

Streaming analytics is an invaluable capability for organizations seeking to extract real-time insights from the log data they continuously generate through applications and cloud services.
To help our community get started with streaming analytics on AWS, we published a piece last year called An Overview of Streaming Analytics in AWS for Logging Applications, where we covered all the basics.
Now, we’re expanding on this blog with a new piece all about best practices for streaming analytics with S3 and AWS. Keep reading to discover five best practice recommendations that will help you optimize your streaming analytics architecture, reduce costs, and extract powerful insights from your data.

5 Best Practices for Streaming Analytics on AWS
1. Build a Modern Streaming Analytics Architecture
A modern streaming analytics solution on AWS consists of five logical layers, each incorporating one or more microservices that facilitate a specific step in the streaming analytics workflow.

Five layers of a modern streaming analytics architecture.
The five layers are:
- Source Layer - The source layer consists of all applications, devices, and IT infrastructure where streaming data originates. Data sources can include web-based applications, cloud infrastructure and services, mobile games, IoT sensors, and endpoint devices.
- Ingestion Layer - Components in the streaming data ingestion layer function by capturing the data being produced by applications and devices. AWS offers 15+ different services that enable their customers to capture data from diverse sources. AWS IoT Core is used to collect sensor data from IoT devices, while Amazon API Gateway is used together with Amazon CloudWatch to monitor API calls.
- Streaming Data Storage Layer - Enterprise data from multiple sources is collected through the ingestion layer and pushed into the storage layer, which consists of a streaming analytics service like Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, or Amazon MSK. The best streaming analytics service for your business will depend on your specific use case and requirements.
- Processing Layer - In the processing layer, data processing tools like AWS Glue, AWS Lambda, or Amazon Kinesis Data Analytics can process and transform data before sending it to the destination layer.
- Destination Layer - The destination layer is where streaming data is ultimately delivered for storage and analytics. Streaming data destinations on AWS often include database applications like Amazon DynamoDB, Amazon S3 data lakes, Amazon Redshift data warehouses, and event-driven applications.
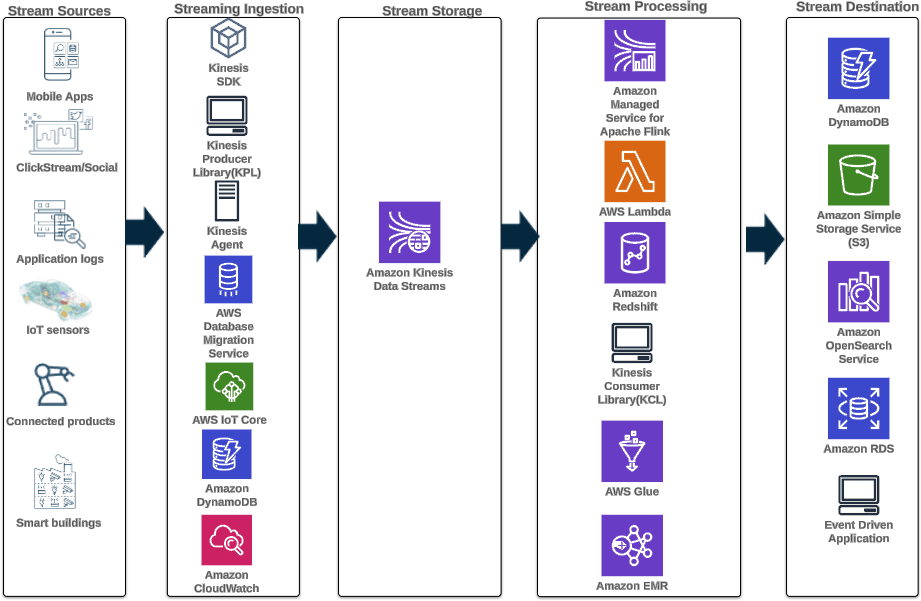
Reference architecture for a modern streaming analytics solution using AWS services.
