

A multi-cloud approach helps organizations avoid vendor lock-in, leverage the best available technologies, and reduce costs - but it can also result in added complexity when it comes to centralizing, securing, and analyzing data from cloud applications and services. This blog highlights 5 multi-cloud data management best practices that can help you make the most of your data in multi-cloud environments.

Enterprises are Embracing Multi-cloud Architectures - Here’s Why
Since the first public clouds took shape in the mid-2000s, hyper-scale providers like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure have been steadily innovating new cloud services and competing for market share.
But rather than one of these providers taking over the bulk of the cloud services market, recent trends indicate that we’re heading for a multi-cloud world where most enterprises will leverage more than one public cloud to run their IT operations. In Flexera’s 2023 State of the Cloud Report, 87% of the 750 IT professionals surveyed reported having a multi-cloud strategy, with 72% leveraging both public and private clouds.
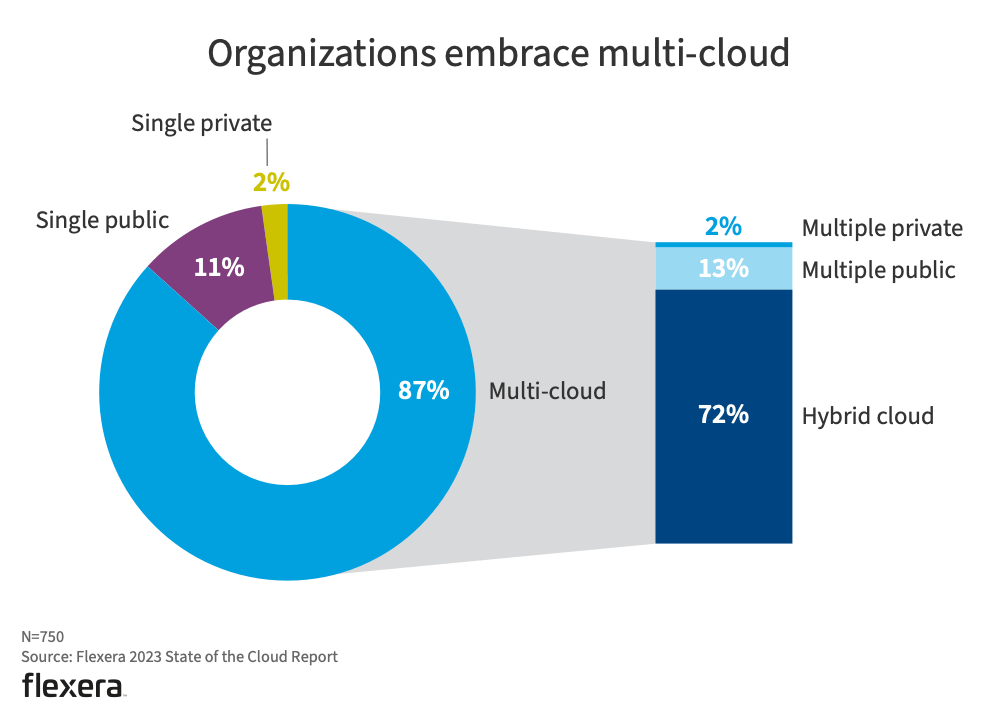
In a 2023 survey of 750 IT professionals, 87% said their organizations were embracing a multi-cloud strategy.
Adopting a multi-cloud approach is helping enterprises avoid vendor lock-in, leverage best-of-breed technologies that may only be available from one or two public clouds, and optimize cloud infrastructure spending by choosing the most cost-effective cloud provider and services for each use case.
5 Multi-cloud Data Management Best Practices You Should Know
1. Enable Data and Application Portability
Data silos and lack of data portability are critical challenges for modern enterprises operating multi-cloud infrastructure.
Each of the major public cloud service providers has its own proprietary APIs for data management, so there’s no simple or standardized way to copy/share data between public clouds. Because of this, even data in multi-cloud environments can often end up siloed inside the public cloud where it was generated or collected. Even organizations that use open-source technologies or data formats struggle with data portability, often having no easy way of transferring data between cloud providers at petabyte scale.
Enterprises pursuing a multi-cloud strategy can enable data portability with cross-cloud data sharing technologies. Cross-cloud solutions are designed to address data silos and portability challenges by enabling cost-effective, high-bandwidth connectivity and data sharing between public clouds. One example is Google’s Cross-Cloud Interconnect, which allows GCP customers to establish cross-cloud connectivity with AWS, Azure, Alibaba Cloud, or Oracle Cloud Infrastructure.
When it comes to application portability, many enterprises are already using containerization and Kubernetes to deploy applications. Major public cloud providers are also offering multi-cloud platform solutions like GCP Anthos, Azure Arc, and Amazon EKS Anywhere that help organizations seamlessly deploy application workloads in multi-cloud environments or deploy cloud services from one provider onto a different provider’s public cloud.
2. Aggregate and Centralize Data in the Cloud
Modern enterprises are generating and collecting more data than ever before, including everything from transactional data to application, event, cloud service, and security logs.
Enterprise DevOps and SecOps teams analyze this data to support use cases like user behavior monitoring, application performance management, and investigating security incidents - but valuable context and insights are lost when the relevant data is siloed across multiple cloud deployments and can’t be analyzed together.
To make the most of the data they collect in multi-cloud environments, enterprises need to aggregate and centralize that data inside a single database, data lake, or cloud data platform where it can be securely stored and analyzed all together to extract insights that support data-driven decision-making.
Both Amazon S3 and Google Cloud Storage can provide a durable, scalable, and cost-effective storage backing for Chaos LakeDB, our data lake database that merges the storage capabilities of a data lake with the accessibility of a cloud database and the analytics capabilities of a data warehouse.

