

Today’s enterprise networks are complex. Potential attackers have a wide variety of access points, particularly in cloud-based or multi-cloud environments. Modern threat hunters have the challenge of wading through vast amounts of data in an effort to separate the signal from the noise. That’s where a security data lake can come into play. Having the right data observability tools and observability integrations could mean the difference between identifying the root cause of a threat and potentially missing an attacker that’s already infiltrated your infrastructure or applications.
Some dedicated security observability solutions like Security Information and Event Management (SIEM) platforms can be effective “smoke alarms,” alerting SecOps teams to potential threats as they emerge in real-time. However, given the volume of logs and system event data, and the prevalence of advanced persistent threats, it may be more effective to complement a SIEM with an additional data lake observability platform targeted at identifying the root cause (vs. alerting alone).

As threats and attack vectors multiply and increase in complexity, it is essential to store data longer and to bring in more data sources. A security data lake can help teams sift through the noise, investigate, respond, and mitigate real threats as they emerge, as well as look at the entire lifecycle of an incident comprehensively. On top of that, a flexible layer of automation can drive analysis of the many data sources in a security data lake, assess risk, and engage security teams when necessary to provide human review of conditions.
Let’s look at two different options for security data lake observability in Amazon — one with Amazon Security Lake, and one using tools alongside Amazon S3 you may already be familiar with.
Data Lake Observability with Amazon Security Lake
Amazon Security Lake is a security analytics solution by AWS that centralizes security data into Amazon Simple Storage Service (Amazon S3). This allows security teams to use cost-effective cloud storage without compromising on data retention. It's essential for managing security operations and identifying advanced persistent threats.
The platform utilizes AWS Lake Formation to set up security data lake infrastructure in the organization's AWS account, giving full control over both cloud and on-premises security observability data. It centralizes, aggregates, normalizes, and analyzes security data from various sources within and outside the AWS environment. This aims to provide real-time visibility and actionable insights for responding to security threats and vulnerabilities.
How Does Amazon Security Lake Work?
Amazon Security Lake collects and processes data lake observability data from multiple AWS services, such as AWS CloudTrail, Amazon VPC Flow Logs, AWS Config, and AWS Security Hub. These services generate extensive metrics, logs, traces, and events, which are efficiently managed by centralizing them into a unified repository.

This diagram shows how to set up a data lake for observability using Amazon Security Lake (Source: Amazon).
By consolidating data from various sources, including outside SaaS providers and on-premises systems, Amazon Security Lake creates a single source of truth for security information. It uses AWS data lake architecture for scalable storage and processing, effectively handling the large volumes of data stored.
A key feature is the adoption of the Open Cybersecurity Schema Framework (OCSF). Many enterprises use multiple tools with proprietary logging formats, leading to challenges in data normalization and management. OCSF standardizes security data formats, improves data lake observability and data quality, and eases bottlenecks for security practitioners and data engineers alike.
Integrating Observability Into Amazon Security Lake
While Amazon Security Lake does help aggregate and normalize security data, security teams still need an analytics engine for proactive security engineering and threat hunting. Let’s explore how to threat hunt in Amazon Security Lake as an example.

To conduct threat hunting in Amazon Security Lake, you need to connect your S3 bucket with an external partner for data analysis. For instance, integrating Amazon Security Lake with ChaosSearch will allow ChaosSearch to index the Security Lake S3 files. This integration enables you to monitor and analyze your security data at scale while reducing the operational costs of text search and relational analytics.
Many teams analyze VPC Flow Logs to detect potential threats in network traffic. By using a VPC Flow Dashboard in ChaosSearch, you can monitor this traffic, with the underlying data coming from Amazon Security Lake. If suspicious patterns are detected, you can use ChaosSearch for further investigation and data lake observability.
