

Data retention policy continues to be a major focus for CIOs in 2023. Here’s why:
First, enterprise organizations are producing larger volumes of data than ever before and utilizing enterprise data across a wide range of business processes and applications. To maximize its value, this data must be managed effectively throughout its entire life cycle - from collection and storage, through to usage, archiving, and eventually deletion.
As the volume, variety, and velocity of big data increases, cost-conscious organizations must be more selective about which data is retained, where it will be stored, and for how long. An effective data retention policy ensures that data is available for its intended applications, stored in a cost-effective way across its entire life cycle, and properly destroyed when it is no longer needed.
Second, lawmakers are continuing to introduce regulations that create new data retention obligations for enterprises operating in jurisdictions around the world. These include the data retention requirements in the European GDPR and industry-specific data retention requirements in the HIPPA Act. An effective data retention policy is necessary to ensure ongoing compliance with data security, privacy, and retention laws that apply to your organization.
In this week’s blog post, we’re taking a closer look at the importance of data retention policies and how organizations can create and implement a data retention policy that supports key business processes and compliance objectives.

What is Data Retention?
Data retention is the practice of storing, archiving or otherwise retaining data to support internal business processes (e.g. analytics, auditing) and/or comply with external laws/regulations.
Data retention can be understood in the context of the data management lifecycle, a model or roadmap for enterprise data utilization. This model has been described in different ways by various publications, but here’s our simplified version:
- Data Creation - Data is generated in the course of doing business.
- Data Storage - Data is collected and stored by the organization in structured, unstructured, or semi-structured format.
- Data Usage - Data is cleaned, transformed, and normalized before it can be analyzed. From there, the data may be analyzed to extract insights that can inform business or technical decision-making. Analysts may create visualizations or dashboards to communicate insights to executive decision-makers.
- Data Archiving - Data is retained for future use in business processes or to comply with data retention laws.
- Data Destruction - Data is deleted or destroyed when it is no longer useful to the organization, and/or to comply with data retention laws.
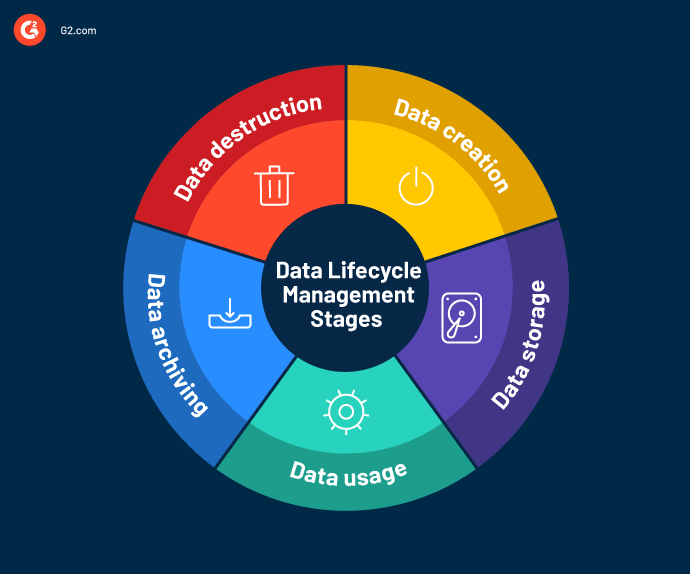
Through the practice of data retention, organizations manage the activities of data archiving and data destruction in accordance with their business needs and objectives, and regulatory requirements. This includes determining which data should be retained, where it should be stored, how long it should be kept, and when/how to delete the data after the data retention period.
What is a Data Retention Policy?
A data retention policy is a document that establishes requirements and guidelines within an organization for archiving, retaining, and destroying enterprise data. The policy should clarify questions such as:
- What categories or types of data are generated by the organization?
- Which departments or managers are in control of which data?
- What are the regulatory requirements (for every jurisdiction) for retaining each type of data?
- Where/how should data be stored, archived, or retained?
- How long should data be retained by the organization?
- When/how should data be destroyed by the organization?
An effective data retention policy ensures that:
- Data is available and accessible when needed for internal business processes, such as analytics, reporting, or financial auditing.
