

Data warehouses and data lakes represent two of the leading solutions for enterprise data management in 2023.
While data warehouses and data lakes may share some overlapping features and use cases, there are fundamental differences in the data management philosophies, design characteristics, and ideal use conditions for each of these technologies.
In this blog post, we’re taking a closer look at the data lake vs. data warehouse debate, helping you determine the right approach for your business. We’ll explore how data warehouse and data lake solutions emerged over the decades-long history of enterprise data management, the key differences between data warehouse and data lake architectures, and how to choose the right, future-proof solution for your business.

Defining Historical Moments in Enterprise Data Technology
The history of enterprise data storage technologies begins in 1960, when Charles W. Bachman developed the first Database Management System (DBMS). IBM had just invented hard disk storage (in 1956), so we had disk storage as the hardware and DBMS as the software for managing data storage.
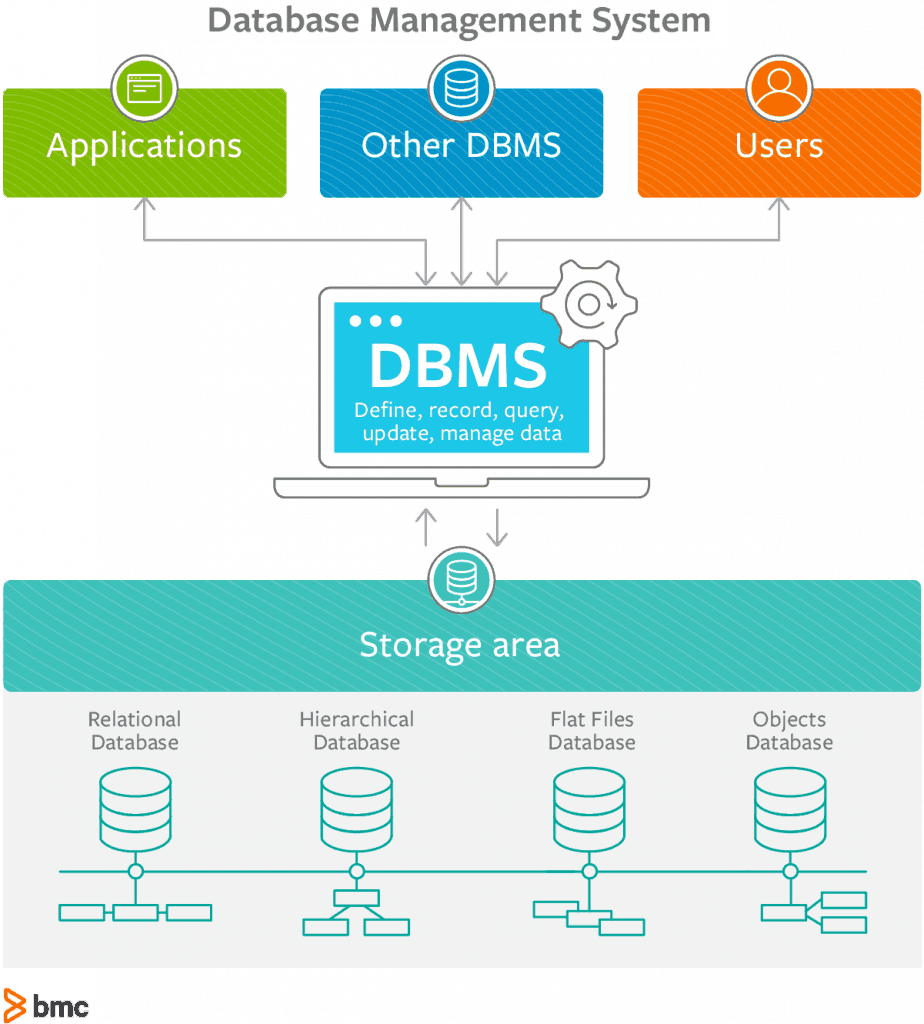
Database management systems make it easier to secure, access, and manage data in a file system. They provide an abstraction layer between the database and the user that supports query processing, management operations, and other functionality.
Image Source: BMC
These technologies rose in popularity in the ‘60s and early ‘70s as enterprise organizations started using online applications to process retail payments, insurance claims, airline reservations, and many other kinds of transactions. Large amounts of data were being generated rapidly and shared between computers and users, with hard disk storage and DBMS technology underpinning the entire system.
