

Can DataOps help data consumers reveal and take action on powerful product insights hidden in operational data? For many companies, the answer is yes!
The emerging practice of DataOps applies Agile development principles and DevOps best practices (e.g. collaboration, automation, monitoring and logging, observability) to data science and engineering, making it faster and easier for organizations to uncover valuable product insights that enable innovation.
The core objectives of DataOps are to efficiently power DevOps analytics, enhance data quality and collaboration, and accelerate data flows within the organization to enable faster insights that can inform product development and guide strategic business decisions.
For example: Product and sales teams (data consumers) can analyze user behavior and product usage data to understand which features are resonating with users and driving customer satisfaction.
A DataOps approach can support this analytics use case by streamlining or automating the flow of data from organizational data owners and managers to data consumers, accelerating those product and UX insights to inform critical decisions, align DevOps with business needs, and drive improvements to the customer experience.

Let’s learn more about DataOps, and what types of DevOps analytics can be most useful to product teams.
What is DataOps?
Logs and event data are generated at every stage in the software development lifecycle. This log data can be transformed, aggregated, and analyzed for a variety of purposes, including:
- Monitoring the performance of applications
- Troubleshooting systems, networks, and machines
- Measuring and understanding user behavior
- Enabling cloud infrastructure observability
- Verifying compliance with internal policies and industry-specific regulations
- Detecting and responding to security threats
- Evaluating the root cause of a network event.
But despite the significant analytical potential of log and event data, many organizations are still lacking the infrastructure and processes necessary to make that data available to consumers for analysis in a timely fashion. That’s where the practice of DataOps comes in.
Gartner defines DataOps as “a collaborative data management practice focused on improving the communication, integration and automation of data flows between data managers and data consumers across an organization.” Meaning, this isn’t a dataops vs devops situation, but rather a partnership. In a simplified Data Ops workflow for product development, data managers can include DevOps teams and data engineers, and data consumers include product, marketing, sales, and other teams that can leverage product data to support their objectives.
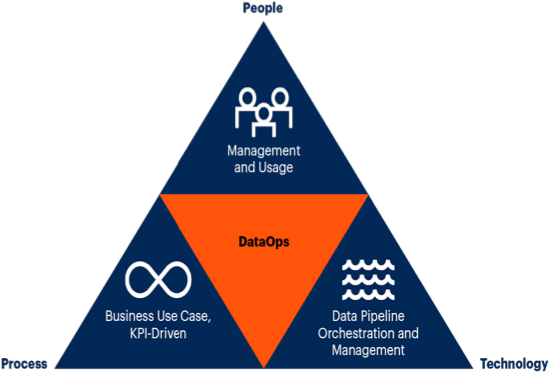
A successful DataOps program is executed across three dimensions: people, process, and technology.
The end goal is to enable and accelerate the availability of high-quality product data that can inform software development, engineering, product marketing, and sales decisions. Ultimately, this helps teams effectively design products for the end user, leading to increased customer satisfaction. Successful SaaS companies such as Datadog, Slack, Calendly and Zoom have used this strategy to accelerate growth and develop features that matter to customers.
Let’s take a look at three practical ways to use DataOps strategies to improve products and services.
3 Ways to Create Better Products with DevOps Analytics
1. Analyzing production log data to troubleshoot application performance and cloud services
For fast-growing ed-tech SaaS company Transeo, application and networking layer log data can make a major difference to the CX. Mission-critical processes within the software have tangible, real-life impacts. For example, a student could potentially not get into college if the software didn’t deliver a transcript correctly to a university.
To prevent these issues from happening, the DevOps team needed access to long-term log data to troubleshoot its cloud services and application performance, and make critical improvements in the software development and delivery process. If a product wasn’t working as expected, it could lead to a poor CX and customer churn. Knowing where to improve certain features and functionality of the platform was critical.
However, the company’s existing cloud DevOps tools for AWS, including observability and analytics tools like Elasticsearch, weren’t efficient or reliable enough to uncover insights hidden within terabytes of log data. This data was generated by Transeo’s applications, load balancers, Kubernetes clusters, and Nginx controllers, all of which had different data formats streaming to Amazon Simple Storage Service (Amazon S3). The end result was an object data store filled with information that was extremely difficult to access and use.
As an alternative, Transeo transformed its existing cloud object storage environment into a data lake for cost-effective analytics at scale. The team implemented DevOps tools for continuous monitoring and leveraged its new cloud data platform to streamline data normalization and indexing, without having to move or transform data. This capability now helps Transeo ground future product decisions in data. In addition, the development team can act quickly on data and ensure that users are not impacted by application and system issues.

2. Measuring user activity to identify sales opportunities
Product data can also help DevOps and product teams understand how features are used, and how application performance impacts certain user outcomes and customer satisfaction. Equipped with this information, DataOps teams can build dashboards for product stakeholders to improve critical features and functionality.
From there, other stakeholders like sales and marketing teams can leverage the same product data to create smarter marketing campaigns or identify the best sales opportunities. For example, Slack analyzed user behavior data to determine which organizations were increasing activity on the Slack platform, then fed this information to sales teams to help accelerate the sales process. The DataOps team at Slack tapped into an internal administrative tool to identify its most active users by tracking metrics like workspace activity, messages/invitations sent, and more. This data proved invaluable, as it allowed Slack’s sales team to tailor its outreach to individual accounts and focus efforts on the users most likely to convert to paying customers.
This tight collaboration of DataOps and business users requires readily accessible data, along with strong data literacy skills to drive faster time to insights. A major part of enabling data literacy is to set up the right infrastructure and approach to data management. For many companies, a data lake architecture is the best choice for efficiently storing, securing, and accessing their data, including log files and other critical information that can reveal important business insights.

3. Analyzing user activity to optimize the customer journey
The right access to product data can also drive customer satisfaction for existing users, especially newly onboarded customers. That’s what DevOps platform GitLab did to ensure that its new users got to the right use cases faster. By looking at a user’s namespace data, the team was able to determine how users progressed through various use cases of their platform. Four example use cases were:
- Version control and collaboration
- Continuous integration
- DevSecOps
- DevOps platform
The GitLab team then analyzed this customer journey data to create personalized onboarding for new users. This process helped users get to the right use case faster, and directed them to the appropriate features in the platform. In some instances, the team identified opportunities to “land and expand” product usage within its customer base. Many other organizations have correlated UX and CX data in a variety of ways, using everything from social media to customer service analytics to create a better product.
Understanding what’s hidden in your data lake
Using log analytics, user and UX data, DevOps and product teams can collaborate to create more innovative products driven by user demand. As mentioned above, a cloud data platform unlocks access to data for DataOps teams, by empowering them to use existing, low-cost cloud storage options such as AWS S3.
From there, it’s simple to correlate various data types, and query data without data movement. Through this process, any DataOps team can discover what’s hidden in their data lake, and how that data can inform product development and future roadmaps.
Ready to learn more?
Access our free white paper Build a DataOps Foundation for Agile Data Analytics to learn more about implementing DataOps to enhance data-driven decision-making in your organization.
Additional Resources
Download the Fact Sheet: 10 Key Tenets for Successful DataOps Implementation
Read the Blog: How to Use Operational IT Data for Product-led Growth
Watch the Webinar: Log Analytics for ITOps, DevOps, & CloudOps

