

Preface: Imagine a lake database that can automatically consume streams of structured, semi-structured, and unstructured data and allows for unified intelligent search and analysis - glimpse of the future with high-fidelity.

High-Fidelity Descriptions - Text, Image, & Audio data sources
As we venture deeper into the data-driven era, the traditional systems we have employed to store, search, and analyze data are being challenged by revolutionary advancements in Artificial Intelligence. One such groundbreaking development is the notable advent of Large Language Models (LLMs), specifically those with Multi-Mod[a]l abilities (e.g., Image & Audio). These unique models, equipped to consume, understand, and generate not only text, but images and audio, are poised to dramatically reshape the data management landscape. Here at Chaos, we have been at the forefront of handling massive volumes of live data streams (e.g. terabytes to petabytes), enabling companies to transform their Cloud Object Storage (e.g. S3 & GCS) into a cutting-edge Multi-Mod[e]l interfaces (e.g. Search & SQL) lake database. Today, we are peering into the future — one where multi-modal LLMs might transcend the need for traditional vector databases.
Unpacking Vector Databases
To understand the magnitude of this shift, it's crucial to first unpack what vector databases are and why they've been essential. Vector databases have served as the backbone for handling multimedia data in systems that rely on Machine Learning (ML) for search and analysis purposes. They work by converting such content into vectors — numerical forms that models can understand and process. These databases allow for normalization and sophisticated operations like similarity search, which is fundamental in image and audio recognition systems (i.e. search across text, images, and audio as if they were one type).
Advances in Multi-Modal LLMs
However, with the emergence of advanced LLMs that can interpret and generate high-fidelity descriptions of images, audio, and more, we're not just looking at an alternative to vector databases; we're witnessing a potential replacement. These multi-modal LLMs, such as OpenAI's recent ChatGPT-4, are game-changers for several reasons:
- High-Fidelity Descriptions and Generation: Multi-modal LLMs excel at creating rich, contextual, and highly accurate descriptions of multimedia content. This isn't just about recognizing an object in an image; it's about comprehending the scene, the interactions, and even the sentiments conveyed. For audio, it's not just transcribing spoken words but understanding tone, and emotion, as well as underlying implications. This depth of understanding goes beyond what vector databases offer in their numerical, context-less formats.
- Contextual Understanding and Interactivity: Beyond basic/passive analysis, such LLMs can intelligently interact with users, providing clarifications, elaborating on details, or even generating multimedia content based on textual descriptions. Imagine asking a system to search for images of "peaceful, sunlit forests" or "calming instrumental music," and it comprehends the subjective terms "peaceful" and "calming" in producing full-text search queries that retrieve the exact content needed.