2. Use Amazon S3 as a Data Lake for Your Streaming Data
After the stream processing phase, streaming data may be sent to a data warehouse tool like Amazon Redshift for SQL/relational querying, to Amazon OpenSearch Service for text-based search, to third-party analytics applications, or to another destination.
But whether you’re tracking user behavior on customer-facing applications, monitoring cloud infrastructure and services, or securing your network, we recommend building a data lake in Amazon S3 to securely and cost-effectively store all of your streaming data in its raw form.
Storing raw data gives you access to long-term analytics use cases, and Amazon S3 is the best choice for a data lake storage backing, thanks to its high availability, unlimited scalability, and low data storage costs.
AWS Lake Formation is a managed service that helps AWS customers set up and manage an Amazon S3 data lake. Lake Formation gives enterprises access to vital capabilities when it comes to managing and administering the data lake. These include:
- Data discovery and cataloging,
- Data cleaning and transformation,
- Secure data sharing,
- Centralized permissions management and access control, and
- Data access monitoring and audit logging.
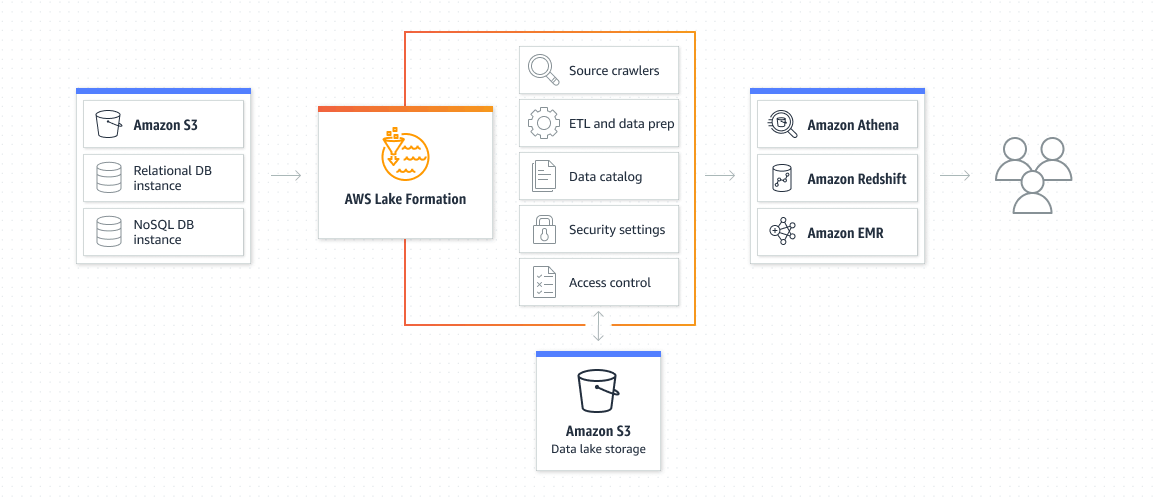
Reference architecture for leveraging AWS Lake Formation to transform Amazon S3 into a data lake.
3. Implement Data Indexing and Compression inside Your Data Lake
Indexing and compressing data after it reaches your data lake is a strategic choice that can help you accelerate query performance, reduce costs, and overcome data retention limitations.
Indexing involves re-ordering, re-structuring, or re-formatting your data to improve the speed and performance of analytical queries. Where vast quantities of data are present, indexing acts as a crucial navigational aid for your analytics engine and allows it to quickly locate specific data points without scanning the entire data set.
Data compression uses specialized algorithms to reduce the size of your data, resulting in faster data transfer speeds and lower storage costs in your data lake. Data compression algorithms remove redundant or unnecessary data, then encode what’s left into a more efficient format that’s cheaper to store.
Modern data compression and indexing technologies like Chaos Index provide up to 20x data compression with no loss of resolution, resulting in faster query times and lower data storage costs.

4. Use Amazon S3 Express One Zone for Low-Latency Applications
Streaming analytics is well-suited for resource demanding or performance-critical applications that demand low-latency data access. The ability to continuously process data in real time as it is created contributes to accelerated insights and faster response times between customer-facing applications and back-end systems.
