializing JSON data in Chaos Refinery doesn’t duplicate the data - instead, we’re creating data columns that will behave as any other field but that only exist virtually when it’s time to query. Chaos Refinery will provide these transformations on the fly whenever we access this View for querying.
4. Accessing JSON Fields for Analysis in Kibana
Our fourth option to store and analyze JSON data is to access values inside fields containing JSON objects or arrays as a string, through a query syntax. This is especially useful when the content doesn't follow a specific pattern and when flattening or expanding the data is not a viable option (to avoid row/column explosion) - see this in the example below:
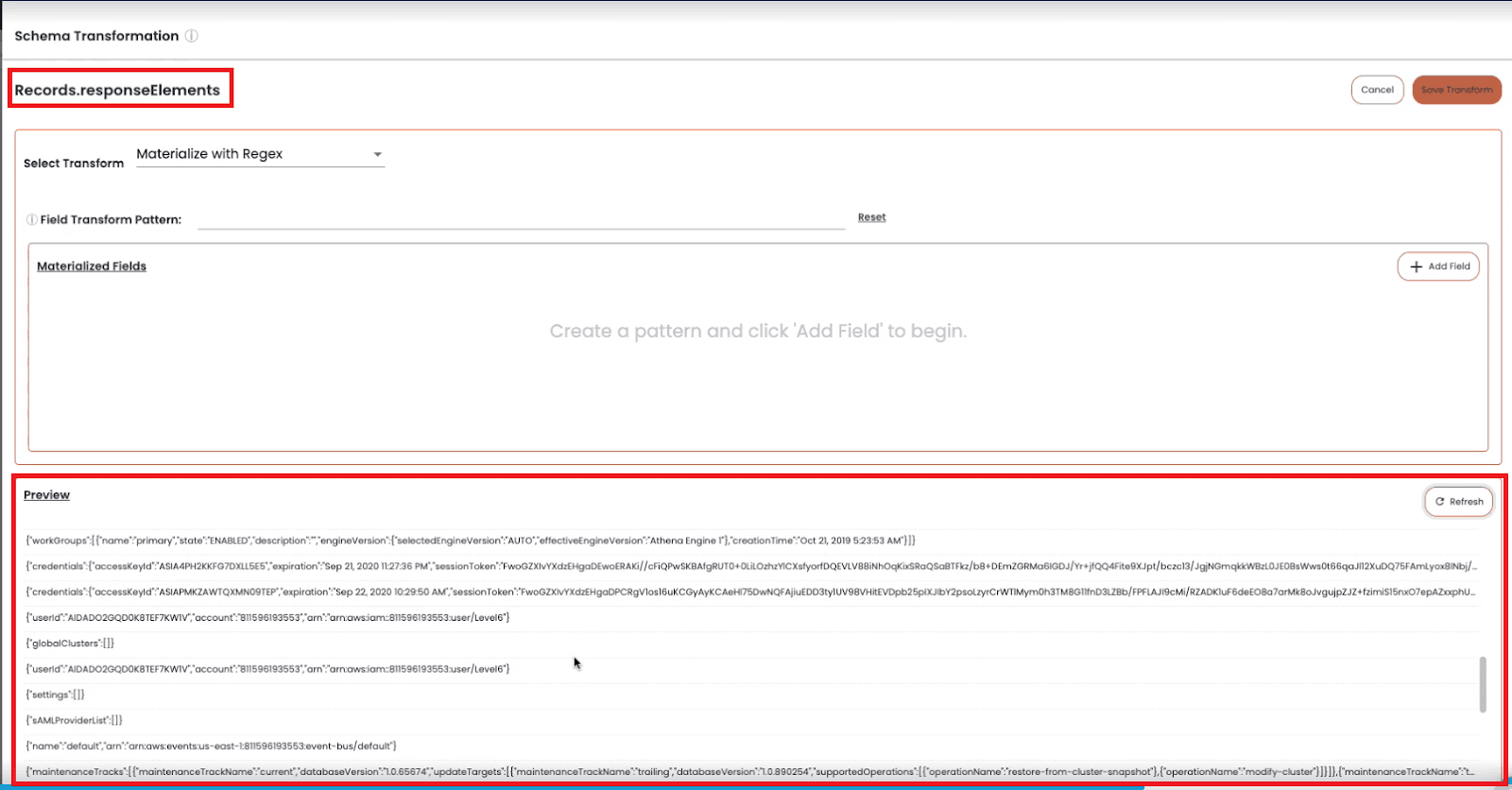