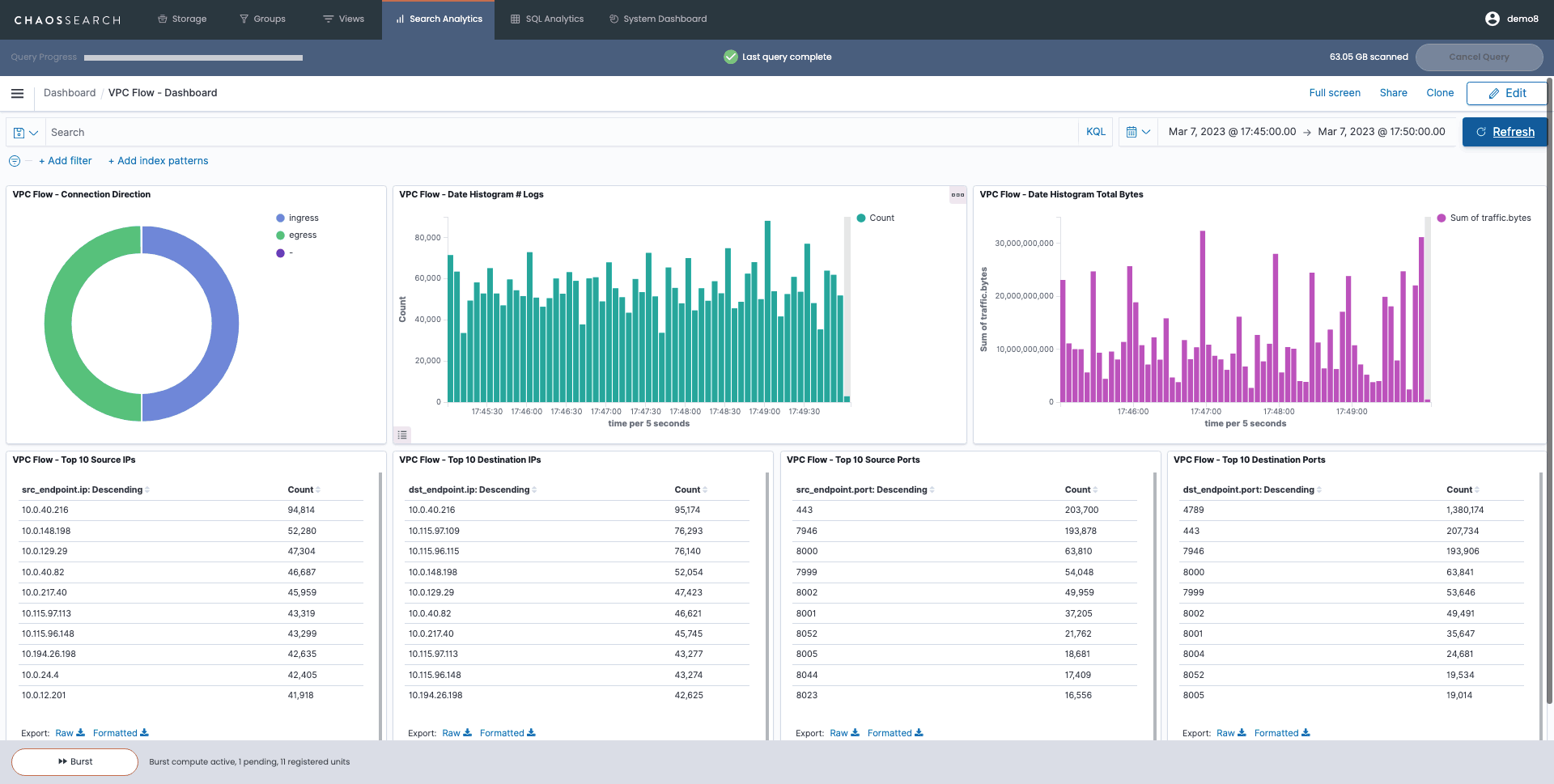
An example of a VPC flow logs dashboard in ChaosSearch, an important data lake observability tool for analyzing network traffic.
A Data-Driven Approach to Data Lake Observability in S3
If you use Amazon S3, it’s easier than you think to create an effective data lake observability pipeline for a security data lake. By leveraging S3 and integrating observability capabilities through ChaosSearch, you can build a security data lake with the ability to index data directly in cloud object storage. This can be done at petabyte scale with disruptive economics and performance.
In case you’re unfamiliar, ChaosSearch indexes data directly in Amazon S3 and writes a highly optimized index back into your S3. Unlike a data warehouse, the platform indexes and provides the ability to query your data from a stateless compute fabric in proximity (the same AWS region/availability zone) of the centralized source bucket.
See How BlackPoint Cyber Reduced Observability Costs by 80%:

This produces two key benefits: reduced latency for reads/writes of data to S3 and no egress/networking costs. The ChaosSearch architecture is enabled via an IAM Policy allowing read-only access to the source data bucket(s) and writing access to a bucket where it can write the ChaosSearch index data. ChaosSearch does not store any of your data and employs a highly scalable stateless compute fabric to meet indexing and query demand at any scale.
The ChaosSearch index is a complete representation of the source data. Once data has been indexed, the source data can be sent to Glacier or other lower-cost storage tiers or even deleted. The ChaosSearch index can be up to 90% smaller than the source data. This index is accessible from the OpenSearch Kibana in ChaosSearch, remotely via API (OpenSearch, SQL/JDBC) or Grafana via the OpenSearch plug-in.