- Simplification of Infrastructure: Employing vector databases necessitates several additional layers of complexity in your tech stack, where vectors can become out-of-date as the model changes, as well as the accompanying maintenance such systems demand. In contrast, an LLM-integrated search database can serve as a unified platform for storing, searching, analyzing, and allowing for the normalization and generation of content across various modalities. This not only streamlines the infrastructure but also cuts down on the operational costs and overhead associated with maintaining multiple systems.
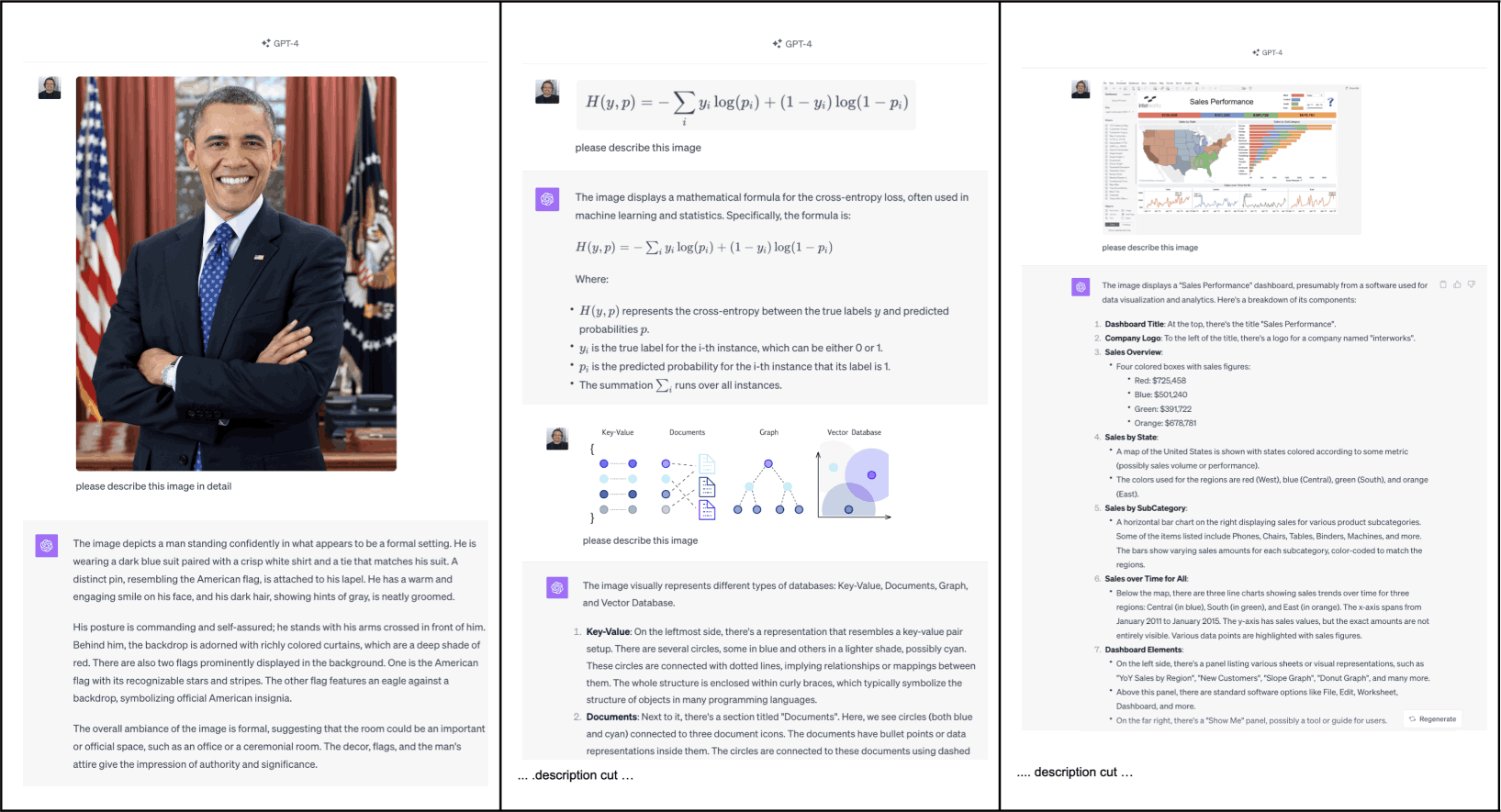
High-Fidelity Descriptions - Persons, Mathematics, Visualizations
The future of interoperability could be natural language, not unintelligible or proprietary protocols. In other words, it is often said a picture is worth a thousand words. Translating images, audio, even videos into high-fidelity descriptions indexed in a text and semantic search manor where the LLM not only provides textual conversation, but also a reasoning engine to ask deep & rich questions (i.e. queries) on a non-hallucinating consistent and economical database. And finally, given these advancements, what might the future hold for a multi-model (i.e. Search and SQL) databases in the context of multi-modal LLMs integration?
Next Generation Databases
First, we'll see a shift from conventional data retrieval to context-aware, intelligent search and interaction. Search queries can now leverage such high-fidelity content, greatly improving results, ultimately providing insights and relevant content extrapolations across text, image, and audio. For instance, a search about a historical event might return a succinct summary, as well as relevant documents, images, and audio clips of famous speeches associated with that event, all textualized by the LLM initial high-fidelity descriptions.
Second, the role of search databases will expand to include content creation. As LLMs move towards the ability to generate high-quality images and audio beyond just text, such lake databases will both store and locate content for creative and generative purposes. Marketing teams, content creators, even educators might use these systems to generate initial drafts, visual concepts, or educational materials, significantly speeding up their workflows — multi-modal input with multi-modal output, bookending a multi-model lake database.
Lastly, with the addition of SQL, a database creates a powerhouse of data interaction, vastly enhancing the accessibility and intelligence of information retrieval. This composite system integrates indexing prowess of a text search database, with the potent Structure Query Language, and the multi-modal interpretative genius of LLMs, form a unified data ecosystem that's incredibly potent.

This synergy also facilitates a new level of data democratization within organizations. Professionals across various departments can leverage such a composite system without needing expertise in SQL querying or deep understanding of search algorithms. A system that breaks down technical barriers, allowing users to interact with databases as intuitively as they would converse with a colleague.
