

In 2009, as the world became increasingly data-driven, organizations began to accumulate vast amounts of data — a period that would later be characterized as the Big Data revolution. While most organizations were used to handling well-structured data in relational databases, this new data was appearing more and more frequently in semi-structured and unstructured data formats.
In addition to relational database management systems (RDBMS), organizations needed databases to support multiple data models -- documents, column-oriented, object-oriented, full-text, graph, and many more. Today, this is known as a multi-model database, but this technology wasn’t always available.
This article looks at today’s definition of a multi-model database, explains why current solutions may not live up to the promise of multi-model benefits or efficiency, and provides a vision for true multi-model data access that will ensure data consistency while reducing the costs and complexity of data processing and analytics.

A Brief History of Multi-Model Database Systems
The big data movement drove rapid evolution and platform proliferation in three technological areas, as organizations adopted specialized processing solutions for each data model:
- NoSQL databases (for example, MongoDB, HBase, Cassandra) for storing and querying of semi-structured and unstructured data in a variety of models
- Search Databases (Elasticsearch, Solr, Splunk) for storing and full-text querying of semi-structured and unstructured data, particularly around log/event data
- Processing engines (Hadoop/MapReduce, and later Spark) for large-scale storing and distributed processing of multi-structured data across a distributed file systems
With the increasing number of models, there was a need to unify this proliferation. This data management unification became known as Polyglot Persistence — the idea that organizations could use multiple data storage technologies to satisfy complex use cases with multiple database models in a single application. Polyglot Persistence worked well for some use cases, but usually had two major drawbacks: increased operational complexity, and a lack of consistency across the multiple data stores.
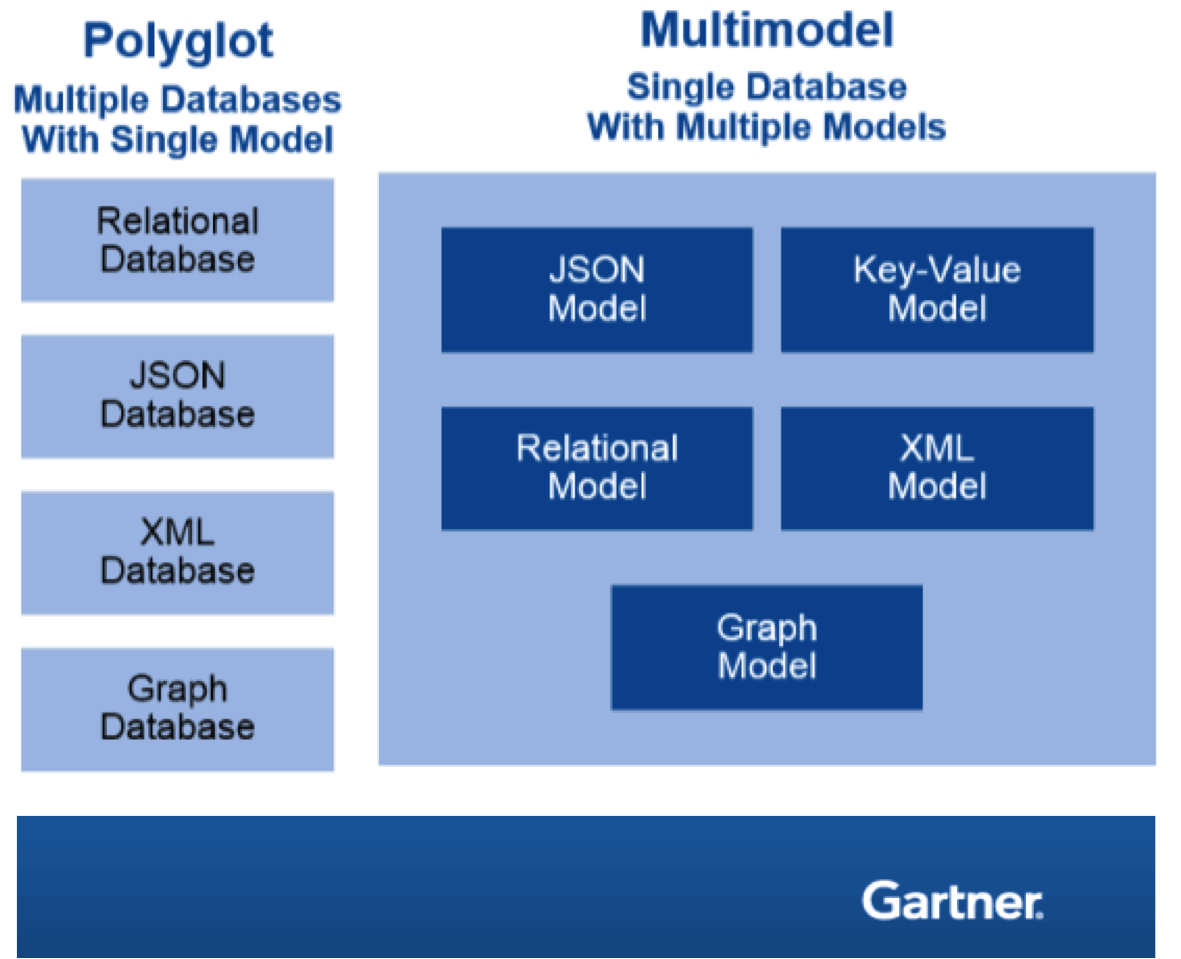
How Gartner defines multi-model databases vs. polyglot (multiple databases within a single model), such as graph databases, relational databases, and more.
As the Polyglot Persistence problem became more widely known, technologists envisioned a single unified database that could support multiple data models, instead of multiple databases. In 2012, the term “multi-model database” was coined by Luca Garulli during his keynote presentation at the NoSQL Matters Conference in Cologne, Germany.
Garulli’s insight was that organizations would benefit from choosing database vendors that supported multiple data models or data formats in the same product, allowing them to choose the right model for each piece of the domain (use-case) with just one database product to learn and manage.
