

Since the 2006 launch of Amazon Web Services (AWS), the world’s first hyper-scale public cloud provider, thousands of data-driven businesses have shifted on-premise data storage and analytics workloads into the cloud by architecting or adopting a cloud data platform.
As the volume, variety, and velocity of enterprise data continues to grow in 2023, cloud data platforms with legacy tech and complex architectures are becoming increasingly time-consuming and costly to manage. And as a result, data executives are searching for ways to simplify cloud data platform architectures, reduce management costs, and eliminate complexity while continuing to realize the full value of data for use cases like observability and security operations.
In this week’s blog, you’ll discover the four essential layers of cloud data platform architecture, learn common features of modern and sophisticated cloud data platforms, and see examples featuring AWS and Google Cloud Platform (GCP).
You’ll also learn how ChaosSearch delivers a simplified cloud data platform architecture that crushes complexity and democratizes data access across multiple analytics use cases.

What is a Cloud Data Platform?
A cloud data platform is an integrated software solution that enables enterprise organizations to aggregate, store, process, and consume data in the cloud. Some enterprises are deploying pre-integrated cloud data platform products, while others have chosen to build modular cloud data solutions by integrating a mix of open-source and best-of-breed technologies.
Public cloud services like AWS, GCP, and Microsoft Azure provide cost-effective object storage for enterprise data, along with scalable compute resources and proprietary cloud services for ingesting, processing, analyzing, and serving the data to consumers.
There are also SaaS solutions from independent vendors like Snowflake and ChaosSearch that integrate with public cloud storage to deliver strong cloud data platform capabilities (e.g. data processing, data warehouse and data lake functionality, analytics, etc.) on top of cloud object storage.
What is a Cloud Data Warehouse?
Cloud data platforms capture data from multiple sources and aggregate it into cost-effective cloud object storage. From there, the data may be normalized and transformed into a relational format to prepare it for downstream analytics applications.
Many cloud data platforms include a cloud data warehouse, a database where cleaned and prepared data in a relational format is stored to support business intelligence (BI) and analytics use cases. Cloud data platforms can also be architected to include data lake storage or subject-oriented data marts that cater to specific business units.
Read: Data Lake vs Data Warehouse
What are the Four Layers of Cloud Data Platform Architecture?
There are four fundamental layers to a cloud data platform architecture: data ingest, data storage, data processing, and data serving. Each of these layers represents a functional software component that delivers specific capabilities within the cloud data platform.
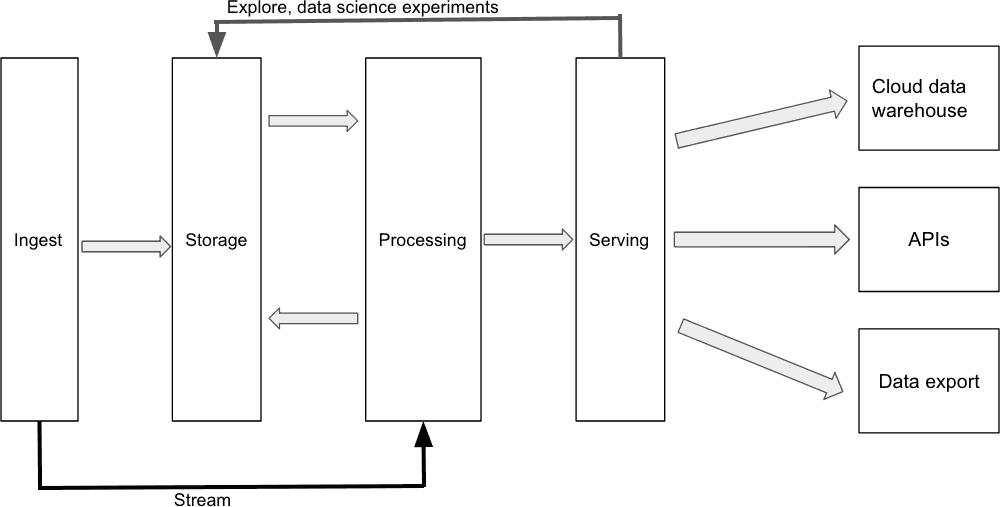
A generic representation of a four-layer cloud data platform architecture.