Chaos Refinery transformation
To get started, we have to apply a transformation to the data field called “Treat as Nested JSON”:
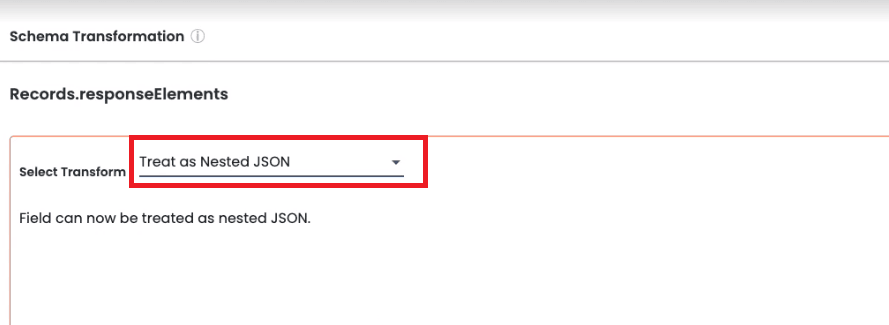
Treat as Nested JSON transformation example
Choosing to treat a data field as Nested JSON keeps the data saved as a string but gives the user an option to get values from the data field by using a special syntax at query time. Once the transformation has been applied, we can create a View where the data field is treated as nested JSON:
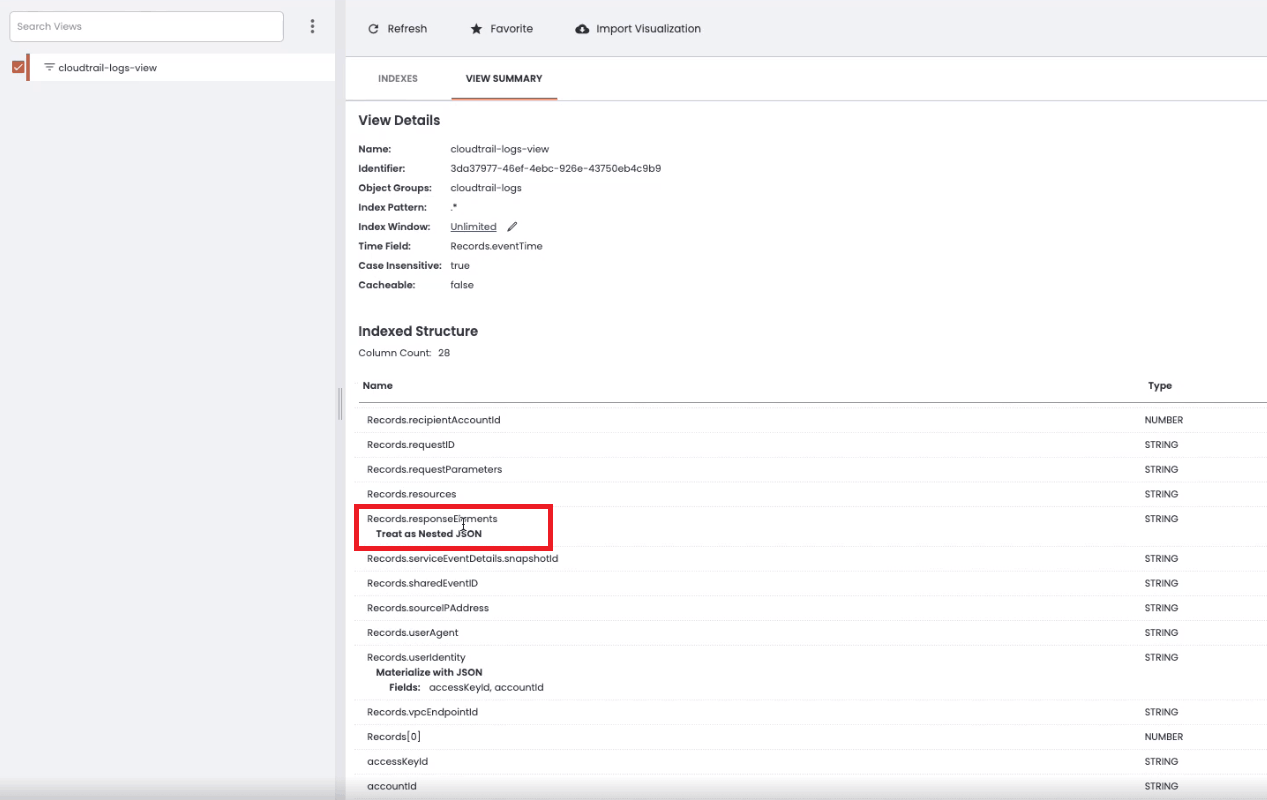
Chaos Refinery View
Once we open Kibana and examine the data, we can use the Elastic Nested Query Syntax to query elements or fields that are saved as a string inside our nested JSON object.
