


Product Highlights of 2019
What a year for CHAOSSEARCH. Last April we announced our new cutting edge platform that reimagined how analytics is delivered at scale. A big data platform, we inverted how analytics should be consumed. A solution without the proverbial issues of time, cost and complexity forever associated with big data. To achieve these advancements, we started with a computational insight, where we neither repurposed platforms such as Hadoop/Elasticsearch or leveraged aging indexing database technologies such as columnar/inverted indices.
We started with new innovation...
The Platform
In 2019, we announced the ability to instantly turn cloud object storage into a unified big data platform. Let me repeat this. We allow customers to transform their S3 into a new analytic database - without data movement or transformation, or even manual schema definition. And unlike a typical database company, our mission is to offer complete solutions where our unique platform enables and streamlines use-cases such as Log Analytics...
The Innovation
The benefits of fusing storage with analytics into one solution will be described shortly. How we did it, is a five year journey. But in summary, we created a new universal data format (index) and associated architecture that allows for direct and accelerated analytics on cloud object storage, making data access UltraHot®.
Let me repeat this again. This is a 100% cloud object storage platform. Not one ounce of block storage (e.g. SSD, HDD) is used to permanently or temporarily store data. We don’t even use complex RAM caching layers. No, this architecture truly (truly) separates storage from compute where storage is pure cloud object storage and compute just needs a few gigs of memory (no expensive hardware).

What does this mean? Why is it important? The simple answer is that the fusion of elastic storage with dynamic compute dramatically reduces cost/complexity of building, scaling and maintaining a solution. The next level down explanation is that traditional databases require expensive/fixed block storage to be deployed with attached compute. All things that are not elastic, simple or cost-efficient.
Even if object storage is leveraged to offset the cost of retention, data is now cold and needs to be ETL-ed out into the same costly/complicated analytic databases. And depending on the use-case, different and siloed databases are commonly employed (e.g. Elasticsearch for Log, Redshift for BI).
In recent years there have been implementations that separate storage from compute. And yet, none of them are pure object storage architected or a true database. As a result, costs are still high or functionality limited, resulting in a continued path of cost/complexity (i.e. not the answer).
The Features
As mentioned, CHAOSSEARCH is a new kind of database. One that singularly leverages cloud object storage, but also uniquely supports true Multi-Model Data Access (MMDA) over the same index representation. This Chaos Index® was the catalyst for our UltraHot® storage access at scale, as well as, the ability to support both Search Analytics (Logs) and SQL Analytics (BI).
However, we wanted to be more than just a database company. We wanted to provide complete end-to-end solutions powered by our database. As a result, we went after what we saw as a problem, log analytics at scale; or more specifically, the cost/complexity of managing the Elastic Stack (i.e. ELK) when data reaches terabytes of daily volume. In these use-cases, a $100K per month bill is normal.
Accordingly, our initial go-to-market in 2019 was as a Log Analytics solution for ELK users, where we remove Elasticsearch, simplify Logstash requirements, and enhanced Kibana (e.g. progress bar and cancel button). But we did not stop there. We also introduced several new features for the ELK community, and are unique to the overall Log Analytics space.
The Management
At our core, we have a Data Lake philosophy. We believe cloud object storage should be used as a centralized location for managing the streams of data any business generates. Today’s logging solutions skip the storage part of the data journey and leave it up to the customer to worry about. At CHAOSSEARCH, we wanted to address this limitation and supercharge it.
As a result, we built the ability to discover what is in your S3 buckets, categorize what we find (as a searchable/queryable index), and allow you to organize objects by an assortment of filter criteria, which we call Object Groups (think virtual folders within a bucket).