In essence, the convergence of multimodel lake databases with multimodal LLMs (no fine-tuning required) represents the next frontier in information interaction. It amalgamates the strengths of each component where the leaning is on more cost-efficient and scalable databases versus LLMs, promising organizations an unparalleled solution for data-driven decision-making, fostering innovation, and enhancing operational efficiencies. This is not just an upgrade; it's a reimagination of what's possible with data.
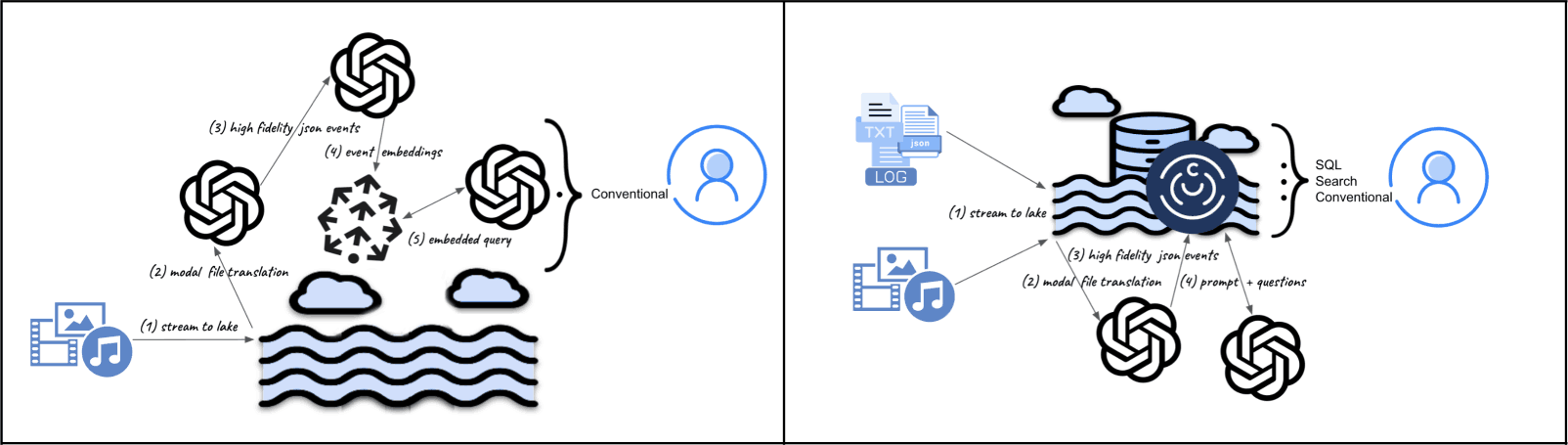
Information Flow - Before (LLM heavy) versus After (LakeDB heavy)
It is often the case where there are streams of data (e.g. media feeds like Twitter or Linkedin) where data is a combination of text, images, and even video and there is a need to efficiently store, reference, as well as analyze the content for an application or service. Let's say sales and/or marketing teams want to know trends of influencers or leaders in a company. Converting posts into embeddings to either be indexed in a vector database to argument an LLM like the above left diagram, or actually use vectors as the means to fine-tune LLMs — can be daunting at best. But what is more problematic with such techniques is an LLM inability to give analysis of the data. It can ask a question like "Who is Mr. Barack Obama and what are his interests in general"... assuming there were no hallucinations. However, it cannot indicate what he did last week or last month, or list the "top-n interests" over the last year. For this, databases do extremely well. If one would try this within an LLM (fine-tuning or vector database hybrid), it would be extremely expensive and would result in "overfitting" or at worst "catastrophic forgetting" each time a new post is consumed. What is needed is a true multi-model lake database where posts are naturally streamed in for persistence, indexed (as-is or high-fidelity text) where an LLM is seen as a reasoning engine to ask intelligence queries orchestrating chain-of-thought with Search and SQL execution.
Conclusion
At ChaosSearch, our mission has always been to empower organizations to gain insights from their data, irrespective of volume or format. As we look forward, we're excited about the possibilities multi-modal LLMs present in enhancing our platform's capabilities. The future of data is not just about bigger volumes or faster processing; it's about deeper understanding and seamless interaction across various forms of content. With multi-modal LLMs and our multi-model database, we're stepping into a future where data lakes are not just repositories of information, but intelligent platforms for discovery, insight, and creation.

