

Modern SecOps teams use Security Information and Event Management (SIEM) software to aggregate security logs, detect anomalies, hunt for threats, and enable rapid incident response.
While SIEMs enable accurate, near real-time detection of threats, today's SIEM solutions were never designed to handle the volume of security data organizations generate daily. As daily log ingestion grows, so do the costs of data management. These costs include ingesting, processing, analyzing, and storing/retaining security logs in the SIEM. With added data volume, SIEM query performance can also deteriorate, delaying critical insights and increasing the organization’s vulnerability to cyber attacks.
SecOps teams may try to salvage SIEM performance by reducing the data retention window for security logs. However, doing so negatively impacts threat hunting and can further damage the organization's security posture.
Thankfully, there’s another way to store and manage security data that can help you overcome these challenges. A Security Data Lake can augment or replace existing SIEM Solutions, and bolster their security posture.
In this blog, we’ll explain the unique features and benefits of security data lakes, how it can complement your existing SIEM solution, and practical guidance for getting started.

What is a Security Data Lake?
A Security Data Lake is a centralized repository for aggregating, storing, and analyzing enterprise security data. These tools use a data lake architecture to deliver cost-effective data storage and log analytics for SecOps teams at scale. Here are some of the key advantages:
- Schema-on-Read Approach - SIEM solutions typically ingest structured data or auto-normalize security data as they ingest it (an approach known as schema-on-write). Data lakes ingest raw data in its source format - whether structured, unstructured or semi-structured. Using these tools, it’s easier to analyze data in any format (an approach known as schema on read).
- Loosely Coupled Storage and Compute - The schema-on-read approach results in a loose coupling of the storage and compute resources needed to maintain your security data lake. Being able to ingest raw data makes it faster, cheaper, and easier to ingest logs into your Security Data Lake.
- Fewer Data Restrictions - While SIEM tools are relatively narrow in the types of data they can accept, a Security Data Lake can collect and analyze a high volume of security data from multiple data sources. This provides a more comprehensive view of enterprise security. Sources can include security logs from the organization’s IT infrastructure, along with user access logs, threat intelligence, and other types of security data.
- Multi Model Analytics - Enterprise SecOps teams can query their data in several different ways, including SQL/relational querying, full-text search, and using Artificial Intelligence (AI) or Machine Learning (ML) tools.
- Real-Time Capabilities: A real-time data lake stores data as soon as it is generated without making assumptions about the data’s structure or type. This is important for the immediate analysis and reporting of ongoing events. For example, intrusion detection scenarios rely on the streaming data capabilities available in some data lakes.