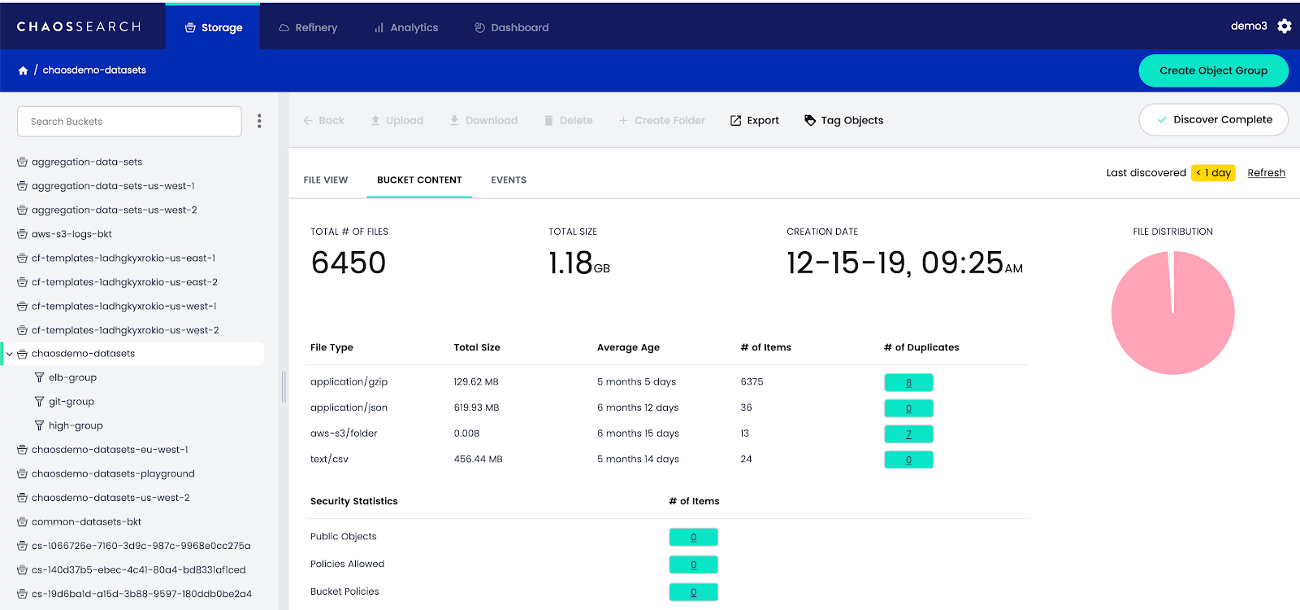
No more of the days when a data lake ultimately become a data swamp. With CHAOSSEARCH one can discover, catalogue and analyze the metadata via one pane of glass. And if you are responsible for getting today's tsunami of diverse data into solutions for analysis, I know you can appreciate the benefits of data management and the above features. But again, we did not want to stop here.
We then took the viewpoint of starting from object storage, with the concept of Object Grouping, and introduced the ability to automatically and instantly index this grouped data in place (no movement) directly within S3 (static or live).
The Indexing
Indexing data in CHAOSSEARCH is where we shine. No more are the problems of bottlenecks getting data ingested into your analytic solution or the complexity of defining and managing schema over time. CHAOSSEARCH automates schema discovery for a given data source (see refinery for dynamically changing) and fully indexes every aspect of a dataset. And with the cost and performance ratio of our Chaos Index, there is no longer a need to reduce what is indexed or worry about reindexing. With CHAOSSEARCH, store and index everything, to ask anything!