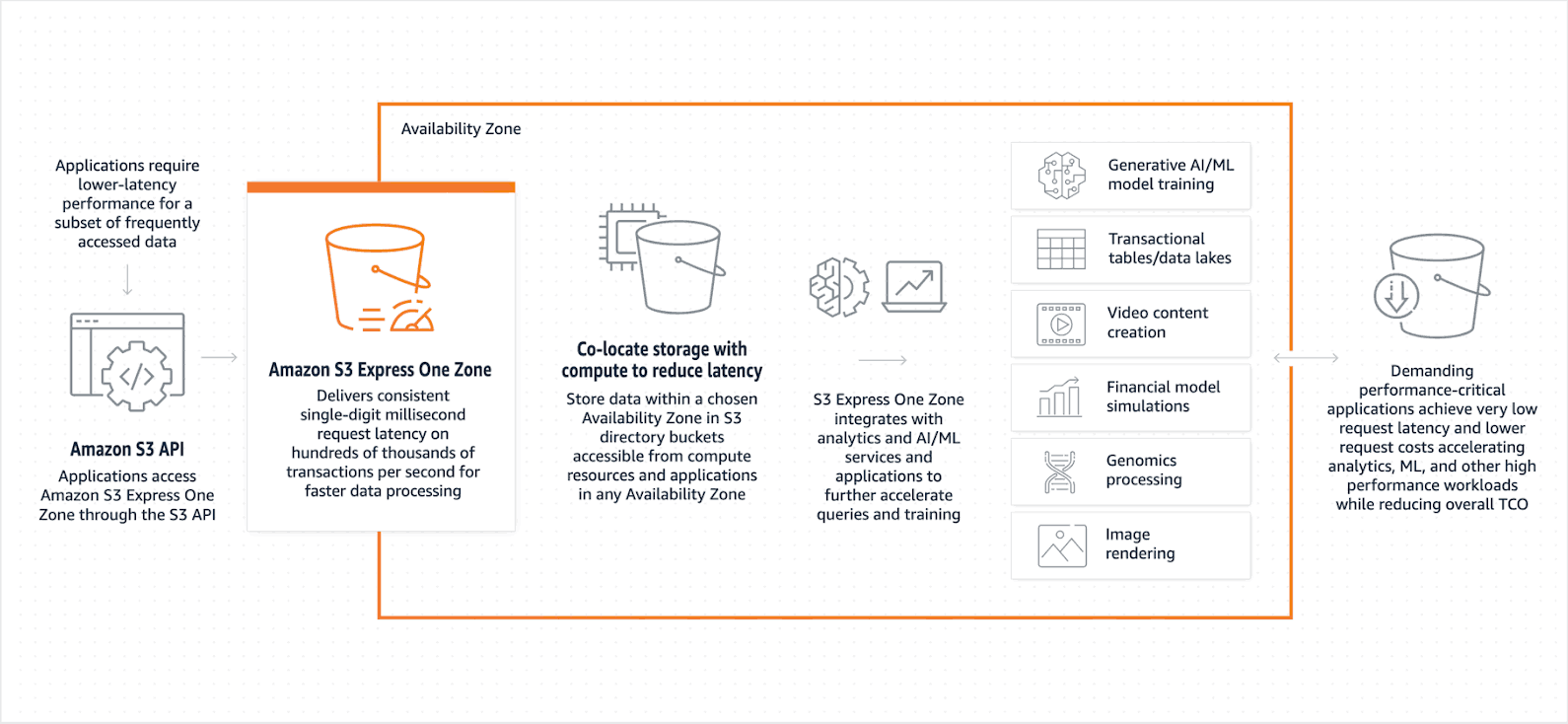
S3 Express One Zone delivers low request latency to facilitate high-performance computing applications like financial modeling and AI/ML model training.