Data Ingest Layer
Software components in the data ingestion layer serve the function of connecting source systems to the cloud data platform and ingesting data from those systems into cloud storage. Data ingestion tools should connect to a variety of data sources, with support for batch and real time data ingestion.
Data normalization and transformations can be applied in the ingestion layer, but the current best practice is to leave the data in its raw format so it can be analyzed in different and novel ways without having to ingest it from the source again.
Data Storage Layer
Raw data passes through the data ingest layer and lands in the data storage layer. Public cloud vendors offer the most cost-effective cloud object storage, giving enterprises the flexibility to store large volumes of data and retain it for long periods of time.
In addition to being cost-effective, cloud data storage is both scalable and highly reliable. The failover and recovery capabilities offered by vendors like AWS are second-to-none, and organizations can easily grow or shrink their cloud data storage capacity as needed.
Despite the efficiency and flexibility of cloud data storage, some enterprises already generate more data than they can efficiently process, retain, and analyze with their existing cloud data platform architecture and processes. Enterprise data teams handle this by imposing data retention limits that reduce costs, but also limit the usability of data.
Data Analytics/Processing Layer
The function of components in the data processing layer is to read data from storage and apply normalization techniques, transformations, and business logic that converts the raw data into structured, useful, and meaningful information for downstream consumption.
Software components in the data processing layer enable data scientists and analysts to interactively explore the data and dynamically apply transformations to support a variety of use cases. Some tools offer an SQL interface that makes it easy for analysts, data scientists, or data engineers to query data and apply transformations.
Data Serving Layer
The last essential layer of cloud data platform architecture is the data serving layer. Software components in this layer function by delivering the output of the data analytics/processing layer to downstream data consumers. The data serving layer often includes a cloud data warehouse where relational tables are stored, but may also include data lake, data lakehouse, or data mart deployments.
Check out the Case Study: Equifax Simplifies Cloud Operations Management Globally with Cloud Data Platform
Features of Sophisticated Cloud Data Platform Architectures
Modern cloud data platforms offer additional features and capabilities that go beyond the four basic layers of platform architecture. These include support for batch and stream data ingestion, tiered data storage capabilities, workload orchestration, a metadata layer, and ETL tools.
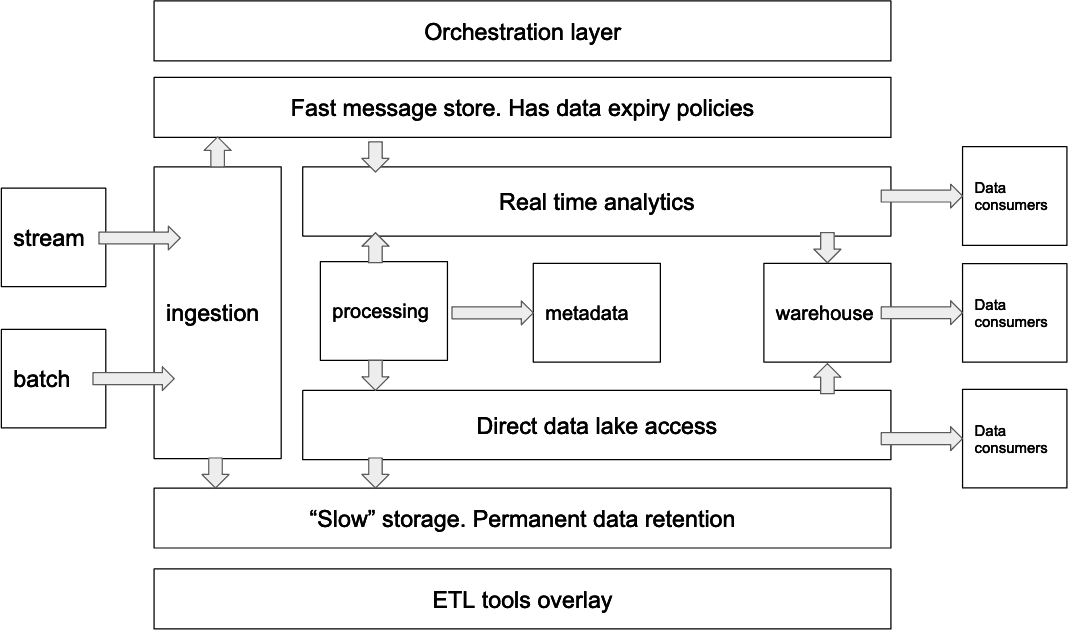
A sophisticated cloud data platform layered architecture.