The 1980s saw an increase in the popularity of relational databases and the SQL query language used by relationship database management systems (RDBMS). Personal computing had also taken off: Organizations were assigning personal computers to their staff and moving towards a decentralized mode of data access.

Data Warehouses Emerged from Necessity
As computers and the Internet got faster, cheaper, and more accessible during the 1990s, we experienced a software revolution where enterprise organizations significantly increased the use of application systems in business operations. This meant an increase in the number of databases, data models, and applications (data sources) in use, driving the need for data warehousing solutions that could extract data from transactional/operational systems, transform it into a usable format, and load it into business intelligence (BI) systems to support analytical decision-making activities.
Though the first data warehouses were designed in the 1980s, data warehouse technology was not widely adopted until the 1990s and early 2000s, when organizations saw the potential to leverage big data analytics as a competitive advantage in an increasingly globalizing market environment.
Hadoop Failed to Replace Data Warehouses
In the early 2000s, data growth was on the rise and enterprise organizations were still using separate databases for structured, unstructured, and semi-structured data. As a result, data sources were increasingly siloed and it was becoming clear that data warehouses couldn’t scale efficiently to create value from the massive and rapidly growing volumes of data being generated by big data leaders.
This led to the development of distributed big data processing and the release of Apache Hadoop in 2006. Hadoop promised to replace the enterprise data warehouse by allowing users to store unstructured and multi-structured datasets at scale, and run application workloads on clusters of on-premise commodity hardware.
Hadoop had the right ideas about bringing together data storage and analytics, but it would soon take a back seat to an even greater innovation. In the same year that Hadoop was released, we saw the launch of Amazon Web Services (AWS) and the release of Amazon Simple Storage Service (S3).
Cloud object storage offered an even cheaper data storage platform while relieving the burden of administration, security, and maintenance associated with running on-prem servers.
As cloud service providers expanded their capabilities and product offerings, organizations began migrating data processing capabilities (both data warehouses and Hadoop clusters) from on-premise servers into the cloud, leveraging solutions like Amazon Redshift and Google BigQuery for faster and cheaper data processing.
Read: 10 AWS Data Lake Best Practices
The Data Lake Movement
The needs of big data organizations and the shortcomings of traditional solutions inspired James Dixon to pioneer the concept of the data lake in 2010.
Dixon’s vision situated data lakes as a centralized repository where raw data could be stored in its native format and aggregated and extracted into the data warehouse or data mart at query-time. This would allow users to perform standard BI queries, or experiment with novel queries to uncover novel use cases for enterprise data. Queries could be fed into downstream data warehouses or analytical systems to drive insights for decision-makers.
Public cloud service providers have provided the most cost-effective infrastructure for data lake storage, with solutions like Amazon S3, Microsoft Azure Lake Data Store (ADLS), and Google Cloud Storage (GCS).

Data Lake vs Data Warehouse: What’s the Difference?
Now that we’ve explored the historical context, we’re ready for a closer look at some of the technical differences between data warehouse and data lake technologies. Below, we highlight the defining characteristics of data warehouses and data lakes, along with the most important differences between them.
What is a Data Warehouse?
A data warehouse is a data management system that provides business intelligence for structured operational data, usually from RDBMS. Data warehouses ingest structured data with predefined schema, then connect that data to downstream analytical tools that support BI initiatives.
The key benefits of a data warehouse include:
- maintaining data quality and consistency
- storing large amounts of historical business data
The drawback: data warehouses follow a schema-on-write data model, meaning that source data must fit into a predefined structure (schema) before it can enter the warehouse. This is usually accomplished through an ETL (Extract-Transform-Load) process.
