

Organizations are building data lakes and bringing data together from many systems in raw format into these data lakes, hoping to process and extract differentiated value out of this data. However, if you’re trying to get value out of operational data, whether on prem or in the cloud, there are inherent risks and costs associated with moving data from one environment to another. Businesses continuously move data from cheap temporary storage to siloed databases and data warehouses for critical analytical workloads. As part of this movement, companies will ETL (Extract, Transform, Load) this data between environments, all the while 'cleaning and/or preparing' it to be put into a more usable format/solution.
Let’s take a look at why data movement is so prevalent with cloud databases, and some alternative approaches to searching your cloud-based data without data movement.

Why data movement is so prevalent in cloud data platforms
Data movement is ultimately a product of legacy systems that never fully went away. Driven by the increasing number of applications (or data sources), databases and data models in use, data warehousing solutions emerged. These tools work to extract data from transactional or operational systems, transform it into a usable format, and load it into business intelligence (BI) systems to support analytical decision-making activities (a process otherwise known as ETL).
Because data warehouses follow a schema-on-write approach, data must have a defined schema before writing into a database. As a result, all warehouse data has been previously cleaned and transformed (usually by a data scientist or data engineer in the ETL process). When a BI user accesses the data warehouse, they’re actually accessing processed data (rather than raw data). The problem with this approach is that data has been transformed for a predetermined use case. This prevents users from asking questions of their data in different ways to reveal new information. Each new analytics request starts the ETL process over again, resulting in slower time to insights.
Today, instead of a traditional data warehouse, many organizations use cloud object storage like Amazon S3 or Google Cloud Storage (GCS) to store large quantities of data (or big data). Why? Unlike traditional databases that store relational data in a structured format (rows and columns), platforms like Amazon S3 object storage use a flat, non-hierarchical data structure that enables the storage and retention of enormous volumes of unstructured data.
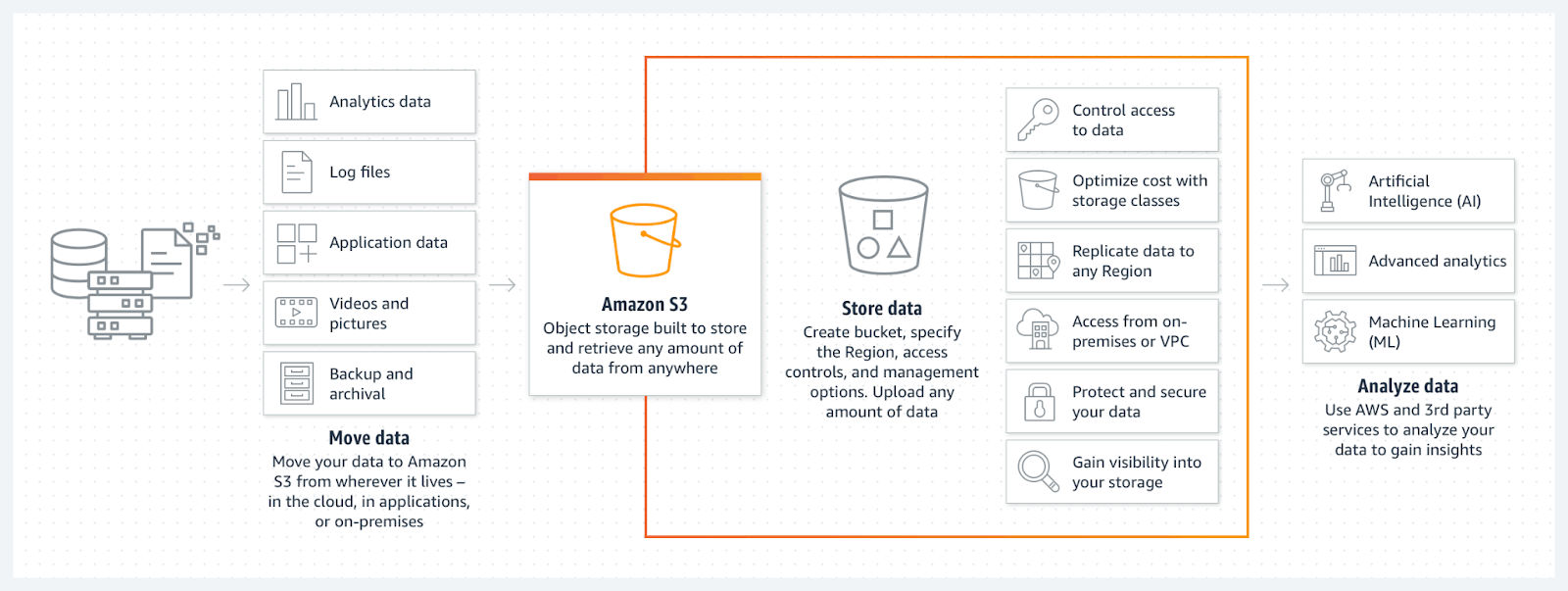
With Amazon S3 object storage, AWS customers can aggregate structured and unstructured data from a variety of sources, securely store data in the public cloud, and analyze the data using both AWS and 3rd-party analytics services.
However, transforming cloud object storage into a data lake still requires teams to transfer data out of the platform and into a cloud data warehouse, analytics platform, or business intelligence tool. Significant resources are needed for ETL — to replicate data, clean and prepare it, and transform it into an analytics-friendly format. The reality is, the data engineering talent pool is often in high demand and short supply.
The risks of replicating data (and moving data) at scale
ETL for cloud data is time-consuming, with data cleaning and preparation taking up to 80% of the total time to perform data analytics. In addition, it introduces more complexity, increases compute and storage costs, creates data privacy and compliance gaps, and delays insights. Data replication and data movement can ultimately make insights less useful, since the data is outdated or no longer meets the needs of the original query. In addition, ETL makes enterprise data analytics expensive. Not only is it costly to move data in and out of cloud object storage, secondary costs of duplicate data can add up.
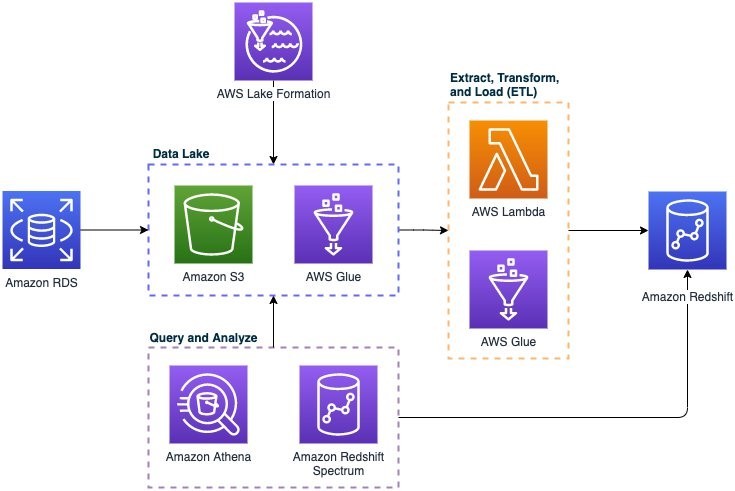
In this AWS S3 analytics architecture, Amazon S3 is used as a data lake storage backing for an Amazon Redshift data warehouse. Cloud data warehouses like Amazon Redshift can provide excellent performance for analytics queries, but the ETL process makes it complex, costly, and time-consuming to move data into the data warehouse - especially at scale.
As data volume grows, data composition changes and data pipelines inherently fail, there is a real risk of data loss during this process. Data security liability is another major concern. For instance, GDPR compliance requires “all” data to reside in the “country of origin.” To say that movement is fraught with danger, at every step, is a painful understatement.
Some organizations have devised alternatives to simplify ETL by introducing yet another data movement process, ELT (Extract, Load, Transform). This process transforms the data after it is loaded to its destination. After raw data is moved into a data warehouse, ELT often leverages the processing power of the data warehouse to change it into a format that can be analyzed. While the ELT process can be faster and simpler than ETL, the downsides of ELT include compliance risks of storing and transforming data outside its original destination, and mounting storage costs.

