

As enterprises digitize their businesses, their digital actions create myriad data points that hold great potential value. But, like pieces of a puzzle, you realize the true value when you integrate the data points.
READ: How Log Analytics Powers Cloud Operations, Part II: Use Cases

Industry Convergence
The cloud data platform, an emerging paradigm that combines elements of data warehouses and data lakes, seeks to integrate those myriad data points, generate insights, and create business value. The cloud data platform can help enterprises create more business value than was possible with the data warehouse or data lake on their own, because it brings together many data types, users, and use cases. It transforms and delivers data to business intelligence (BI) and data science tools, as well as applications that embed BI and data science algorithms. The cloud data platform thus provides a common repository to support the overlapping worlds of BI, data science, and applications.
Figure 1 illustrates the convergence of data warehouse and data lake elements into the cloud data platform. Some vendors and practitioners also call this concept the data lakehouse or unified analytics platform.
Figure 1. Convergence of the Data Warehouse and Data Lake into the Cloud Data Platform
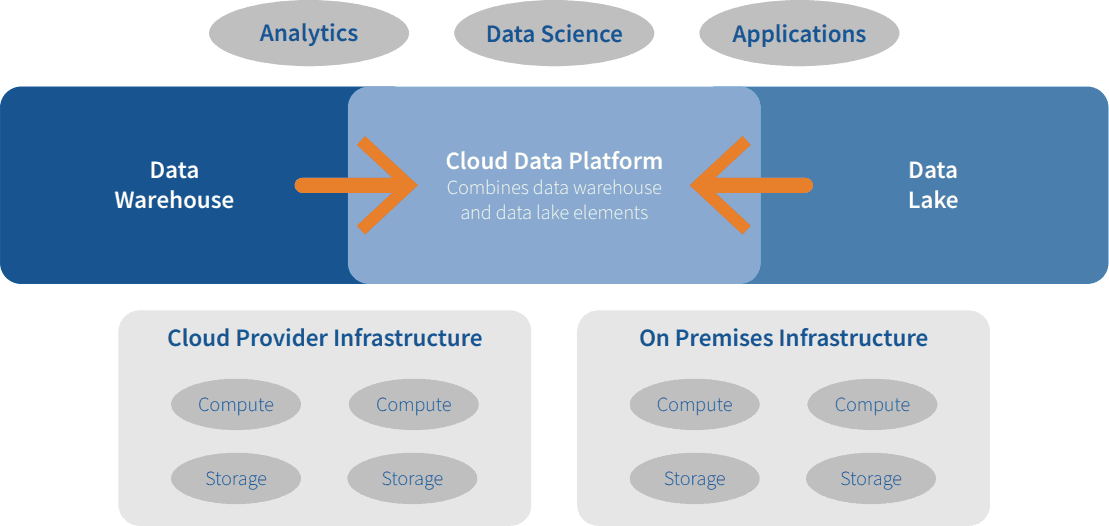
What is the Cloud Data Platform?
Each cloud data platform combines a mix of the following elements.
From the data warehouse:
- Ability to query and transform data, for example using structured query language (SQL) commands.
- Ability to update records — for example, related to financial transactions—with ACID compliance. This maintains the validity of inter-related records by ensuring changes are atomic, consistent, isolated, and durable.
- Support for BI or other analytics tools that query data, for example using a semantic layer that presents data in business terms and structures.
- Governance capabilities such as data quality checks, data masking, and role-based access controls.
From the data lake:
- Classification of various types of data as objects, each of which has an identifier and metadata.
- Support for multiple analytics methods. These include SQL queries, data science modeling, and search engines such as Elasticsearch.
- Support for the ecosystem of data science software, including processors such as Apache Spark, model libraries such as TensorFlow, and model development notebooks such as Jupyter.
- An open architecture whose open data formats and open APIs enable users to move data between tools, processors, and platforms with less effort.
Cloud data platforms consume cloud provider infrastructure, which includes storage and compute resources that can scale independently of one another. A cloud data platform might run on infrastructure from one or more of the cloud providers, such as AWS, Azure, or Google, for a given enterprise. Cloud data platforms also might consume infrastructure on premises given the hybrid nature of many enterprise environments. They optimize performance with capabilities such as columnar processing, workload isolation, and lightweight indexing.
READ: Think You Need a Data Lakehouse? Read this first
Figure 2 illustrates these core elements of a cloud data platform as they deliver data from cloud and on-premises infrastructure to analytics users, data science users, and applications.
Figure 2. Elements of the Cloud Data Platform
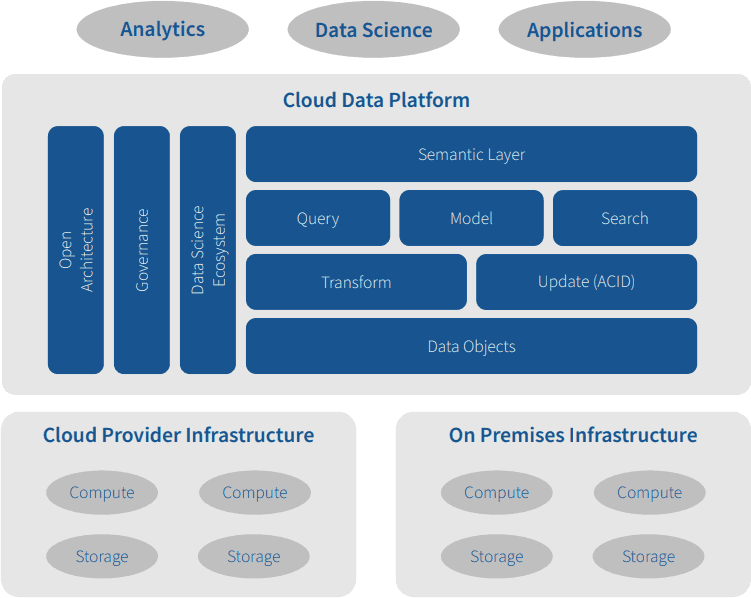
How Should You Evaluate a Cloud Data Platform?
Enterprise data teams have a few options to consider in this category. Each vendor offers a distinct mix of elements, and extends their platform with additional capabilities. For example:
- Data cloud. Offered by Snowflake, this approach supports analytics, data science, and data-driven applications by running multiple workloads on one copy of data.
- SQL lakehouse. Offered by Dremio, this approach supports BI use cases by querying the object store directly and minimizing the need for ETL copies.
- Unified analytics platform. Offered by Vertica, this approach supports analytics, data science, and data-driven applications by applying columnar processing and other performance optimizations to multiple copies of data.
- Index-driven cloud data platform. Offered by ChaosSearch, this approach supports log analytics and BI by using a compressed index to transform, query, and search a common data store.
READ: Data Lakes Are Gaining Maturity, According to 2021 Gartner Hype Cycle™ for Data Management

