

Organizations are leveraging log analytics in the cloud for a variety of use cases, including application performance monitoring, troubleshooting cloud services, user behavior analysis, security operations and threat hunting, forensic network investigation, and supporting regulatory compliance initiatives.
But with enterprise data growing at astronomical rates, organizations are finding it increasingly costly, complex, and time-consuming to capture, securely store, and efficiently analyze their log data.
In a recent survey of 200 IT professionals, data engineers, and data scientists at enterprises with 1000+ employees, more than 20% of respondents said their organizations were pulling data from 1,000+ different sources to power their BI and data analytics initiatives (Matillion).
That’s a huge amount of log data that needs to be collected, stored, and indexed before it can be analyzed.
As organizations extend their presence in the cloud and generate an increasing amount of data (e.g. event and security logs, etc.) each day, data lakes are once again being considered by CIOs as an attractive option for data management, storage, and analytics at scale. Data lake solutions can be architected to support cost-effective data storage at scale and expanded data access within organizations (also known as data democratization), leading to increased data utilization, insight generation, and value creation.
In this blog post, we’re taking a closer look at three types of data lake architecture powering the future of enterprise log analytics. We will:
- Explain what data lakes are and describe the four key features that characterize data lake solutions.
- Look at three different approaches to data lake architecture and what makes them effective for storing large volumes of log files for analysis.
- Share our vision for a simple and effective architecture that will help organizations power log analytics initiatives at scale and maximize the long-term value of their log data.
Let’s dive in!

What is a Data Lake and How is it Different from a Data Warehouse?
It was around 2010 when the term Data Lake was first coined by James Dixon, then-CTO of Pentaho Corporation.
At this time, organizations involved with big data analytics were utilizing data warehouses for large-scale storage of processed data.
Data marts were also deployed, enabling individual business units to access warehoused data pertaining to their department.
From Dixon’s perspective, data marts were preventing organizations from reaching their full potential for big data utilization.
Data and information was siloed because each department could only access data in their own data mart, while other areas of the data warehouse remained opaque and inaccessible.
Data marts were also accused of stifling innovation because they presented users with structured data derived from raw data - but not the raw data itself.
A lack of access to raw data, Dixon believed, prevented users from transforming the data in alternative ways to extract new insights or develop new use cases.
Dixon’s concept of a data lake is based on the idea of storing data in its raw form and broadening data access to break down silos and accelerate innovation. Here are Dixon’s own words describing how this concept would differ from a data mart:
“If you think of a Data Mart as a store of bottled water, cleansed and packaged and structured for easy consumption, the Data Lake is a large body of water in a more natural state. The contents of the Data Lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.” (James Dixon)
Today, a data lake is defined as a data storage repository that centralizes, organizes, and protects large amounts of structured, semi-structured, and unstructured data from multiple sources. Unlike data warehouses that follow a schema-on-write approach (data is structured as it enters the warehouse), data lakes follow a schema-on-read approach where data can be structured at query-time based on user needs.
As a result, organizations using a data lake have more flexibility to analyze their data in new ways, develop meaningful insights, and uncover valuable new use cases for enterprise data.
How Does Data Lake Architecture Work?
Data lakes can be designed and architected in different ways. Integrating with existing enterprise software tools, they can deliver the capabilities that help companies store and analyze log files at scale.
Four Key Functions of an Enterprise Data Lake Solution
- Data Ingest - Data lake solutions ingest and aggregate data from a variety of sources. Aggregating data from throughout the organization’s IT infrastructure (e.g. networks, cloud services, applications, devices, etc.) creates a centralized repository where users can access and analyze many different types of enterprise data.
- Data Storage - Data lake solutions require cost-effective storage of structured, unstructured, and semi-structured data with unlimited capacity to scale. The cloud object storage utilities offered by public cloud vendors like AWS and GCP provide the most durable, scalable, and cost-effective storage repository for enterprise data.
- Data Indexing - Data lake solutions should be able to catalog or index data. Data indexing makes the contents of your data lake accessible and searchable, preventing it from degrading into a data swamp.
- Data Analysis - Data lake solutions connect enterprise log data with data analytics, visualization, and business intelligence tools, allowing organizations to analyze their data and extract insights that drive value creation.
Based on these four functions, we identify the key components of data lake architecture.
5 Key Components of Data Lake Architecture
- Data Sources - Applications that generate enterprise data.
- Data Ingest Layer - Software that captures enterprise data and moves it into the storage layer.
- Data Storage Layer - Software storage repository for raw structured, unstructured, and semi-structured data.
- Catalog/Index Layer - Software that catalogs or indexes the data to make it searchable and accessible for transformation and analysis.
- Client Layer - Software that enables data transformation, analysis, visualization, and insight development.
In addition to these five essential components, a data lake solution should also provide mechanisms for implementing data governance policies. These policies can include things like metadata management, data lineage, or role-based access controls.

What are the Three Types of Data Lake Architecture?
How do different data lake solutions incorporate key architectural components to deliver on these critical functionalities?
Most vendors have adopted one of three main approaches to data lake architecture.
Data Lake Architecture: The Template Approach
In 2019, AWS released a new solution known as “Data Lake on AWS”.
This solution uses a template-based approach that automatically configures existing AWS services to support data lake functionality, such as tagging, sharing, transforming, accessing, and governing data in a centralized repository.
The template approach championed by AWS cuts down on manual configuration, allowing users to set up their data lake in as little as 30 minutes.