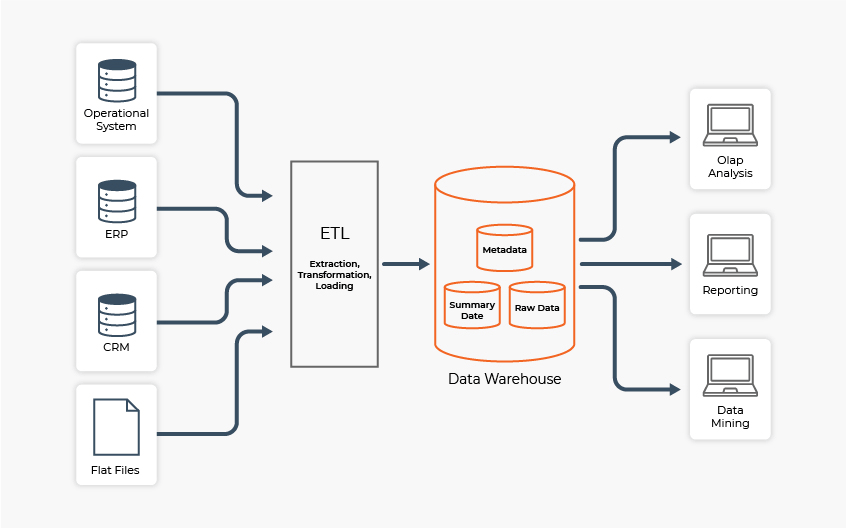
This sample architecture contains all the most important elements of a data warehouse architecture. Data is captured from multiple sources, transformed through the ETL process, and funneled into a data warehouse where it can be accessed to support downstream analytics initiatives (data mining, reporting, and OLAP analysis).
Image Source: DW4U
This connection between data ingress and the ETL process means that storage and compute resources are tightly coupled in a data warehouse architecture. If you want to ingest more data into the warehouse, you need to do more ETL, which requires more computation (and increases time, cost, and complexity). Defining schema also requires planning in advance -- you need to know how the data will be used so you can optimize the structure before it enters a warehouse.
Data warehouse solutions are designed for managing structured data with clear and defined use cases. If you’re not sure how some data will be used, there’s no need to define a schema and warehouse it. For organizations operating in the data warehouse paradigm, data without a defined use case is often discarded.
What is a Data Lake?
A data lake is a centralized data repository where structured, semi-structured, and unstructured data from a variety of sources can be stored in their raw format. Data lakes help eliminate data silos by acting as a single landing zone for data from multiple sources.
While data warehouses can only ingest structured data that fit predefined schema, data lakes ingest all data types in their source format. This encourages a schema-on-read process model where data is aggregated or transformed at query-time (unlike data warehouses, where transformations happen in the ETL process, before the data enters the warehouse).
One of the key benefits of schema-on-read is that it results in a loose coupling of storage and compute resources needed to maintain a data lake. Bypassing the ETL process means you can ingest large volumes of data into your data lake without the time, cost, and complexity that usually accompanies the ETL process. Instead, compute resources are consumed at query-time where they’re more targeted and cost-effective.
The key benefits of a data lake include:
- eliminating data silos
- improving scalability of data systems
- unlocking innovation with integrated functionality and specific use cases
Data lake storage solutions have become increasingly popular, but they don’t inherently include analytic features. Data lakes are often combined with other cloud services or software tools that deliver data indexing, transformation, querying, and analytics functionality. Enterprises can also integrate BI and visualization tools with a data lake to streamline the creation of charts and dashboards that convey insights from the data.
.png?width=886&name=Data%20Lake%20Architecture%20Sample%20(1).png)
In this sample data lake architecture, data is ingested in multiple formats from a variety of sources. Raw data can be discovered, explored, and transformed within the data lake before it is utilized by business analysts, researchers, and data scientists.
Image Source: Medium
The drawback: without the proper organization, governance, or integration with known ETL or analytics tools, the data lake can become a “data swamp” where data quality is degraded and data sits stagnant because users can’t effectively access or glean insights from it.
Data lakes make it easy and cost-effective to store large volumes of organizational data, including data without a clearly defined use case. This characteristic of data lake solutions enables analysts to query data in novel ways and uncover new use cases for enterprise data, thus driving innovation and enhancing business agility.
READ: 7 Data Lake Challenges; Or, Why Your Data Lake Isn’t Working Out
Should You Choose a Data Lake or Data Warehouse for Your Organization?
Let’s quickly recap the differences between data warehouses and data lakes to make sure we’re on the same page.
Data warehouses store structured data, operate with a schema-on-write process model, have tightly coupled storage and compute requirements, and are most effective for managing data with predefined analytics use cases.