Batch and Stream Ingestion
Sophisticated cloud data platform architectures include support for both batch and stream data processing. Data streaming enables real time analytics use cases, while batching is needed for data sources that only support batch data access.
Tiered Data Storage
A tiered approach to data storage allows data engineers to route data into short-term or long-term storage as needed to support analytics and compliance use cases. Short-term storage is used for data that will be analyzed in the immediate future. Short-term storage is more expensive, but supports low-latency access that enables performant analytics.
Long-term storage provides a lower-cost alternative for storing data that may not be analyzed right away, but must be retained for long periods of time.
Metadata Layer
In sophisticated cloud data platform architectures, a metadata layer stores all kinds of information: schema information from data sources, health and status information about data ingestion and analytics components, statistics about ingested or processed data, and more.
Implementing a metadata layer reduces software interdependencies by allowing software components in all layers of the cloud data platform to get information about data in the system without talking directly to other components.
Orchestration Layer
Some modern cloud data platform architectures incorporate an orchestration layer where software tools like Apache Airflow or cloud services like AWS CloudFormation and Google’s Cloud Composer are used to automate and coordinate data processing workloads, as well as manage failures and retries.
ETL Tools
Extract, Transform, Load (ETL) software tools make it easier for data engineers to implement, manage, and maintain the pipelines that move enterprise data through the cloud data platform. ETL tools can take on multiple roles in the platform, such as adding data and configuring data sources, creating data processing/transformation pipelines, storing metadata, and even coordinating workloads.
Cloud Data Platform Architecture Examples
Marketing Analytics Reference Architecture on Google Cloud
Published on the Google Cloud website, this reference architecture shows how GCP users can leverage GCP infrastructure and services to build a cloud data warehouse for marketing analytics applications.
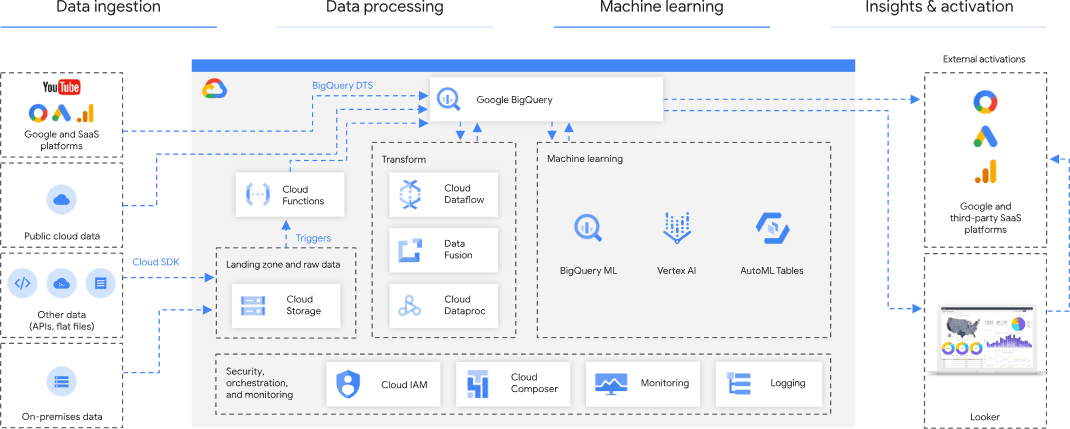
In this architecture, structured data from Google and SaaS platforms is ingested directly into the Google BigQuery data warehouse, while unstructured data is ingested directly into cloud object storage. GCP services like Cloud Dataflow and Data Fusion are involved in transforming and processing the data, with Cloud Composer providing workload orchestration capabilities.
Once the data has been normalized and processed, marketing analysts can visualize or dashboard it using Looker. It’s also possible to support marketing use cases by re-importing data into platforms like Google Analytics or third-party SaaS applications like Salesforce.
AWS Data Lakehouse Architecture
Here’s an example of a cloud data platform architecture featuring AWS services.