Image Source: Amazon Web Services
In this architecture, users access the data lake through a console secured by Amazon Cognito (user authentication service). Data is ingested via services like Amazon CloudWatch that capture log and event data from throughout the cloud environment. The raw data is stored in Amazon S3, while metadata is managed in DynamoDB. Data is cataloged with AWS Glue and can be searched using the Amazon OpenSearch service or analyzed with Amazon Athena.
A template-based approach can make data lakes easier to configure, but complexity and IT management overhead are significant issues with data lake architectures that have so many moving parts. Enterprise data engineers may choose to start with a template-based approach, then later improve or optimize the AWS data lake by introducing components and services from 3rd-party vendors.
Read: 10 AWS Data Lake Best Practices
Data Lake Architecture: The “LakeHouse” Approach
A second approach to enterprise data architecture involves combining the features of a data warehouse and a data lake into a hybrid architecture that’s been termed a “Data LakeHouse.”
Platforms like Databricks and Snowflake use this type of architecture, as do some data warehousing services like Google BigQuery and AWS Redshift Spectrum.

Image Source: Medium
In the LakeHouse architecture shown above, you’ll notice many of the same components we’ve already mentioned:
- Data is ingested from a variety of sources in its raw format.
- Data is aggregated in a storage layer consisting of Amazon S3 buckets, Hadoop HDFS, or another cloud object store.
- Data can be queried using Apache Drill or Amazon Athena without moving it out of the storage layer.
- Delta Lake (created by Databricks) provides an additional open format storage layer and allows users to perform ETL processes and run BI workloads directly on the data lake.
- Processed data can be analyzed using external BI/AI applications like Tableau and Project Jupyter.
The lakehouse approach has its benefits, but it also introduces a high level of complexity that can result in poor data quality, and performance degradation.
High complexity also makes it challenging for non-IT users to utilize data, ultimately preventing organizations from reaching the promised land of data democratization.
Watch: The Rise of Data Mesh and Data Fabric Architectures
Data Lake Architecture: The Cloud Data Platform Approach
The third approach - and also our favorite - is what we’d call a cloud data platform architecture.
In this set-up, a self-service data lake engine sits on top of a cloud-based data repository, delivering capabilities like data indexing, transformation, analytics, and visualization that help organizations efficiently manage and analyze their data at scale.
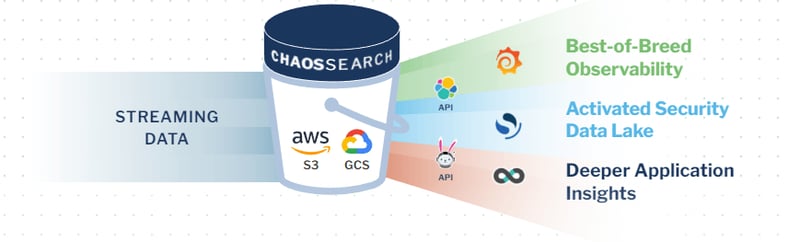
Image Source: ChaosSearch
In the data lake architecture reimagined here, data is produced by applications (either on-prem or in the cloud) and streamed into cloud object storage (e.g. Amazon S3 or Google Cloud Storage) using cloud services like Amazon CloudWatch or an open source log aggregation tool like Logstash.
ChaosSearch runs as a managed service in the cloud, allowing organizations to:
- Automatically discover, normalize, and index data in Amazon S3 cloud object storage at scale.
- Index data with extreme compression for ultra cost-effective data storage.
- Store data in a proprietary, universal format called Data Edge that removes the need to transform data in different ways to satisfy alternative use cases.
- Perform textual searches, relational queries, or execute machine learning workloads on indexed data.
- Effectively orchestrate indexing, searching, and querying operations to optimize performance and avoid degradations.
- Clean, prepare, and virtually transform data without moving it out of Amazon S3 buckets, eliminating the ETL process and avoiding data egress fees.
- Analyze indexed data directly in Amazon S3 with data visualization and BI analytics tools.
ChaosSearch delivers a simplified approach to data lake architecture that unlocks the full potential of Amazon S3 as a large-scale storage repository for enterprise log data.
Read: The New World of Data Lakes, Data Warehouses and Cloud Data Platforms
Data Lake Architecture & The Future of Log Analytics
As enterprise log data continues to grow, organizations will need to start future-proofing their log analytics initiatives with data storage solutions that enable log data indexing and analysis at scale.
Data lakes are a natural fit here – they can ingest large volumes of event logs, ramp up log data storage with limitless capacity, index log data for querying, and feed log data into visualization tools to drive insights.
The example architectures we featured here all deliver on these core capabilities – but only cloud data platforms offer a fully optimized architecture that reduces management complexity and minimizes technical overhead.
If you’re on your way to producing more event logs than you can analyze, or if you’re already there, it’s time to think about an enterprise data solution that delivers hassle-free and cost-effective performance at scale.
Ready to learn more?
For more insights on data lake architecture and the future of log analytics, view our free recorded webinar Advanced Analytics - Data Architecture Best Practices for Advanced Analytics.