Data lakes store all kinds of data (structured, unstructured, and semi-structured), operate with a schema-on-read process model, have loosely coupled storage and compute requirements, and work well for managing data with undefined use cases. But they often require expertise of data engineers or data scientists to figure out how to sift through all of the multi-structured data sets, and they require integration with other systems or analytic APIs to support BI.
So with all that said, which option is best for you?
The first thing to note in the data lake vs data warehouse decision process is that these solutions are not mutually exclusive. Data lakes and data warehouses can be deployed together as part of a complete data and analytics strategy. We’re also seeing the emergence of data lakehouse and data mesh solutions that incorporate features of both data warehouses and data lakes.
Read: Data Lake vs. Data Mesh: Which One is Right for You?
The data warehouse model is all about functionality and performance - the ability to ingest data from RDBMS, transform it into something useful, then push the transformed data to downstream BI and analytics applications. These functions are all essential, but the data warehouse paradigm of schema-on-write, tightly coupled storage/compute, and reliance on predefined use cases makes data warehouses a sub-optimal choice for big, multi-structured data or multi-model capabilities.
Data lakes provide a less restrictive philosophy that’s more suited to meeting the demands of a big data world: schema-on-read, loosely coupled storage/compute, real-time data lake analytics, and flexible use cases that combine to drive innovation by reducing the time, cost, and complexity of data management. But without data warehouse functionality, a data lake can become a data swamp -- a murky mire of data that’s impossible to sift through.
To avoid creating data swamps, technologists need to combine the data storage capabilities and design philosophy of data lakes with data warehouse functionalities like indexing, querying, and analytics. When this happens, enterprise organizations will be able to make the most of their data while minimizing the time, cost, and complexity of business intelligence and analytics.
READ: 10 AWS Data Lake Best Practices
Future-Proofing Enterprise Data Management
Enterprise organizations in 2023 continue to rely on a variety of data storage and analytics solutions to meet their needs, including RDBMS, operational data stores, data warehouses and marts, Hadoop clusters, and data lakes.
Data lakes are showing their potential for resilient data management in the cloud, but that doesn’t mean you should replace your entire data and analytics strategy with a single implementation. Instead, think of data lakes as one of many possible solutions in your D&A toolbox -- one that you can leverage when it makes sense.
An effective data lake must be cloud-native, simple to manage, and interconnected with known analytics tools so that it can deliver value.
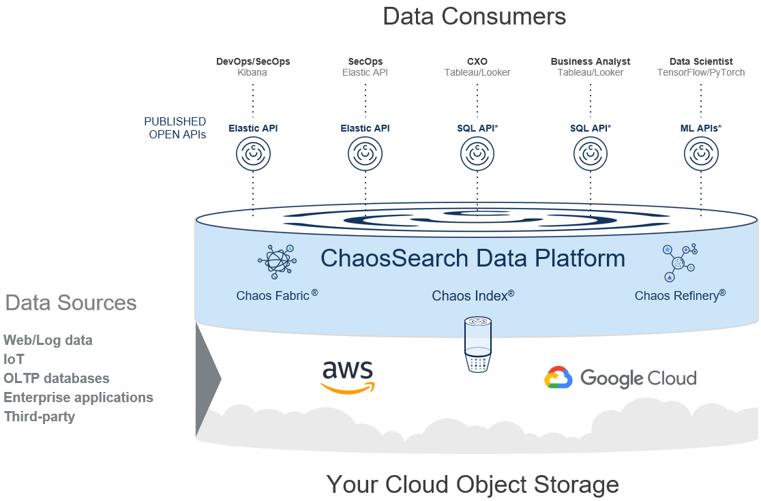
ChaosSearch transforms your Amazon S3 buckets into a data lake repository with full text and relational search capabilities. Querying and data analytics are native features, made possible by the Elastic API and our customized version of Kibana.
Image Source: ChaosSearch
At ChaosSearch, our goal is to help customers prepare for the future state of enterprise data management by bridging the gap between data lakes and data warehouses. ChaosSearch transforms your data lake into an analytic database, activating your cloud object storage environment for search, analytics, and machine learning workloads. It takes just minutes to start generating insights for diverse use cases like security operations, cloud infrastructure monitoring, DevOps analysis, and log analytics in the cloud.
Ready to learn more?
Watch our free on-demand webinar Data Architecture Best Practices for Advanced Analytics to discover best practices for optimizing your analytics architecture with ChaosSearch.