3. Standardize Security Practices Across Cloud Providers
Deploying databases, cloud services, and application workloads across multiple public clouds enlarges your organization’s attack surface, giving digital adversaries more opportunities to target your infrastructure (e.g. with Botnets, malware, and zero-day exploits), and increasing the risk of data breaches.
Some proponents of multi-cloud claim that spreading assets across public clouds can mitigate the risk of a cyber attack, but it’s also possible for a security breach in one cloud to spread horizontally across other clouds in your multi-cloud environment.
To effectively secure multi-cloud environments, organizations must adopt standardized and synchronized security policies that can be applied across all cloud environments regardless of the provider. We also recommend centralizing security data from all public clouds into a single repository like a security data lake that can enable continuous visibility and comprehensive monitoring of the entire multi-cloud environment from a single interface.
4. Implement Multi-cloud Disaster Recovery
IT disaster recovery is a critical aspect of business continuity planning (BCP) for organizations who operate mission-critical or customer-facing applications in the cloud.
Organizations that operate with just a single cloud often depend on cross-region disaster recovery capabilities offered by public cloud providers like Azure and AWS, but there are legitimate concerns about the reliability of this set-up. Here’s why: Some AWS customers run application workloads in the US-East region and failover to the US-West region in case of a cloud service outage, while others run in US-West and failover to US-East. If either of these regions experienced a service outage, there would be a massive increase in load on the other region and probably not enough resources to handle it.
To bypass these limitations and reduce the risk of unacceptable data loss while taking advantage of application portability, organizations should implement a multi-cloud disaster recovery strategy where data and applications from one public cloud can be recovered to a different public cloud in case of an unplanned outage.
5. Optimize Data Retention to Enable Legal Compliance and Analytics Use Cases
When it comes to retaining data in multi-cloud environments, organizations should implement data retention policies based on their legal/regulatory compliance and operational needs.
As a starting point, organizations should conduct a comprehensive inventory of the data they’re generating or collecting, determine which data may be subject to data retention requirements as a result of data security/privacy regulations, and identify which data is needed to support operational processes and objectives.
From there, organizations can establish data retention policies to ensure that critical data is securely and cost-effectively stored for the appropriate length of time to support legal compliance objectives and analytical use cases.
Modern organizations that generate large volumes of data frequently run into data retention limits and trade-offs where potentially useful data is prematurely discarded to reduce data retention costs. By centralizing data in GCS or Amazon S3 and indexing it with Chaos LakeDB, organizations can work around data retention limits and benefit from unlimited cost-effective data retention that supports compliance objectives along with analytics use cases like application performance monitoring, multi-cloud observability, and advanced persistent threat hunting.

Multi-cloud vs. Hybrid Cloud Data Management: What’s the Difference?
Multi-cloud and hybrid-cloud data management have quite a bit in common, but it’s important to understand how and why they are different.
A multi-cloud computing environment uses resources from more than one public cloud provider to run databases, applications, and cloud services, while a hybrid cloud computing environment leverages a combination of on-premise data centers, private cloud, and public cloud infrastructure.
Organizations typically choose a hybrid cloud set-up for one of two reasons:
- They have significant investments in on-premise data centers and hardware.
- They wish to maintain control over their most sensitive data by storing and securing the data on local servers instead of in the public cloud.
So, while multi-cloud data management is generally focused on centralizing, securing, and analyzing data from across multiple public clouds, hybrid cloud data management often places a greater emphasis on:
- Integrating and managing data between on-prem, private cloud, and public cloud services,
- Determining how applications and services should be distributed across on-prem, private, and public cloud infrastructure based on security and compliance needs, and
- Securing the connection between on-prem/private cloud and public cloud infrastructure to safeguard sensitive data on private or on-prem servers.
Unlock the Potential of Multi-cloud Data with Chaos LakeDB
Modern organizations leveraging multi-cloud environments generate both structured and unstructured data on a massive scale that can overwhelm traditional data warehouse applications or search tools like Elasticsearch.
Enter Chaos LakeDB: A SaaS data platform that enables enterprises to aggregate diverse data streams into a single data lake database, automate data pipelines and schema, and active data for full-text search, SQL analytics, and GenAI workloads.
With Chaos LakeDB, multi-cloud enterprises can aggregate cloud data directly in Amazon S3 or GCS and achieve the benefits of live analytics with no labor-intensive data pipeline management, no data movement or ETL process, and no data retention limits or trade-offs.
Ready to learn more?
View our on-demand webinar Unleash the Potential of Your Log and Event Data, Including AI’s Growing Impact to discover how Chaos LakeDB enables cloud observability and security in multi-cloud environments.

