


What’s the right way to manage growing volumes of enterprise data, while providing the consistency, data quality and governance required for analytics at scale? Is centralizing data management in a data lake the right approach? Or is a distributed data mesh architecture right for your organization? When it comes down to it, most organizations seeking these solutions are looking for a way to analyze data without having to move or transform it via complex extract, transform and load (ETL) pipelines.
Many teams find themselves stretched by a shortage of data science, analyst, and data engineering talent. These teams often sit in between data consumers and the existing infrastructure; they spend a lot of time transforming and modeling the data so that business users can analyze it. The problem with this approach is that it’s not sustainable across multiple business domains, and it’s impossible to interrogate data multiple times without having to go back to the centralized data science or engineering team to have them transform the data all over again.
Meanwhile, many data and IT leaders are in the midst of efforts to upskill employees across the enterprise to become citizen data scientists. They’ve launched self-service BI and data literacy initiatives aimed at helping business users gain deeper application insights for data-driven teams. A big success factor for these types of initiatives sounds simple: you must empower users to query and analyze data where it lives.
So which approach makes more sense? Keeping the data distributed across a variety of sources (or a data mesh), or centralizing it within a cloud based data lake? Potentially both?
Let’s dive into each approach, and then determine whether a data mesh vs. data lake strategy may be right for your team.

What is Data Lake Architecture?
A data lake is defined as a data storage repository that centralizes, organizes, and protects large amounts of structured, semi-structured, and unstructured data from multiple sources. Unlike data warehouses that follow a schema-on-write approach (data is structured as it enters the warehouse), in a schema-on-read data lake, data can be structured at query-time based on a user’s needs.
Data lake storage solutions have become increasingly popular (e.g. cloud object storage), but it’s important to note that they don’t inherently include analytic features. Data lakes are often combined with other cloud-based services and downstream software tools to deliver data indexing, transformation, querying, and analytics functionality.
To that end, data lake organization is important, especially when it comes to integrating BI and data visualization tools. The differences between a data lake vs. data platform will become clear once these organizational strategies are put into place, such as incorporating data catalogs to keep your data searchable for business users.
In a data lake architecture, a self-service data analytics engine (such as ChaosSearch) sits on top of a cloud-based data repository, delivering key features that help organizations achieve data lake benefits and realize the full value of their data. This approach can activate low-cost cloud object storage (for example, Amazon S3 or Google Cloud Storage), enabling teams to ingest, index and analyze their data in real-time, without having to move it into a separate ETL pipeline for analysis.

READ: The Rise of the Cloud Data Platform and Index-Driven Data Lake
What is Data Mesh?
Data mesh is a modern, distributed architecture that’s all about self-service, and treats data as a product. A data mesh supports the idea of distributed data consumers, all of whom are responsible for handling their own domain-driven data pipelines. A key tenet of data mesh thought leadership is the fact that data can remain within different databases, rather than being consolidated into a single data lake.
Data mesh architecture connects a wide variety of sources (including a data lake or data lakehouse) into a coherent infrastructure, where volumes of data are accessible, as long as you have the right authority to access it.
Some argue that the data mesh philosophy is just a strawman for a more complicated problem: in reality, you still need to move and transform the data via a centralized data engineering team to get the desired result. Others, like Gartner, argue the data mesh concept will become obsolete and replaced with something else. Either way, you should be able to interrogate the data as many times as you’d like to as a data consumer, without having to transform or move the data in the first place.