Analyzing cloud-based data directly in cloud object storage
The obvious solution to these problems is to not move or replicate data at all. Store it once, as the source of truth, and extract value where it lives. As more teams use cloud object storage like Amazon S3 as a system of record, they need to rethink the ETL portion of the equation. Moving data into external sources creates more data silos, which defeats the purpose of centralizing your data in a data lake to begin with.
The simple (self-evident) answer is to just turn storage such as S3 into a database for traditional analytic workloads. While easier said than done, this is exactly and purposely what ChaosSearch has so uniquely achieved - while never requiring customers to move data outside the boundaries of a data center, region or country. Storing data in S3 provides the highest level of security available. It has 11-9's of durability, can be replicated in real time for business continuity, with high availability for disaster recovery. This makes the data always available.
ChaosSearch has a fundamental philosophy: object storage should be the 'home base' and the 'source of truth' for all data, and that data should be 100% owned and controlled by the customer.
Object storage can be transformed into a high-performance data analytic platform with ChaosSearch. To do this, we created the first UltraHot® solution with our patent pending index technology. Based on this innovation, ChaosSearch created an intelligent compute fabric using AWS EC2, which runs in the same region as the customers’ S3 storage. Our service automates/streamlines the process of taking raw S3 data and cataloging it, indexing it, and storing it back into the customers’ S3 bucket. All searches and queries are performed on this indexed data in the customers’ S3, providing fast, scalable, and extremely cost-effective access.
Sample Configuration of CloudFront log analysis:
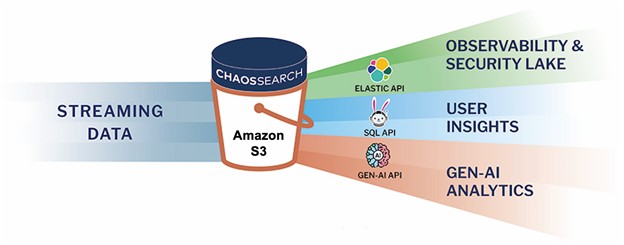
Rather than moving data with a traditional cloud data lake deployment, ChaosSearch can analyze cloud data directly in Amazon S3 or GCS, using familiar tools like Kibana, SQL or GenAI for analysis.
In summary, data movement should be a serious concern and consideration when designing a data analytic solution. Minimizing or eliminating data movement altogether should be a high priority for any compliance or security team within an organization. ChaosSearch offers a highly scalable and performant solution, with an architecture that supports secure data and compliance, at a best-in-class price point.