What is the Best Cloud Monitoring Solution for Security?
Many organizations use a best-of-breed approach to cloud monitoring. For example, security teams may use a SIEM or security orchestration (SOAR) solution for monitoring. On top of that, they may layer in a security data lake setup like the one described above for deeper data lake observability and investigation capabilities. This combination provides the best of both worlds and can provide true observability vs. monitoring.
Some teams choose to use emerging tools as an alternative to a SIEM, such as an XDR data lake. Adding an XDR to your data lake provides comprehensive monitoring of an organization’s entire attack surface, including endpoint devices and cloud infrastructure outside the enterprise network perimeter. Broad visibility means that an XDR can identify more patterns in observability data to detect potential threats. The goal is to help security teams correlate seemingly disconnected events, to take immediate action and mitigate cybersecurity threats.
Regardless of the tools you use, you can still centralize your security data in S3. Having the right response workflows can improve data lake observability. Let’s explore one way to make the most of the data flowing into your Amazon S3 instance with AWS Step Functions and ChaosSearch.
Using AWS Step Functions with ChaosSearch for Security Observability
AWS Step Functions, or Amazon’s serverless visual workflows for distributed applications, can provide a way to automate portions of your security team’s response workflow and leverage other best-of-breed tools to communicate, track and manage these investigations.
AWS Step Functions can be utilized to build on the value of the data streaming into the ChaosSearch data platform. The goal is to automate and integrate with other complementary systems, which is what makes the data lake philosophy so powerful, to begin with. An incident management workflow should be simple for busy SecOps teams and leverage the tools they already use whenever possible.
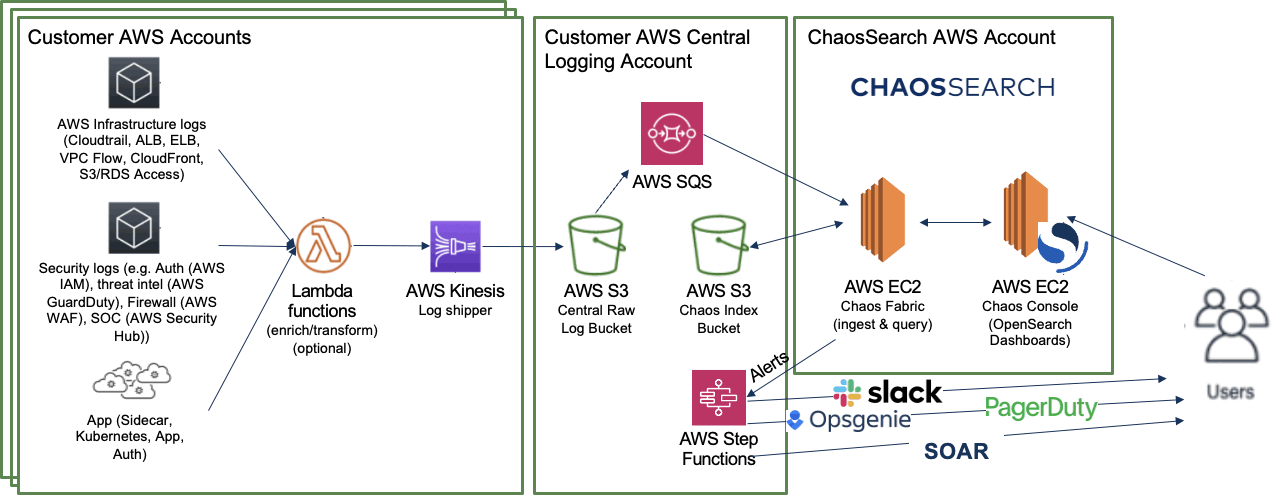
This diagram shows data lake observability data flowing from a variety of sources into Amazon S3 for analysis in ChaosSearch.
ChaosSearch has embedded alerting through an OpenSearch Kibana integration, which has the ability to query and alert when certain conditions are met. In addition, ChaosSearch can integrate via webhook with any system that has an accessible RESTful API (Slack, Microsoft Teams, Amazon Chime, AWS SNS, PagerDuty, ServiceNow, Jira, Salesforce, Zendesk, etc.) to capture alerts where your team is already working.
READ: How to Create a Dashboard in Kibana.