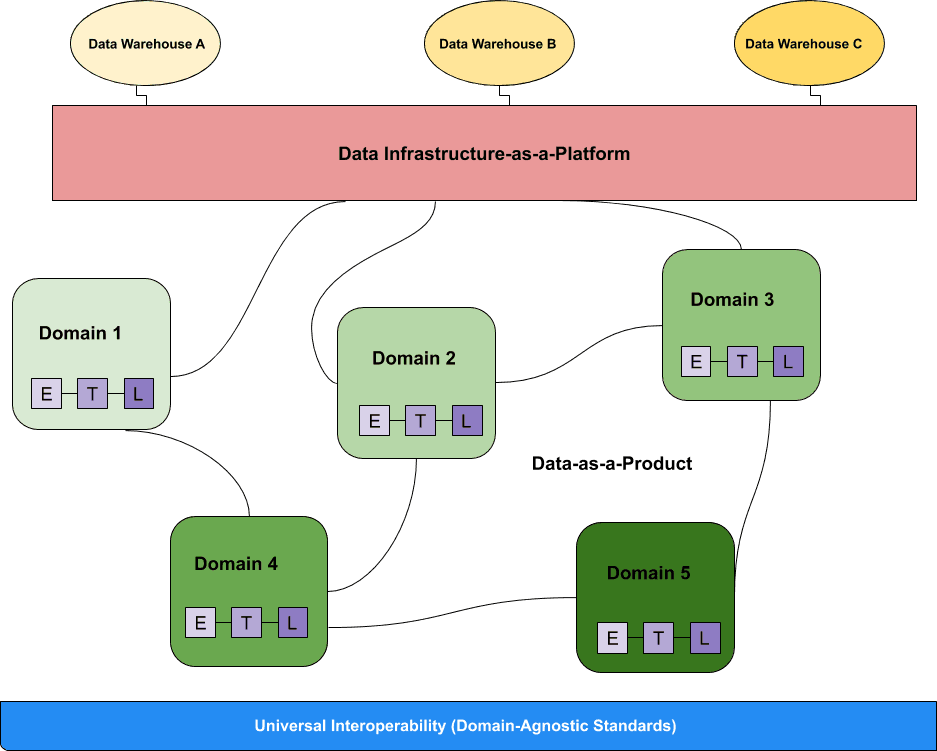
Image Source: Towards Data Science
Comparing Data Lake vs. Data Mesh
While both data lakes and data mesh architectures offer different, modern approaches to data integration (and ultimately, faster time to analytical insights), they aren’t necessarily at odds. They may actually be complementary.
For example, some pundits claim that data lakes are becoming obsolete. This argument is based on the idea that you have to move data from one place to another within a data lake architecture in order to query it. That’s not true, with the right tools in place. The first data lakes built on Hadoop failed, creating “data swamps” that were hard to navigate, but there’s been tremendous innovation since then. New models allow you to index multiple data types and make this data available and accessible by streaming it. This approach removes the constraints inherent to traditional data lake storage and infrastructure.
Read: Data Lake Challenges: Or, Why Your Data Lake Isn’t Working Out [VIDEO]
A modern cloud data platform enables anyone to query the data where it lives, without having to perform complex ETL pipelines. As mentioned above, modern data lakes are built on cloud object storage and can be activated to support multi-dimensional and multi-model analytics use cases such as full text search, relational queries, and machine learning. Data lakes vs. data warehouses don’t have to be an either-or proposition with an open philosophy, offering schema-on-read, loosely coupled storage/compute and flexible use cases that combine to drive innovation by reducing the time, cost, and complexity of data management.
Some data mesh supporters claim that data lakes are just one of the endpoints within a mesh architecture. They’re also right! The main argument here is that data will always be distributed, and data mesh architecture embraces that reality.
While many organizations store data in multiple silos, querying data where it lives, within a mesh architecture, can only be as fast as the slowest query. For organizations looking for faster, more performant queries, it still makes sense to use a cloud data platform for analytics within a data mesh architecture for AWS (or cloud provider of your choosing).
Which Distributed Data Platform is Right for You?
The bottom line? Data lakes and data meshes can and should coexist, and it’s not an either/or proposition. Many organizations already have the cloud infrastructure in place to double down on a data lake approach.
If that’s the case in your organization, look for a platform that enables queries without data movement. Others store their data across multiple databases, both on-premises and in the cloud. One of those endpoints may be a cloud data lake. In this case, a mesh architecture may be right for you.
Solutions like ChaosSearch not only coexist within a data mesh architecture but empower it, by making it easier to virtually publish logical data views to query within the data lake without ETL pipelines. This approach democratizes access to data, allowing anyone in the organization to interrogate data at will, without the need for a data scientist or data engineer as an intermediary. Ideally, there needs to be a standards organization, or contract if you will, that exists within a data mesh architecture between data producers and consumers to make data discoverable and configurable.
In a reimagined data lake as a service, such as the one shown in the image below, raw data is produced by applications (either on-prem or in the cloud) and ingested into Amazon S3 buckets with services like Amazon CloudWatch or a log aggregator tool like Logstash. A self-service cloud data platform like ChaosSearch sits on top of a cloud-based data repository, delivering key features that help organizations realize the full value of their data.