Now, almost a decade later, the database management system (DBMS) marketplace is full of solutions that promise multi-model functionality. However, not all multi-model database solutions are created equal and many fall short of delivering a platform that allows users to store, index, and search/query all data types — while addressing common drawbacks of Polyglot Persistence.
Let’s explore the benefits and drawbacks of today’s multi-model databases.

Today’s Multi-Model Database Definition Isn’t So Clear
A Gartner analyst report published in 2020 defines a multi-model DBMS as one that supports a unified database for different types of data (relational, document, key-value, column-family, etc.).
While this definition does make the basic distinction between multi-model and traditional single model databases, it doesn’t quite set the bar high enough for capabilities that you’d expect from a true multi-model database in 2021. In particular, it excludes full-text search, which is a critical data access model in today’s environment.
Under this limited Gartner definition, we could have two data management solutions that fit the definition of “multi-model” while varying significantly in the data models they support and their viability for enterprise use cases.
Another report from Forrester Research, published in March of 2021, defines a multi-model data platform as one that: “...provides storage, processing, and access to any data, whether structured, unstructured, or semi-structured, and supports multiple data models such as document, graph, relational, and key-value for applications and insights.”
Forrester’s definition is closer to the capabilities we expect from a true multi-model database.
A complete multi-model database should support any and all types of data. That support should include storage, processing, and access. Data should be stored in a single unified database with support for relational, full-text search, and machine learning (ML) queries.
Many of the so-called multi-model databases in today’s market landscape would not truly qualify as such. That’s because most of today’s multi-model databases support very similar models and query types (e.g. SQL and NoSQL query support, but no text search or ML).
Early Multi-Model Database Examples
As enterprise data continued to grow in the early 2010s, problems with data processing silos and the Polyglot Persistence approach became all the more salient for enterprise organizations.
To help address this growing issue, traditional single-model database solutions began to evolve, adding data access and querying support for additional database models.
For example, let’s look at how traditional SQL database solutions started adding support for the JSON data type as NoSQL became more prominent and widely adopted in the early and mid-2010s:
- PostgreSQL 9.2 was released in September of 2012 and was the first version to offer native support for JSON data.