For the most latency-sensitive applications, Amazon S3 Express One Zone is a unique S3 storage class, purpose-built to consistently deliver the fastest possible cloud object storage capabilities. Here’s how it works:
- Colocation with Compute Resources - Other S3 storage classes allow AWS users to choose the specific AWS Region where their data will be stored. Express One Zone goes a step further by allowing users to select a specific Availability Zone within an AWS Region to store their data. Colocating stored data and compute resources in the same Availability Zone results in lower compute costs and faster data access.
- S3 Directory Buckets - Data in S3 Express One Zone is stored in a different type of bucket called an S3 directory bucket. This bucket type was designed to enable streaming analytics at scale by supporting hundreds of thousands of requests per second.
- Session-Based Authorization Model - Requests to S3 Express One Zone can be authenticated and authorized through a session-based mechanism that establishes temporary security credentials to authorize API calls on stored data with ultra-low latency.
According to AWS, Express One Zone can provide data access speeds up to 10x faster and with request costs 50% lower than S3 Standard.
5. Enable Multi-Model Analytics on Streaming Data in S3 with Chaos LakeDB
Multi-model analytics is the capability to analyze and derive insights from diverse data models (e.g. structured, semi-structured, and unstructured) using a single analytics engine.
Enterprises can enable multi-model data access on Amazon S3 data lakes with Chaos LakeDB, the first and only data lake database to enable true multi-model data access with support for:
- Search Analytics - Chaos LakeDB features an embedded OpenSearch dashboard interface that can be used to query and visualize unstructured data in cloud object storage that has been indexed by ChaosSearch.
- SQL Querying - ChaosLakeDB features an integrated version of the Apache Superset exploration and visualization platform, allowing users to execute SQL queries on relational data sets that have been indexed by ChaosSearch.
- GenAI Analytics - ChaosLake DB users can now query their data conversationally with help from a GenAI assistant that can produce novel analysis and actionable insights based on user prompts.

4 Use Cases for Streaming Analytics with S3 and AWS
1. Cloud Observability and Infrastructure Monitoring
Enterprise ITOps teams can use streaming analytics to collect, aggregate, and analyze log data from cloud infrastructure and services in real time. Live visibility of the performance, health, and status of cloud services empowers ITOps teams to effectively monitor cloud resource utilization, quickly detect and diagnose issues (e.g. security, performance, availability, etc.), and optimize costs.
2. Security Operations and Threat Hunting
Enterprise SecOps teams can use streaming analytics to support their security operations and threat hunting programs. Security log data is generated throughout the network, including from enterprise applications, access control services, and security tools.
Some of this data should be transferred to a SIEM tool for monitoring/alerting and short-term storage, but all security logs should be stored in an Amazon S3 security data lake to enable long-term security analytics and advanced persistent threat (APT) hunting for security teams.
3. Deeper Application Performance/User Insights
Enterprise DevOps teams can leverage streaming analytics to capture and analyze user behavior data from customer-facing applications and microservices in real time. With this approach, DevOps teams can gain deeper user insights and shorten feedback cycles to better understand their users and drive improvements to the customer experience.
Storing user behavior data at scale in a cost-efficient S3 data lake can help DevOps teams track and analyze user behavior trends over time.
4. Generative AI
Generate AI is an emerging area of technology that uses deep-learning models to generate novel, high-quality images, text, or audio based on large volumes of training data. Streaming data fed into a Generative AI analytics engine can be used to power conversational chatbots, generate code, automate reporting tasks, create content for marketing or sales, and optimize key business processes.
Optimize Your Streaming Analytics Architecture with Chaos LakeDB
Chaos LakeDB is a Software-as-a-Service (SaaS) data platform for enterprises that transforms your Amazon S3 cloud object storage into a live analytics database with multi-model analytics capabilities and unlimited hot data retention.
With Chaos LakeDB, enterprises can aggregate data streams into one centralized data lake database, automate and adaptively scale data pipelines (eliminating the need for manual intervention), and make streaming data available for immediate querying.
Ready to learn more?
Download our free Chaos LakeDB white paper to learn more about the fundamental database innovation behind Chaos LakeDB, along with real-world use cases and testimonials.