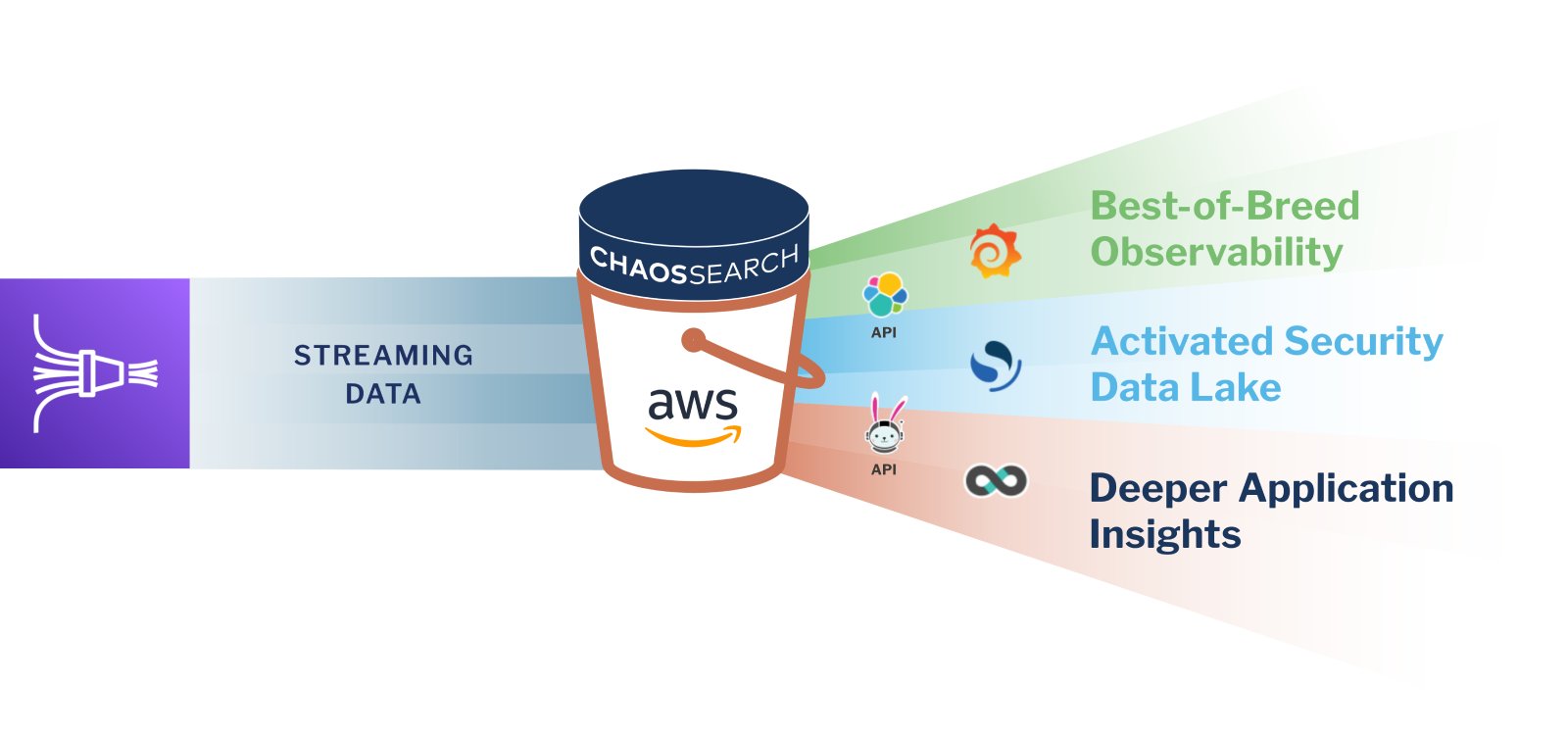
READ: Think You Need a Data Lakehouse?
Regardless of the semantics you follow, the desired end state for most organizations is to have a unified platform for analytics. Users want the ability to access and analyze data of all types from where it resides, without complex data engineering or data modeling behind the scenes. It’s encouraging to see many different organizations working on new approaches to democratize access to data, in many cases by leveraging cloud storage assets they already have.