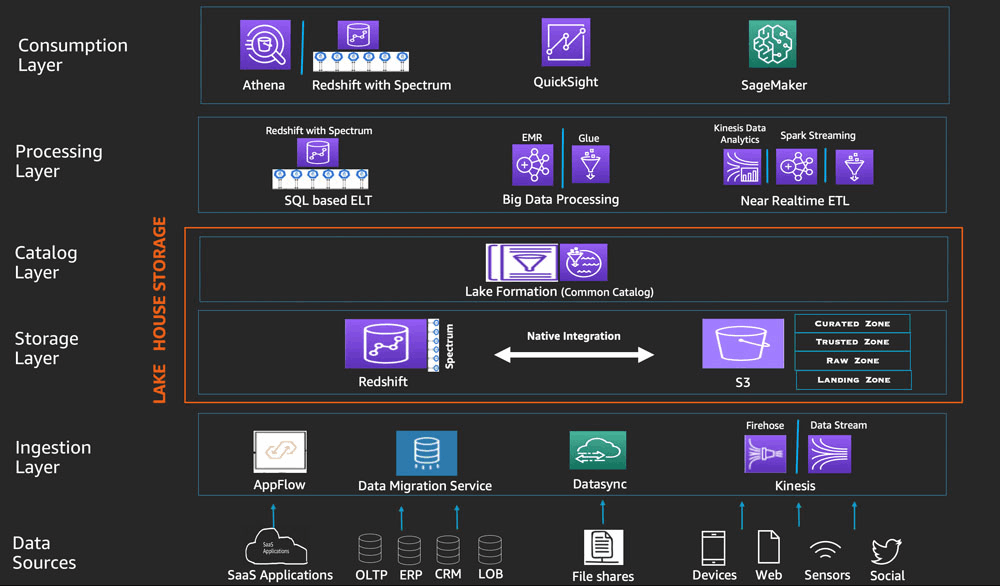
In this reference architecture, we have a data ingestion layer that uses multiple applications and cloud services (e.g. AppFlow, Kinesis, Datasync, etc.) to capture data from various sources.
Data is stored in Amazon S3 (cloud object storage) and natively integrated Amazon Redshift (cloud data warehouse) with a data catalog layer on top to enable data discoverability.
The data processing layer here supports SQL-based ELT, big data processing, and near real-time ETL with AWS services like Spectrum, EMR, Glue, and Kinesis Data Analytics. And once data has been processed, users can consume the data with analytics services including Amazon’s QuickSight BI platform, the SageMaker machine learning (ML) platform, or Amazon Athena.
Read: Unpacking the Differences between AWS Redshift and AWS Athena
Future-Proof Your Cloud Data Platform Architecture with ChaosSearch
The ChaosSearch data lake platform delivers a simplified architecture that reduces the cost and complexity of cloud data analytics at scale, enabling use cases that include security operations, application troubleshooting, and monitoring cloud services.
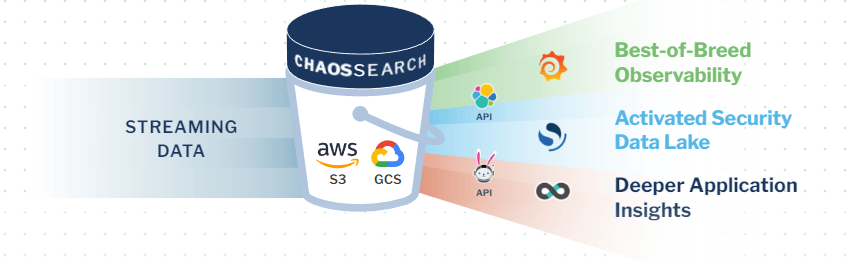
ChaosSearch transforms your AWS or GCP cloud object storage into a hot data lake for analytics in the cloud.
Data is ingested from source systems directly into Amazon S3 object storage, where we index the data with proprietary Chaos Index® technology to create a full representation with 10-20x compression. Once data has been indexed, users (e.g. data scientists, data engineer, SecOps teams, etc.) can query and transform it in Chaos Refinery® before visualizing the data and building dashboards in the integrated Kibana Open Distro.
These services run on top of Chaos Fabric®, a stateless architecture that enables independent and elastic scaling of storage/compute resources with high data availability.
While other cloud data platforms depend on fragile ETL pipelines and wastefully replicate data between the storage and data serving layers, ChaosSearch has the unique capability to index, virtually transform, analyze, and visualize data directly in Amazon S3 and GCP with no data movement, no ETL process, and no limits on data retention.
Ready to learn more?
Start Your Free Trial of ChaosSearch and experience a simplified cloud data platform that enables data analytics at scale.