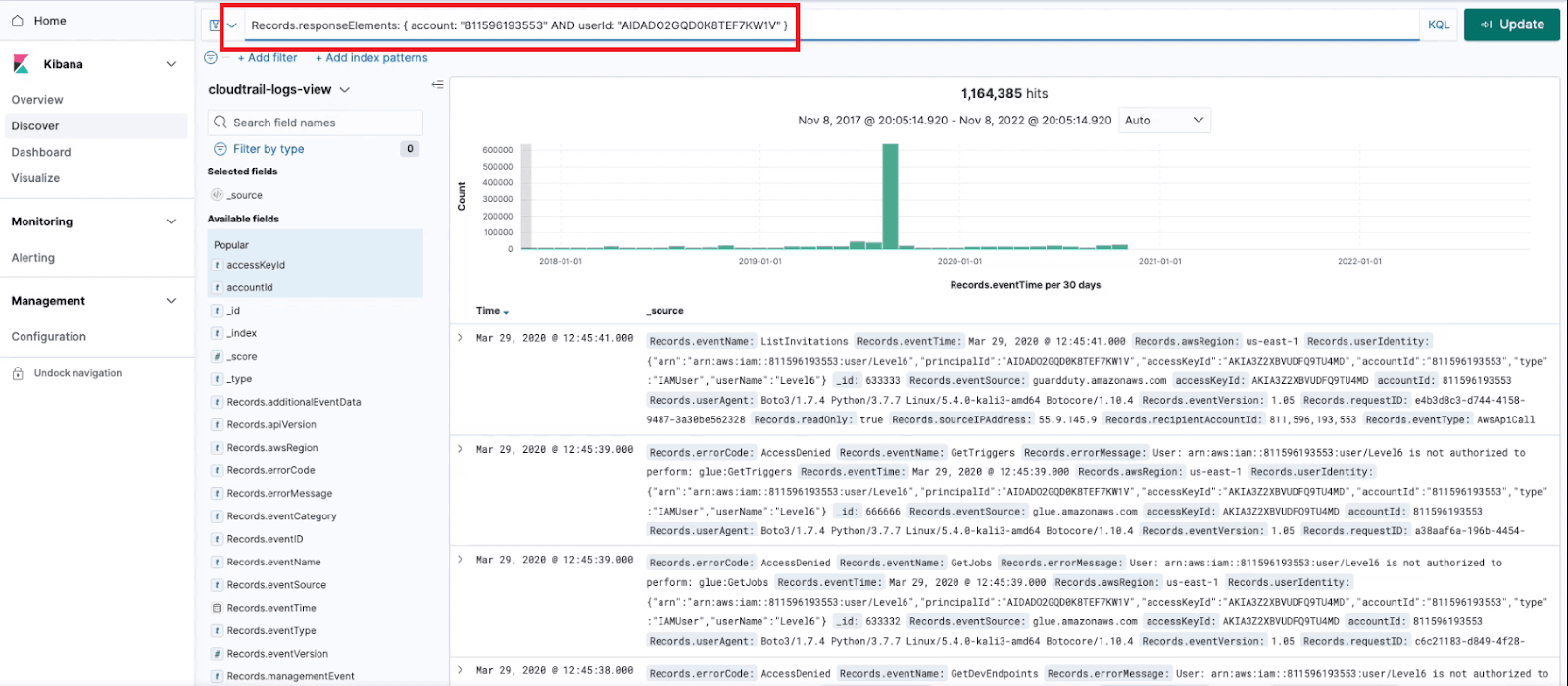
Nested JSON array query
This type of querying makes it possible for analysts to access data fields inside nested JSON objects, but without the additional cost and complexity that would result from completely flattening the nested JSON. The ability to extract data fields at query time also reduces the number of unique Views that must be created and managed in Chaos Refinery to support data analytics use cases.