- MySQL added JSON as a natively supported data type with its version 5.7 release in October of 2015.
- Microsoft SQL Server delivered a new release in 2016 with support for JSON data storage, text processing, and additional functions.
- Oracle Database, originally released as an SQL RDBMS, expanded to a multi-model approach in 2012 by adding column storage and native JSON support.
- IBM DB2 added JSON support with its 2013 release of DB2 11 for z/OS.
These changes allowed traditional RDBMS solutions to satisfy emerging semi-structured use cases for multi-model data access, but none of these DBMSs would qualify as a true multi-model database based on our definition. None of these solutions support ever-important search.
Rather, they were purpose-built RDBMS products that later tacked on JSON data support and features. As a result, many of these solutions lack a complete feature set for document storage and querying and are poorly optimized for JSON queries when compared to purpose-built solutions like MongoDB.

Database Systems Store Data in Canonical Format and Expose Data via APIs
As the demand grew for multi-model data access, a new approach to multi-model databases emerged. Instead of tacking on new features and functions to an existing RDBMS, this generation of multi-model tools would store data in a canonical format and expose data in the desired model using APIs.
A well-known example with this style of implementation is Microsoft’s cloud-based Azure Cosmos DB. Cosmos DB stores data in the low-level Atom-Record-Sequence (ARS) format, providing a database engine that can project other common models onto this representation. Users can expose the ARS data as JSON, or use one of several database APIs for data access and querying.
Cosmos DB currently supports the following data models and APIs:
|
Data Model |
Data Access and Querying API |
|
Wide Column Store |
Cassandra API |
|
Graph |
Gremlin API |
|
Document Store |
MongoDB API |
|
Key-Value Pairs |
Azure Table Storage API |
|
Relational |
SQL API |
With support for five data models, both relational and unstructured, Cosmos DB looks like a high-functioning multi-model database -- but a closer look at the implementation tells a slightly different story. These examples of multi-model support are essentially bandaids under the hood that limit functionality to support the actual models themselves. For instance, there are basic relational limitations with Cosmos DB’s ability to support groups by or joins.
Cosmos DB does not actually provide a single unified database with multi-model support. When users create a database instance in a container, they must select the most relevant API for their specific use case at the same time. This determines not only the API language that will be used for access and queries, but also how the data will be persisted in storage.
And because each data model is encoded differently in the storage and index layer, the result is that each containerized database instance can only be queried using one API.
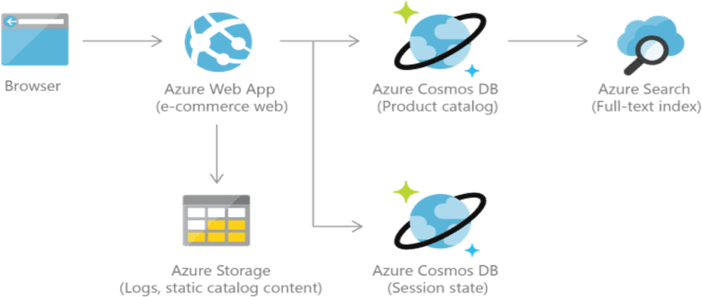
Image Source: A Cloud Guru
Cosmos DB supports multiple data models, but users will need to create a separate database instance for each type of data. This eCommerce order processing pipeline needs two instances of Cosmos DB to get the job done -- one for session state data, and one for the product catalog data. Separating data into separate storage containers creates silos and increases operational complexity.
What you’re left with is a solution that supports multiple data models, but that requires multiple data representations, several query languages, and multiple containerized instances to do it all at once. Cosmos DB also fails to meet our definition of a complete multi-model database, since there’s no unified multi-model database and no support for full-text search or ML queries.
As a result, Cosmos DB doesn’t really work as a true multi-model DBMS -- it fails to eliminate data silos, efficiently enable modern multi-model use cases, or reduce the cost and complexity of database management.