ChaosSearch can Monitor and Alert/Trigger via webhook with Monitor queries that you specify on thresholds or patterns in the data you define. Here are some example Monitors:
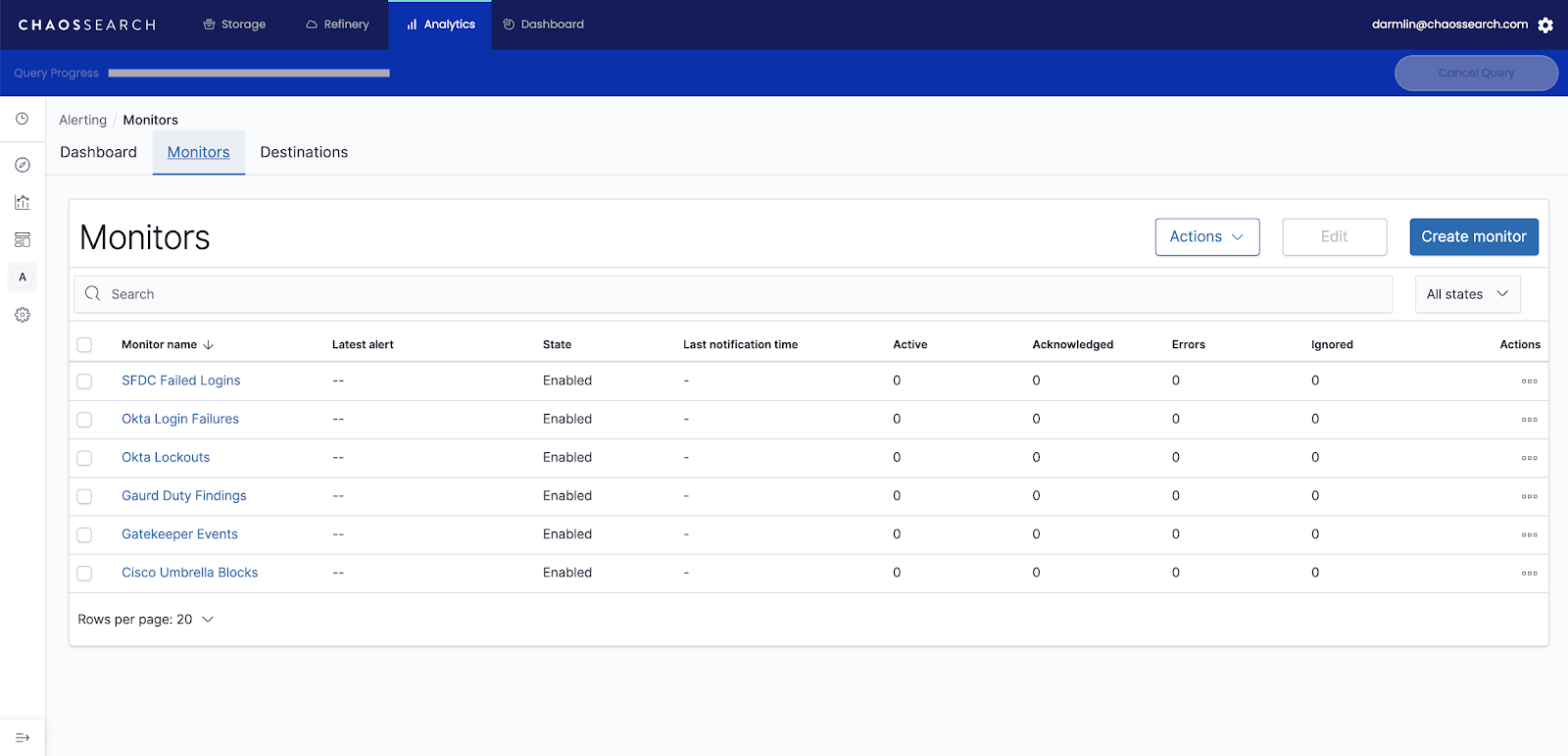
Example monitors set up in ChaosSearch can help detect threats and send them to security teams for incident response.
Consider the data lake architecture you might employ to automate and assess risk based on multiple streams of data and trigger an investigation based on a specific set of events. When the risk threshold has been exceeded, a ChaosSearch Alert will trigger Step Functions to kick off the incident response workflow.
WATCH: ChaosSearch Alerting Overview.