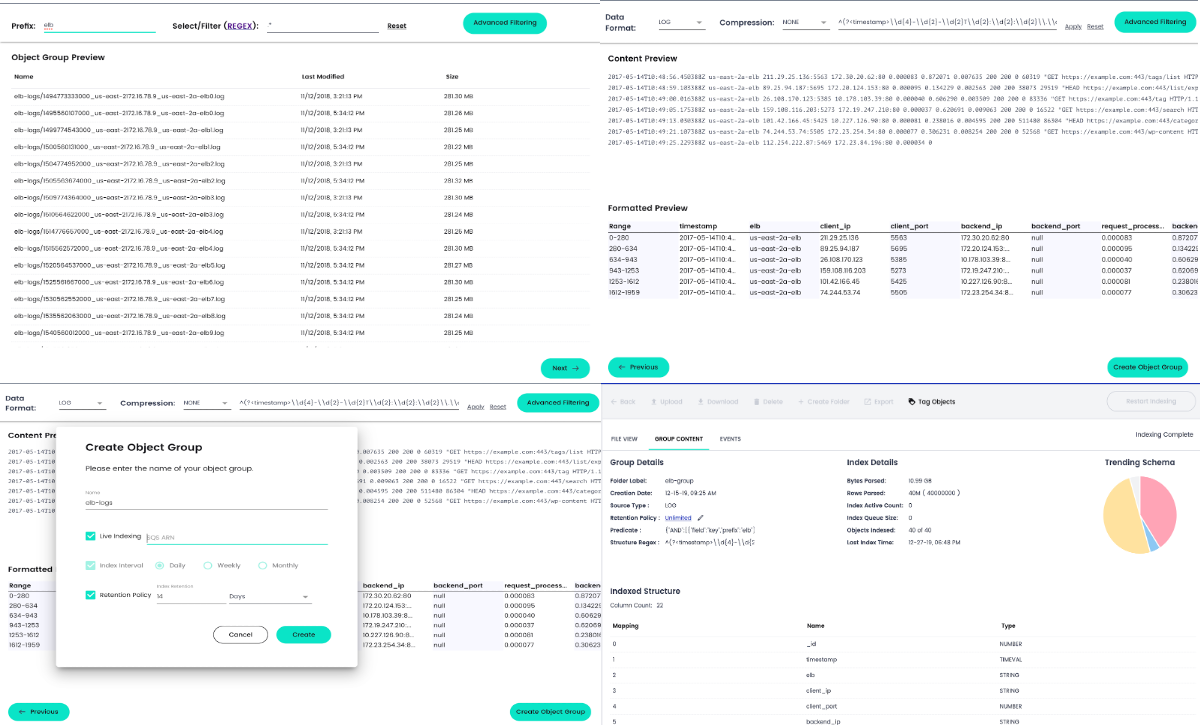
The ability to quickly and easily analyze data begins with the simplicity of indexing. CHAOSSEARCH has uniquely automated this process, and in the coming weeks, we'll be introducing an even more advanced parsing wizard to take this simplicity to the next level.
The Refinery
Refining data (i.e. transforming) is the bane of engineering existence. Cleaning and preparing data to be indexed/analyzed can take up to 60% of their time. Often is the case where additional ETL-ing is necessary as analytic requirements change. When daily volumes are in the terabytes, with months retention, transformations are nearly impossible. And here is where CHAOSSEARCH shines once again.
In 2019, we introduced the first of its kind, built-in refinery, where transforms are virtual and instant. In other words, changing schema is a one-minute exercise by creating a new view on the original indexed data. Or a view that takes one or more attributes and transforms them into one or more new ones. Users can even create views that cross multiple indexed data sources, regardless of schema. All of which, get published as index-patterns in our Elasticsearch compliant API or tables in our up-coming SQL (presto dialect) compliant API.