ChaosSearch
ChaosSearch’s index-driven cloud data platform helps mid-sized and large enterprises increase the scale of their log analytics and BI workloads without incurring too many expensive compute cycles. It transforms, queries, and searches data objects to support analytics use cases such as log analytics and BI. ChaosSearch presents the results to analytics tools; and feeds log alerts to incident management and collaboration tools. The ChaosSearch platform supports open data formats as part of an open architecture, and offers basic governance elements such as role-based access controls.
ChaosSearch started with log analytics. They developed an alternative to the Lucene index, which underpins the popular open source ELK stack (comprising the open source tools Elasticsearch, Logstash, and Kibana). With ChaosSearch’s highly compressed index, ITOps, DevOps, or CloudOps engineers can analyze more IT logs faster in order to manage the performance and reliability of their IT infrastructure. ChaosSearch also now supports SQL queries, which helps data analysts process more data, faster, and thereby sharpen their insights. It intends to extend its platform to provide similar benefits to data science users later this year. ChaosSearch operates on cloud infrastructure.
To learn more about this market segment and the ChaosSearch offering in particular, read this Deep Dive report by Eckerson Group.


Learn More
Read the Blog: How Log Analytics Powers Cloud Operations: Three Best Practices for CloudOps Engineers
Watch the Webinar: Why and How Log Analytics Makes Cloud Operations Smarter
Read the Whitepaper: Security Log Analytics: Spotting and Stopping Bad Guys at Scale