A starting point for the AWS Step Functions workflow would include:
- Notifications to the SecOps team (Slack or Microsoft Teams, SNS, Amazon Chime Chat)
- Creation of an incident in your Incident Management Platform (Jira, OpsGenie, ServiceNow, etc.), which would also kick off any workflow that exists in these platforms
Additions to the security workflow could include:
- Automated remediation steps on anything that is actionable from the data and updates to systems and entities involved
- Scheduled automated checks on incident and systems status
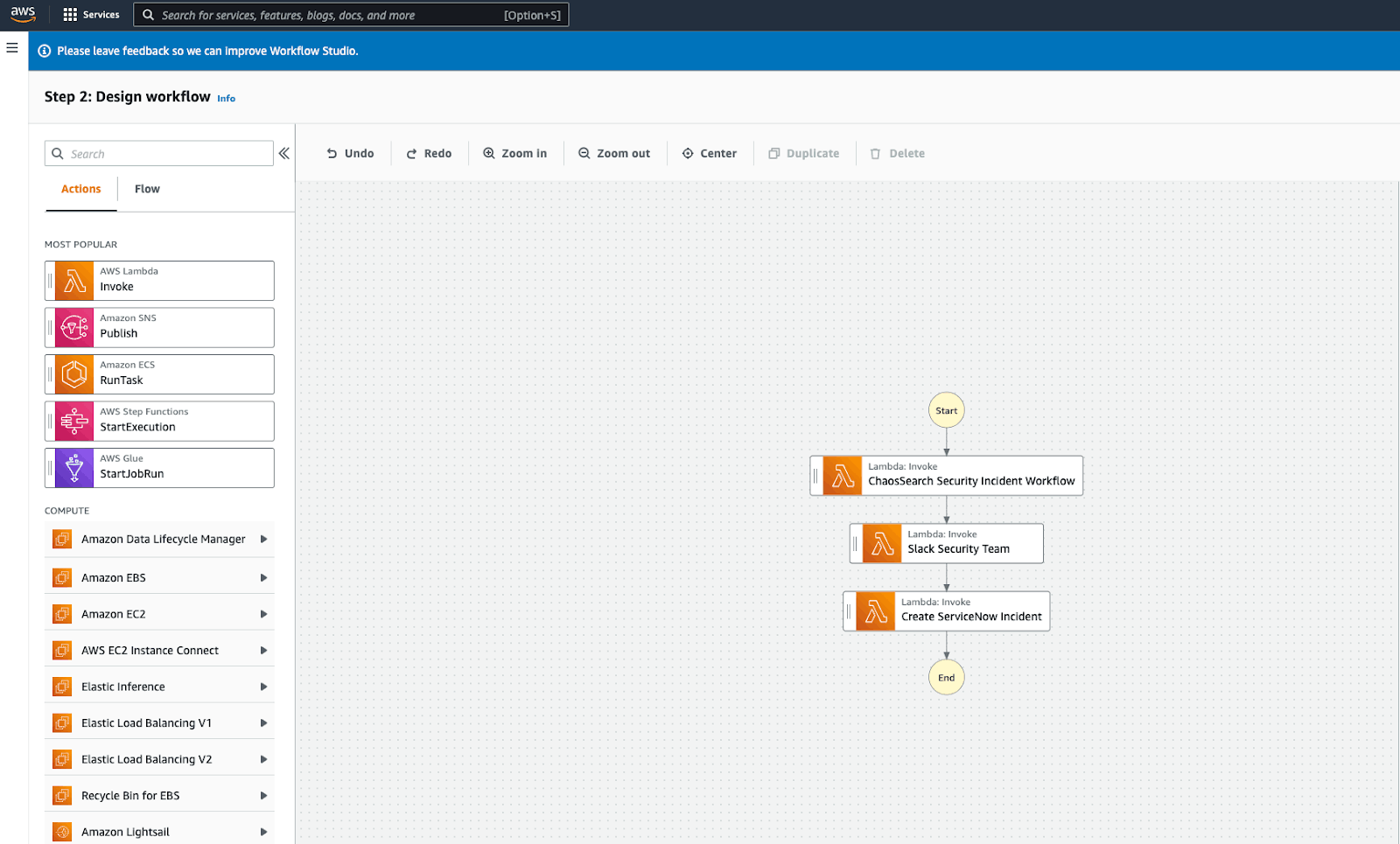
Designing a security observability workflow using AWS Step functions.
Maximize Your Log Data with Integrated Data Lake Observability
ChaosSearch provides the ability to centralize all security logging and event data in low-cost cloud object storage. The platform allows powerful yet flexible automation and integration capabilities, enabling the use of AWS Step Functions and other systems. In the end, ChaosSearch enables SecOps teams to use the tools they already know and love while deepening their investigation capabilities on more expansive volumes of data. This style of proactive threat hunting can ultimately save teams from the cost and reputational damage resulting from a data breach or advanced persistent threat.
See how BlackPoint Cyber solved security observability challenges in S3