- Data is stored in the most cost-effective format based on its intended purpose and how frequently it will be accessed.
- Data is retained for the appropriate time frame as required by law.
- Data is deleted or destroyed when it is no longer needed by the organization, or as required by law.
To achieve its intended purpose, a corporate data retention policy should account for the people, processes, and technologies required to ensure that enterprise data is archived and destroyed as needed to meet the organization’s business objectives and legal obligations.
Next, we’ll outline our seven-step process for creating and implementing a data retention policy within your organization.

How to Create a Data Retention Policy
1. Identify Key Data Owners
Data is often siloed in departments, such that the sales team has ownership of sales data, the accounting department owns financial data, the HR department owns staffing data, the IT department owns log data, and so forth.
Creating a data retention policy begins with identifying key data owners within your organization, getting their buy-in, and assembling a project team that represents all data owners. Each department or data owner will be responsible for managing their data in compliance with the data retention policy, so it’s important to get everyone involved in the process and communicate the importance of data retention policy to all internal stakeholders.
2. Inventory and Categorize Your Data
The next step in creating your data retention policy is to comprehensively inventory your data. Make a list of all types of data generated by your organization. When your list is complete, sort the data into categories based on where the data is generated or its intended use.
Some common categories of enterprise data could include:
- Staffing Data (e.g. employee earnings, commissions, medical records)
- Payroll Data (e.g. time cards, payroll deductions, pension records)
- Transactional Data (e.g. purchases, invoices, payments)
- Event Log Data (e.g. application logs, system logs, security logs)
- Credit Card Data (e.g. Primary Account Number (PAN), cardholder name, service code)
- Insurance Data (e.g. policies, releases and settlements, claims)
- Project Documents (e.g. reports, correspondence, images)
- Corporate Data (e.g. annual reports, committee minutes, board minutes)
Each category of data you identify may be subject to different data retention laws and business requirements. To account for this, you’ll need to conduct research and implement individualized data retention policies for each type of data your organization collects.
3. Investigate Data Retention Laws for Each Data Type
Once you have identified and categorized your enterprise data, the next step is to determine whether your data is subject to any regulatory or legal requirements with respect to data retention and preservation.
For each category of data, you’ll need to ask:
- What data retention laws and regulations apply to this data?
- What are the specific data retention requirements for this data?
- Where/how should the data be stored or archived, and for how long?
- What should happen to the data after the legally mandated retention period?
Whether your organization is subject to data retention laws will depend on your industry, the types of data your organization collects, and the jurisdictions where your business collects data. For example:
- The Healthcare Insurance Portability and Accountability Act (HIPAA) is a US federal law that governs the privacy of Personal Health Information (PHI) in the United States. Under HIPAA, enterprises that collect PHI in the US must retain PHI for a minimum of 6 years from when it was created.
- Many states have legally mandated data retention requirements for PHI that go beyond the requirements of HIPAA. One third of US states require enterprises to retain PHI records for at least 10 years.
- The Payment Card Industry Data Security Standard (PCI DSS) was launched in 2004 by Visa, Mastercard, Discover, and American Express to protect the personal information of credit card users. Under the PCI DSS, enterprises who collect credit card data from customers must establish secure databases and systems to safeguard the data (e.g. names, birth dates, credit card numbers, etc.). They’re also required to implement automated audit trails of user access to sensitive data, to retain those audit logs for at least a year, and to keep ninety days of logs available for immediate audit or review.
- The European General Data Protection Regulation (GDPR) requires enterprises that collect personal data from customers inside the European Union to establish a clear purpose for the data collection and to retain data only until that purpose has been fulfilled. Under the GDPR, enterprises can establish their own data retention periods depending on the type of data, but may not store data indefinitely.
Enterprises in the United States may also be required to preserve financial and tax records, personnel records, emails, and workplace safety data in compliance with US law.

This image indicates legally mandated periods for email retention in the United States. Contractors with the US DOD are subject to a 3-year email retention mandate, while the IRS requires all businesses to retain every record (including emails) related to finance and personnel for 3 years after the tax season.
Enterprises can document the results of this regulatory compliance needs assessment, along with specific data retention requirements, using a simple spreadsheet. Here’s how this might look for a data category we’re familiar with: event log data.