This data lake architecture supports the intake of data in multiple formats from various sources. Within the lake, raw data can be examined, analyzed, and refined before being utilized by business analysts, researchers, and data scientists.
Image Source: Medium
The unique characteristics of data lake architecture make this an excellent option for cost-effectively storing and retaining security data at scale. You can continue using a trusted SIEM tool for near real-time anomaly detection and threat hunting. Adding a Security Data Lake lets you retain security data for longer, which enables long-term security log analytics use cases. These might include advanced persistent threat (APT) detection and root cause analysis.
Read: Ultimate Guide to Amazon S3 Data Lake Observability for Security Teams.
5 Steps to Getting Started with a Security Data Lake
Getting started with a security data lake involves choosing the right architecture and software components based on your organization’s unique needs, capabilities, and circumstances. These solutions should make data management easy.
Below, we share some of the key decision points you’ll encounter and our best practical advice for getting started.
1. Choose your Cloud Storage
Modern security data lakes are deployed in the cloud. That’s because public cloud infrastructure offers the most durable, scalable, and cost-effective storage. Enterprise SecOps teams can choose from standalone data lake solutions public cloud providers offer (e.g. AWS Data Lake, Amazon Security Lake, Google Data Lake). Or you can augment cloud object storage like Amazon S3 with a third-party provider like ChaosSearch.
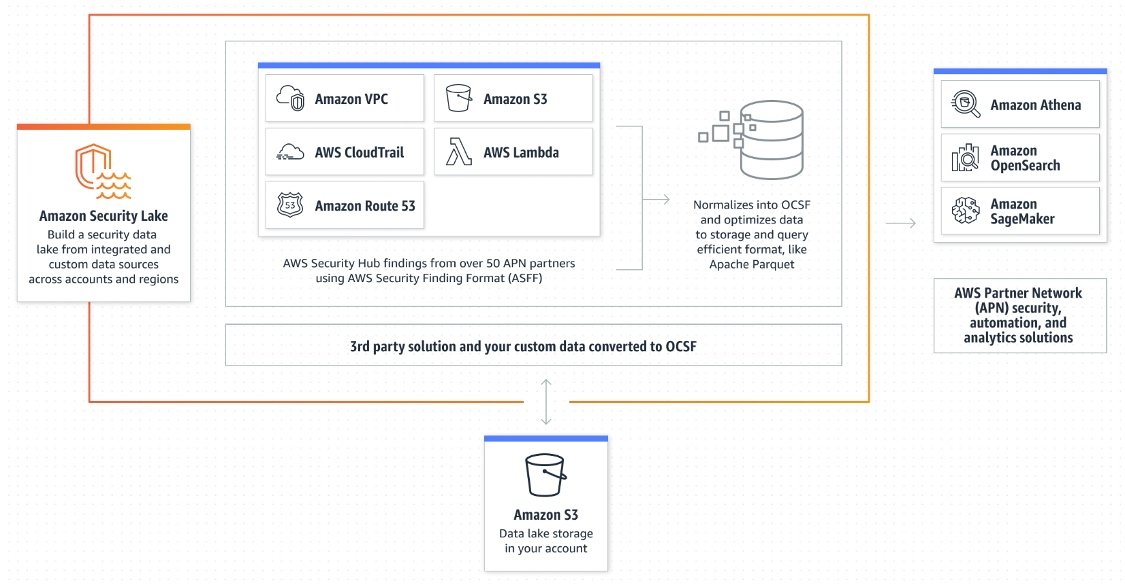
Amazon Security Lake Reference Architecture
When choosing a data lake solution, you should compare solutions in terms of overall complexity and management overhead, total cost of ownership (TCO), and ease of integration with existing systems and data sources.