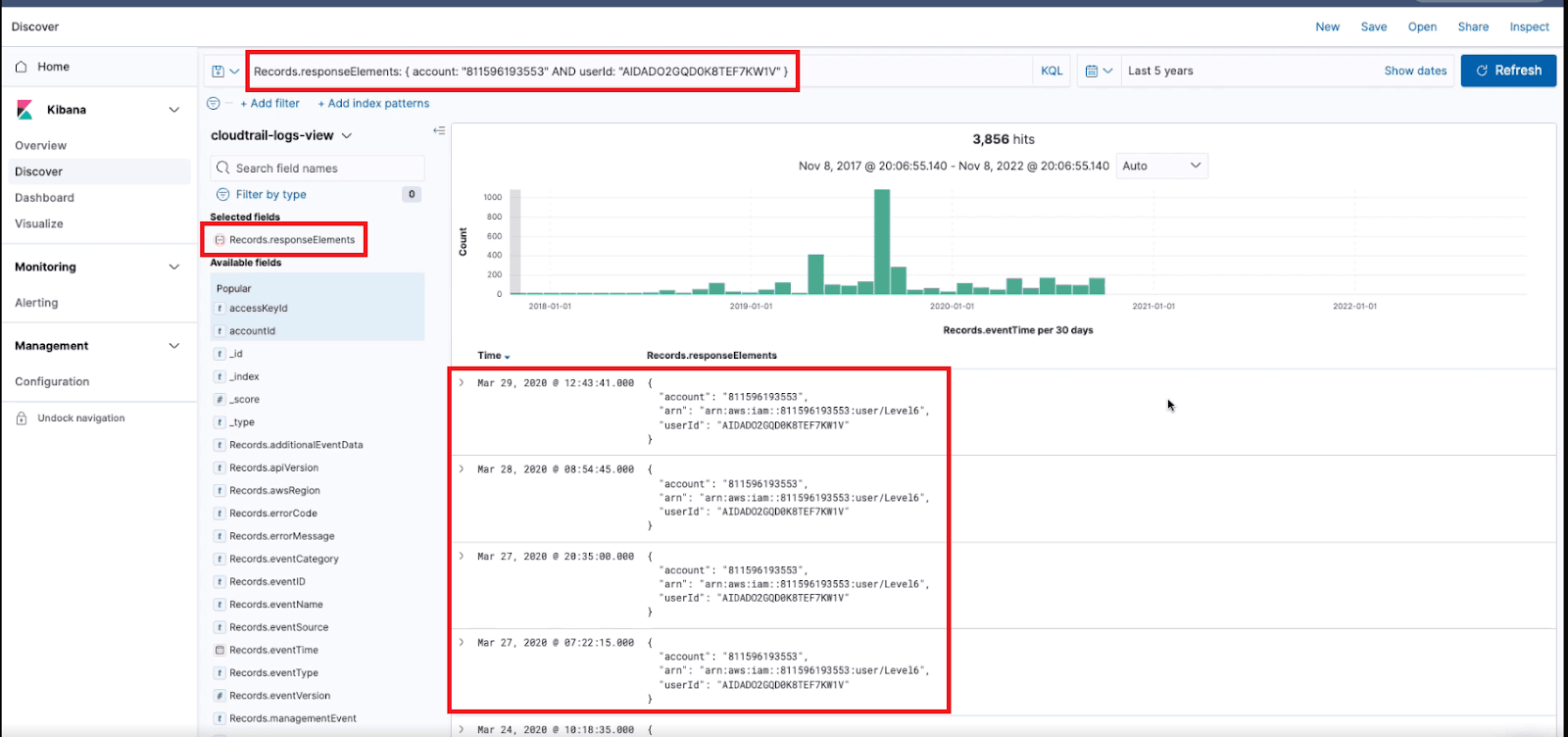
Nested JSON array query
READ: How to Create a Dashboard in Kibana
Analyze Complex JSON Logs with ChaosSearch
ChaosSearch delivers four capabilities that will revolutionize how our customers store and analyze JSON data. The four abilities include:
- Selectively flattening complex JSON at index time with Chaos Index®
- Flattening complex JSON as a virtual transformation in Chaos Refinery
- Materializing data from unflattened data fields in Chaos Refinery
- Extracting data fields from complex JSON logs at query time using standard JSON query syntax
JSON FLEX gives enterprise DevOps, security, and data engineering teams unprecedented flexibility to index and analyze complex JSON logs while mitigating the row/column explosion that often results from JSON flattening and optimizing the use of storage and compute resources.
Ready to learn more?
Start Your Free Trial of ChaosSearch and discover how easy it is to connect our data lake platform to your Amazon S3 and begin to store and analyze JSON data more efficiently with JSON FLEX capabilities.
Or, check out the official documentation for our JSON FLEX Processing capabilities to learn more about how ChaosSearch solves JSON file indexing and querying to enable business analytics.
Additional Resources
Read the Blog: How to Index and Process JSON Data for Hassle-free Business Insights
Watch the Video: Unlock JSON Files for Analytics at Scale in ChaosSearch
Read the Blog: 5 AWS Logging Tips and Best Practices
Check out the Whitepaper: DevOps Forensic Files - Using Log Analytics to Increase Efficiency