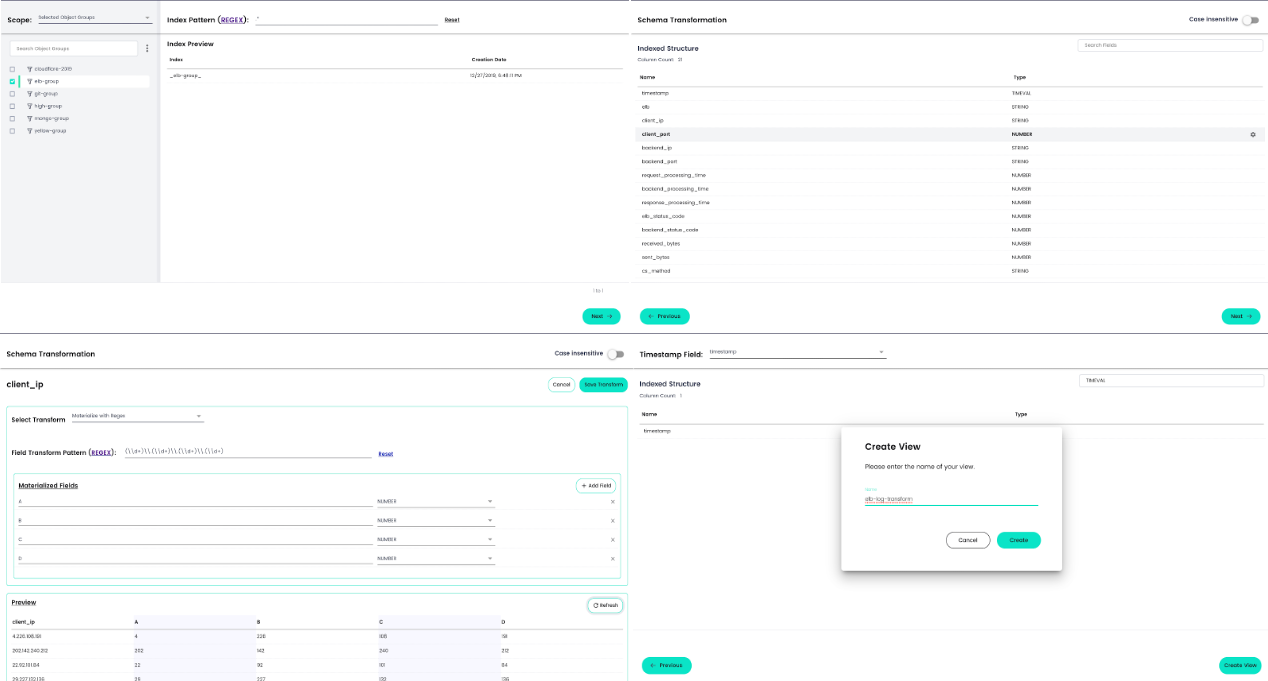
With the CHAOSSEARCH refinery wizard, users can self-serve and publish how they want to consume and interact with data, all without changing the original index (source of truth).
The Analytics
In a world of analytics, visualization is key. As part of CHAOSSEARCH publishing index-patterns and tables to be programmatically search/queried via open and standard API(s), we also integrated the popular Kibana project into our solution, enhancing it (without changing it) along the way. Some of these changes relate to the danger of mistakenly executing a search or query across a range that could make an Elasticsearch cluster very sad. With CHAOSSEARCH, we have added a cancel button, as well as, progress bar to better manage and understand long range search/query analysis.
Kibana is a major and important tool in the ELK community. It has become the defacto standard in Log Analytics. Out of the box, Kibana provides the ability to search for data and visualize it, where these visualizations can be used to create live dashboards for monitoring.
However, in recent years the community has had limited access to new Kibana features. Many of these features are not under an open license. As a result, we have adopted a new Kibana stack in 2019 (see Open Distro Project section).