2. Choose Your Data Sources
Once you’ve chosen a storage solution, the next step is to identify sources of data to collect and analyze. SecOps teams will want to capture security logs and event data from:
- Cloud-based applications and services (including IAM services and network security tools)
- Web servers
- Endpoint devices
- On-prem network infrastructure
- Threat intelligence from public/private feeds or cooperating organizations.
3. Configure Data Ingestion
Next, you’ll need to set up and configure a process for ingesting data from the various data sources. Cloud-based data ingestion tools include:
- Open-source options like Fluentd, Logstash and Apache Kafka
- 3rd-party SaaS solutions like Wavefront
- Public cloud services like Amazon Kinesis.
It’s important to choose a solution that allows you to ingest raw, unstructured data and apply schema at query time. Otherwise, you’ll have to deal with the up-front cost and complexity of transforming your data before it enters your data lake.
4. Catalog or Index Your Data
When you ingest a large volume of security data into your data lake, you should take care to avoid common data lake challenges. For example, you may run the risk of creating a data swamp, or a poorly-maintained storage solution that’s difficult to navigate and analyze. Cataloging or indexing security data as it enters your data lake helps you stay organized and keep track of the valuable data you’re storing.
AWS Glue and Google Cloud Data Catalog are public cloud services that deliver data cataloging capabilities on their respective platforms. You can also implement an open-source tool like Apache Atlas, or take advantage of proprietary data indexing technology offered by third-party vendors like ChaosSearch.
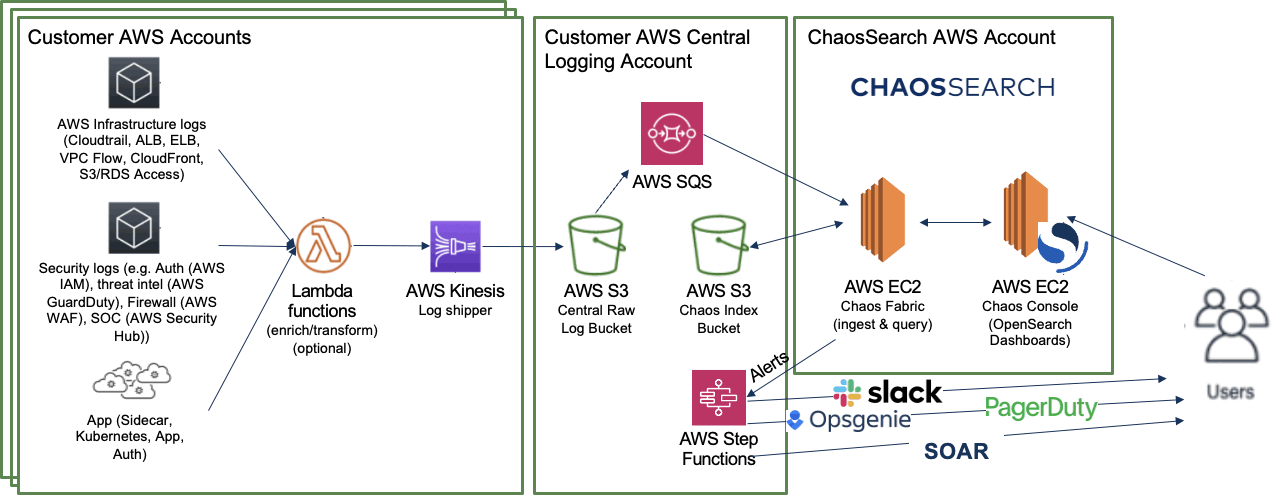
This diagram shows data lake observability data flowing from a variety of sources into Amazon S3 for analysis in ChaosSearch.
5. Connect to Analytics and Visualization Tools
At this point, you should have security logs and other data streaming from your chosen data sources into your data lake platform. The next step is to connect your data lake to analytics, BI, and data visualization tools. These tools will allow you to explore, transform, filter, and analyze the data to gain insights into your organization’s security posture. Ideally, your solution will allow you to analyze structured data, unstructured data, and semi-structured data.
The most sophisticated data lake solutions offer multi-model analytics capabilities. This means you can run full-text search, SQL queries, or ML workloads on your data.

Optimize Your Security Data Lake Architecture
Ready to build your security data lake?
With ChaosSearch, it takes just minutes to collect and analyze your security data. Standing up a cost-effective data lake reduces your SIEM costs and enhances security observability. Best of all? You’ll get unlimited data retention to support long-term security analytics use cases.
ChaosSearch Security Data Lake Reference Architecture
ChaosSearch attaches directly to AWS or GCP, transforming your Amazon S3 or GCS storage backing into a hot security data lake. You can even use ChaosSearch with Amazon express zone for S3 to speed up analytics even further. Once you ingest security logs into cloud object storage, our proprietary Chaos Index® technology indexes the data 60X faster than Elasticsearch and with up to 20X data compression.
From there, you can use our Chaos Refinery® tool to virtually filter, transform, and query security logs. This tool helps you hunt for APTs or investigate the root cause of a security incident. Building your security data lake with ChaosSearch can help you reduce SIEM costs and improve your enterprise security posture. That way, you can analyze a high volume of security data, with low management overhead and TCO.
Ready to learn more?
Want to see just how easy it is to stand up a security data lake using ChaosSearch? Read our ChaosSearch for SecOps Solution Brief to learn more about how ChaosSearch enables scalable log analytics for security operations and threat hunting.