Compliance Needs Assessment Template
|
Data Category |
Compliance Requirements |
Affected Data Types |
Storage Location |
Data Retention Period |
Data Disposal Policy |
|
Event Log Data |
Application, security, and user logs from systems containing ePHI. |
Amazon S3 Cloud Storage |
6 years |
Delete |
|
|
Event Log Data |
Application, security, and user logs from systems containing ePHI. |
Amazon S3 Cloud Storage |
10 years |
Delete |
|
|
Event Log Data |
Security and access logs from systems containing PII. |
Amazon S3 Cloud Storage |
1 year |
Delete |
"Due to the nature of the data that we work with, student educational records, we need to retain all data and log files for 10 years after their creation to comply with our most stringent client retention policies"
- Jimmy McDermott, CTO at Transeo Read the Transeo Case Study

4. Conduct a Business Needs Assessment for Each Data Type
Once you have analyzed and documented regulatory requirements for data retention within your enterprise, you can move on to conducting a business needs assessment for each category/type of data you collect.
Here, the goal is to identify which data should be stored or archived because it supports a business use case.
For each data category, you’ll need to ask:
- Which internal business processes or use cases require us to retain data?
- Which categories/types of data must be retained to support those use cases?
- Where should the data be stored/archived?
- How long should the data be retained, and what should happen after the data retention period?
Enterprises can and should retain event log data from applications and cloud services to support long-term log analytics use cases, such as:
- Application Performance Monitoring - Retaining application event logs helps DevOps teams monitor long-term trends in application performance and target improvements or optimize resource allocation to improve the customer experience.
- Security Operations and Threat Hunting - Building a security data lake for long-term use cases can augment short-term security analytics solutions like Splunk. For enterprise SecOps teams, retaining security data from applications and network infrastructure enables long-term analytics use cases, such as root cause analysis of security incidents and Advanced Persistent Threat (APT) hunting.
- Monitoring Health of Cloud Services - Preserving cloud service logs can provide DevOps teams with a long-term view of cloud infrastructure health and drive improvements that enhance the performance of cloud services and/or reduce operational costs.
As you complete this assessment, you will develop an understanding of how your organization is utilizing its data. You may even uncover some new and valuable use cases for the data you’re already collecting. The results of your business needs assessment, including specific data retention requirements for each data category/type, can be documented in a spreadsheet like the one below.
Business Needs Assessment Template
|
Data Category |
Business Use Cases |
Affected Data Types |
Storage Location |
Data Retention Period |
Data Disposal Policy |
|
Event Log Data |
Security Operations and Threat Hunting |
Security Event Logs |
Amazon S3 Cloud Storage |
1 year |
Delete |
|
Event Log Data |
Application Performance Monitoring |
Application Event Logs |
Amazon S3 Cloud Storage |
90 days |
Delete |
|
Event Log Data |
Cloud Service Monitoring |
Cloud Service Logs |
Amazon S3 Cloud Storage |
90 days |
Delete |

5. Write a Data Retention Policy for Each Data Type
At this point, you’ve categorized all of your enterprise data and investigated business use cases and regulatory compliance requirements for each data type. Based on the information you found, you’ve determined where the data should be stored, how long it should be retained, and if/when it should be destroyed.
Now you can start finalizing data retention policies for each type of data you collect.
Your data retention policy for each data type should include the following:
- Data Type/Category
- Data Owner - The role/individual responsible for managing this data in compliance with the retention policy. Some or all data types in the same category may have the same data owner.
- Data Storage Location - The storage location for the data, e.g. On-prem servers, AWS or GCP cloud object storage, etc.
- Data Retention Period - The required retention period for the data, based on your policy/business needs assessment.
- Data Disposal Policy - A disposal policy for the data, indicating whether it should be archived or destroyed at the end of its lifecycle.