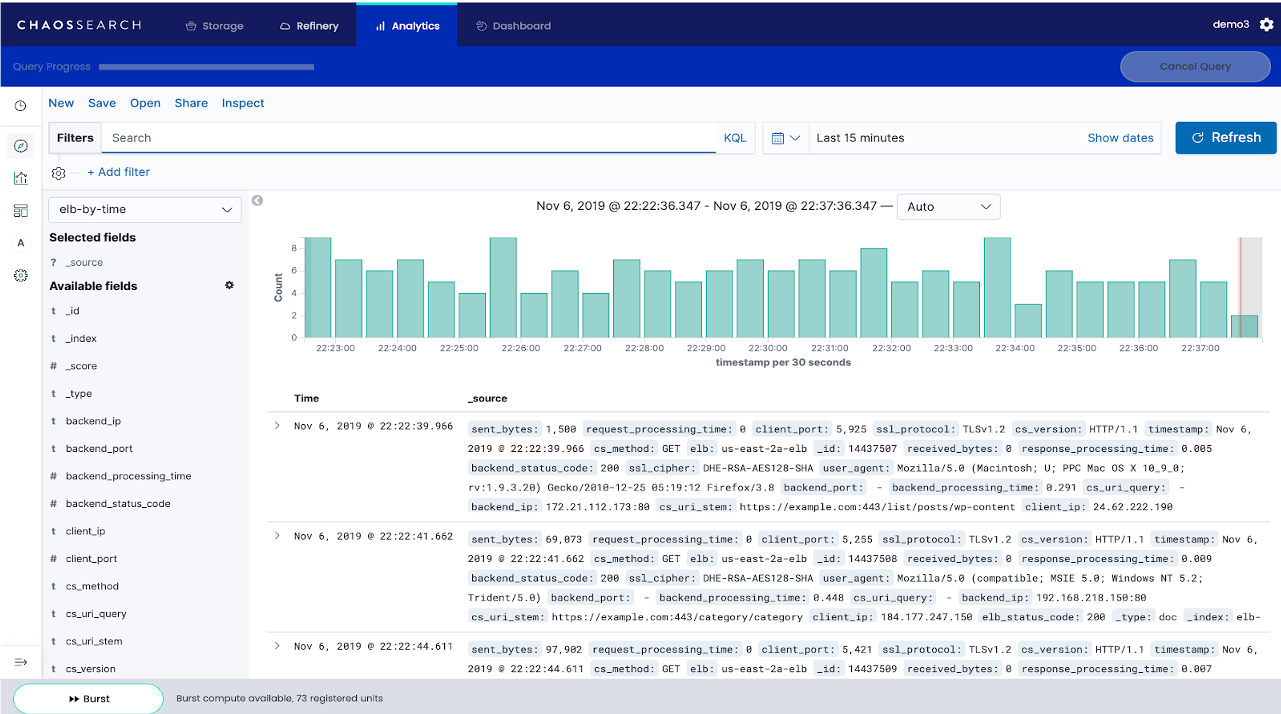
The above image shows the power of the Kibana Discover feature. The ability to search based on arbitrary wildcard semantics with include/exclude boolean logic, and are a must in the log world.
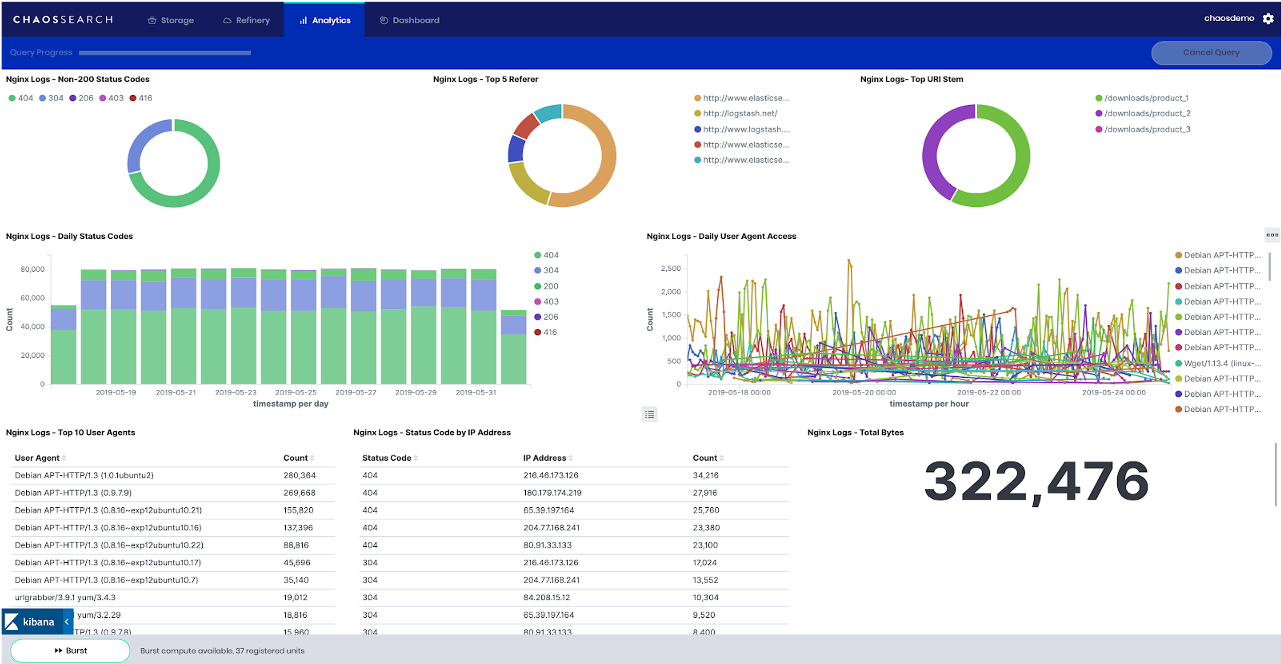
Once you have a handle on what you are looking for, Kibana allows you to create dashboards to visually monitor state and status of your operational data (e.g. ELB, NGINX, Cloudflare, your own Application Logs, etc).