Watch this quick demo to learn how ChaosSearch can help with JSON log analytics:
Native Multi-Model Databases Combine Several Data Formats in One System
As the multi-model data platform approach continues to mature, we’re seeing the emergence of native multi-model databases with storage and unified query support for multiple data formats. Unlike the first multi-model tools that “tacked on” NoSQL functionality to a relational database, native multi-model solutions were purpose-built to support more than one data model.
And unlike tools that use a canonical data model with multiple API access, native multi-model solutions often combine the features of multiple data models into a single representation that can be accessed or queried with a single unified query language. However, there are still limitations.
For example:
- ArangoDB - A native multi-model DBMS with a single query language and support for three data models: key-value pairs, graphs, or documents. But ArangoDB doesn’t support SQL.
- Couchbase - A multi-model DBMS with native data processing support for key-value pairs and JSON documents, and partial (not full) text search.
- Redis - A multi-model DBMS with native key-value capabilities and support for JSON document, graph, time series, full text search, and artificial intelligence (AI). But Redis lacks its own query language and offers a limited range of queries with basic operators.
- OrientDB - A native multi-model DBMS with support for graphs, documents, and key-values. OrientDB integrates many supported data types at the core level, but offers multiple data indexing options that vary in capabilities and performance for each data type. Some of these indices don’t perform well with certain data types, so users will need to reindex the data (added cost and complexity) to support novel use cases.
Native multi-model solutions have genuine potency when it comes to enabling multi-model data use-cases that fit with their capabilities and supported data models -- but these solutions still fall short of satisfying our true multi-model database definition.
Why None of These Solutions Fit the Multi-model Definition
There are many different data platforms that are marketed as multi-model solutions, yet they vary widely in solution architecture, implementation, ability to support diverse data types and use cases, and the extent to which they truly eliminate data silos and complexity.
Multi-model systems are maturing rapidly, but none that we’ve reviewed here qualify as a true multi-model data solution that can fully support all data models and deliver high-performance searching/querying that enables novel multi-model use-cases. It’s time for the emergence of a true multi-model database that enterprise organizations can trust to deliver on Luca Garulli’s original definition.

3 Key Capabilities of a True Multi-Model Database
To imagine what a complete solution might look like, we’ve created an outline of the three key capabilities we’d expect in a true multi-model data solution. A platform with these capabilities will fully support modern business use cases, empowering enterprise organizations to drive down their data storage costs, eliminate data silos, and reduce the operational complexity of database management.

Here are the key features we’re envisioning for the next generation of multi-model databases.
1. Storage for Any/All Data Models
A true multi-model database should have the ability to store any/all structured, semi-structured, and unstructured data types in a single database.
2. A Single Data Representation & Index
A true multi-model platform should store all data types in a single representation with a single index. A true multi-model database should not have to move, copy, or reindex data to support a variety of use cases.
3. Support for Relational, Full-Text Search, and Machine Learning Queries
A true multi-model database platform should support foundational full-text search, relational and machine learning queries (including support for multi-modal LLMs or generative AI) on the same data representation. All additional models can be derived from said core models.
These capabilities empower multi-model DBMS users to unlock the full value of their data, with full-text search for arbitrarily hunting for the unknowns, relational queries for accessing known quantities, and machine learning queries used to discover useful data and apply it to predictive analysis.
Future-Proof Your Enterprise with a True Multi-Model Platform
A data management solution that delivers on these true multi-model database capabilities will empower organizations with the agility and flexibility to tackle complex use cases while reducing data storage and compute costs, knocking down data silos, and without compromising on efficiency or ease-of-use.
This vision is driving ChaosSearch to pave the way toward the future of enterprise-class data management. Our Chaos LakeDB solution delivers multi-model support for the most critical and diverse data access models needed by today’s businesses: full-text search across multi-structured data sets (including, most commonly, log data), relational analytics using SQL, and support for generative AI.s. It can also be used as a modern embedded database for those with highly sensitive or real-time workload requirements.
Are you ready to experience the world’s first true multi-model platform?