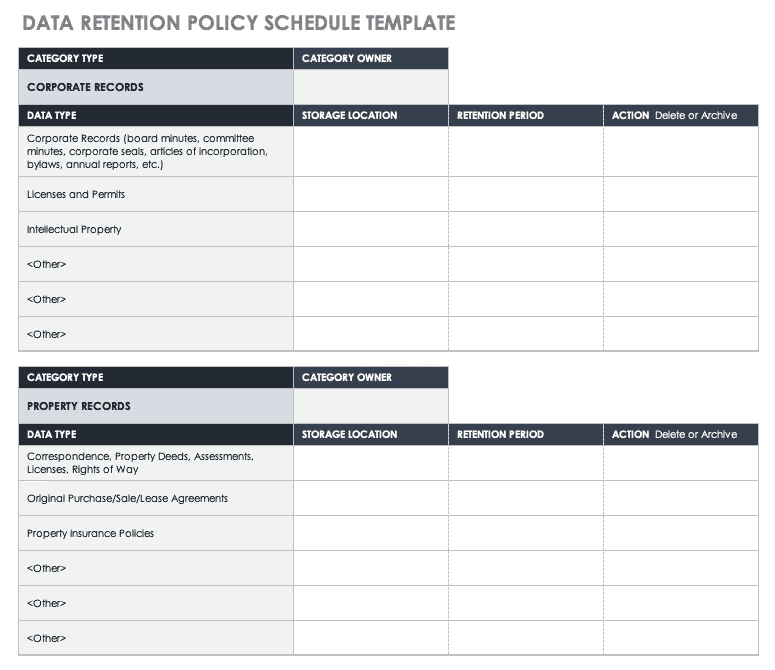
This data retention policy example/template indicates the data owner, data category and record type, storage location, data retention period, and whether to archive or delete the data after the retention period expires.
Your data retention policy should also include general guidelines for things like revision histories and policy exemptions, as well as a communication plan for data retention issues. You may also want to document a plan for enforcing compliance with your data retention policy.
6. Establish SOPs for Retaining, Archiving, and Destroying Data
Standard operating procedures (SOPs) describe the processes and technologies that your organization will use to store, retain, archive, and destroy data in compliance with your documented data retention policy. Data retention policies may be executed by human operators or automated using software technology and services.
Public cloud vendors like AWS offer services that help organizations automate their data retention policies in the cloud. Two examples are Amazon S3 Intelligent Tiering, which automatically transfers data between cost-optimized storage tiers based on user access patterns, and Amazon S3 Object Expiration, a feature that makes it easy for data owners to schedule the deletion of data objects in S3 buckets.
New technologies like ChaosSearch can also be used to support a cloud data retention policy. ChaosSearch is a cloud data platform that uses a proprietary indexing technology to greatly reduce the amount of storage required in S3 for a full, searchable representation of data, eliminating the need for additional data movement. ChaosSearch also has its own data retention features that can be used to augment your existing S3 retention policies and automation.
The ability to index, search, and analyze log data at scale with ChaosSearch means that organizations can retain their log data for longer periods while fully realizing its value through applications like security monitoring and cloud log analysis.
7. Implement Your Data Retention Policy
At this point, you should have everything in place to successfully implement your data retention policy. As the final step, you’ll need to implement your data retention policy and work to ensure compliance throughout your organization.
You’ll need to communicate the new policies and expectations to department leaders and their teams, ensure that data owners understand any new responsibilities, explain the importance of compliance, implement any new processes or technologies required to support your data retention strategy, and provide additional training as needed.
Depending on the size of your organization, implementing your data retention policy can take years. We recommend focusing on your biggest compliance priorities first and finding quick wins that can help energize stakeholders and sustain momentum as you work through the implementation process.
READ: Why Log Data Retention Windows Fail to discover the importance of adopting data storage and analytics solutions that can fully support your data retention needs.
A Final Word on Enterprise Data Retention
Data retention is a growing challenge for organizations facing competitive pressures to maximize the value of their data and regulatory pressures to comply with a growing number of laws surrounding data retention, privacy, and security.
By implementing a comprehensive data retention policy, backed by cost-efficient data storage and analytics solutions, organizations can achieve compliance with local and international data retention laws and regulations, maximize the availability of data to support internal business processes, and reduce data storage/analytics costs.
Ready to learn more?
View our free on-demand webinar A New Approach to Big Data Analytics to discover how enterprises can overcome data retention challenges to achieve long-term visibility of application performance and security without ballooning costs.