The Dashboard
The ability to monitor a service is the utmost importance to understand what a service is doing. As part of the CHAOSSEARCH offering, we introduced our own dashboard (using Kibana) this past summer. This built-in dashboard shows the amount of data under management, what users are doing within the service, as well as, events associated with indexing, search, and query.
.png?width=648&name=dashboard-screenshot-full-edit-02%20(1).png)
User-Management
As a fully managed service, CHAOSSEARCH also provides multiuser access. It provides a built-in user interface to create accounts, as well as, Single-Sign-On (SSO) via Auth0 support and Okta integration. Ease of service access is just as important as the ease of data access!
Open Distro Project
Another major announcement in 2019 was our adoption of the Open Distro project where we now leverage Kibana 7+. The reasoning was simple, Amazon wanted to keep the ELK community truly open. As a result, we at CHAOSSEARCH integrated this version of Kibana with all its "open" features such as Alerting and Timelion.

As part of this integration, our solution introduced Kibana Alerting/Monitoring this past summer, and in the coming weeks, we will make Timelion available too. Our roadmap continues the build out of new Kibana features as we introduce RBAC in early 2020.
Deployment Options
Out of the gate, CHAOSSEARCH was architected to be both cloud agnostic and delivered as a fully-managed service where easy-of-use and time-of-results was a major priority. The service is currently available in all AWS US and EU regions and we are actively working to bring on-line Asia. Multi-cloud support is scheduled for the second half of 2020. And finally, for those needing the service within their own account, reach out and ask about our VPC offering.
And don't forget to check out our Free Trial.

In Summary
2019 was a big year for both the product and company. Let’s just say we built a hell of a lot of functionality within just 12 months. Our 2020 roadmap is just as meaningful and impactful to our customers and will continue to deliver on Log Analytic use-cases (e.g. ELK).
2019 Results
The past year has certainly proven the power of our innovation and platform. The ability to connect our service to your S3 (within minutes) and begin indexing 10s of terabytes of daily volume and provide UltraHot® access at petabyte scale (while not breaking the bank) has not only impressed our customers, but has hardened our belief that we are truly on to something.
2020 Preview
But what we are really excited to bring out in early 2020 is our support for real-time ingestion. In other words, the ability to receive data not only from S3 and/or SQS, but an actual Elasticsearch PUT. The benefits of this is related to real-time availability of data to be searched/queried and/or alerted/monitored. Data that is consumed in this manner will continue to be stored/accessed in your S3 buckets. The difference is that data is sent to CHAOSSEARCH first versus your S3.
And finally, as mentioned in the opener, we built a new and cutting edge big data platform for analytics, powered by our innovative distributed database. In 2020, we are coming out with a supercharged SQL/JDBC interface via a presto dialect that natively talks to our fabric. This will be the first true Multi-Model Data Access (MMDA) solution in the market, where we not only support big data analytic reads, but also real-time writes (e.g. create, update, and upserts).
Real-time Storage Analytics is coming in 2020... Imagine our plans for 2021

