

A data lake is the perfect solution for storing and accessing your data, and enabling data analytics at scale - but do you know how to make the most of your AWS data lake?
In this week’s blog post, we’re offering 10 data lake best practices that can help you optimize your AWS S3 data lake set-up and data management workflows, decrease time-to-insights, reduce costs, and get the most value from your AWS data lake deployment.
What is an AWS Data Lake?
An AWS data lake is a solution for centralizing, organizing, and storing data at scale in the cloud. AWS data lakes can be architected in different ways, but they all use Amazon Simple Storage Service (S3) as a storage backing, taking advantage of its exceptional cost economics and limitless scale.
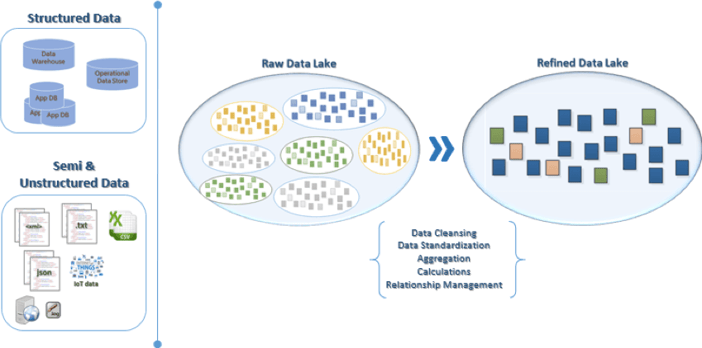
Data lakes provide bulk storage for structured, semi-structured, and unstructured data. Data is ingested and stored in its raw format, cleaned and standardized, then saved in a refined format for use in analytics workflows.
Image Source: ChaosSearch
A typical AWS data lake has five basic functions that work together to enable data aggregation and analysis at scale:
- Data Ingest - Developers use specialized software tools to ingest data from a variety of cloud and on-premise sources into AWS data lake storage.
- Data Storage - Data in an AWS data lake is stored in Amazon S3 cloud object storage.
- Data Indexing/Cataloging - Data lakes connect to analytics services and tools in your data pipeline, enabling analysts and other data consumers to investigate data, create visualizations, and extract insights.
- Data Analysis/Visualization - Data lakes connect to analytics tools in your data pipeline, enabling analysts and other data consumers to investigate data, create visualizations, and extract insights.
- Data Governance - Data lakes require data governance - a set of built-in policies and standards that ensure the quality, availability, and security of the data. This includes security features like RBAC and Amazon S3 logs that record actions taken on Amazon S3 resources.
Developers leverage both AWS and 3rd-party software solutions to implement essential data lake functions and streamline the process of building data lakes in AWS. These include:
- AWS Lake Formation can be used to create data lakes with features that include source crawlers, ETL and data prep, data cataloging, security, and RBAC.
- Fluentd, Logstash, AWS Glue, and AWS Storage Gateway can be used to ingest data into AWS data lakes.
- Amazon Kinesis Data Firehose allows AWS users to load real-time data streams into an AWS data lake to enable streaming analytics.
- Amazon S3 provides scalable, cost-effective, and secure data lake storage.
- Amazon Athena is a serverless, highly scalable analytics solution that can be used to query data from AWS data lakes.
- Amazon Redshift data warehouses are used by developers to analyze data and run complex analytical queries at scale.
- ChaosSearch attaches directly to Amazon S3 storage and provides data governance, indexing, and big data analytics capabilities.
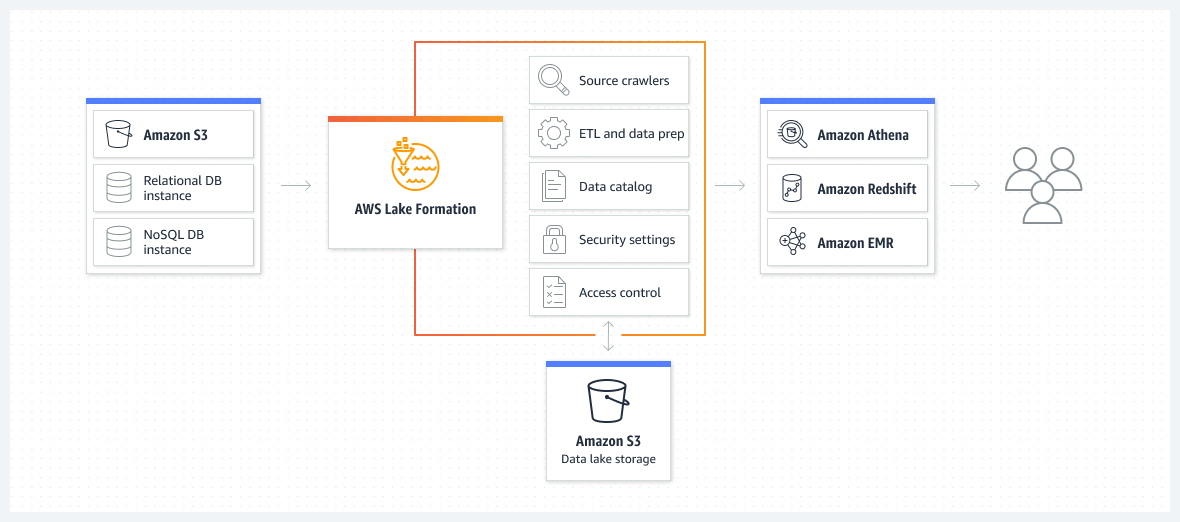
Example architecture for an AWS data lake, built with AWS Lake Formation on top of Amazon S3 cloud object storage.
Next, we’ll look at 10 AWS data lake best practices that you can implement to keep your AWS data lake working hard for your organization.

10 AWS Data Lake Best Practices
1. Capture and Store Raw Data in its Source Format
Your AWS data lake should be configured to ingest and store raw data in its source format - before any data processing, cleaning, or data transformation takes place.
Storing data in its raw format gives analysts and data scientists the opportunity to query the data in innovative ways, ask new questions, and generate novel use cases for enterprise data. The on-demand scalability and cost-effectiveness of Amazon S3 data storage means that organizations can retain their data in the cloud for long periods of time and use data from today to answer questions that pop up months or years down the road.
Storing everything in its raw format also means that nothing is lost. As a result, your AWS data lake becomes the single source of truth for all the raw data you ingest.
Read White Paper: The New World of Data Lakes, Data Warehouses, and Cloud Data Platforms
2. Leverage Amazon S3 Storage Classes to Optimize Costs
Amazon S3 object storage offers multiple different classes of cloud storage, each one cost-optimized for a specific access frequency or use case.
Amazon S3 Standard is a solid option for your data ingest bucket, where you’ll be sending raw structured and unstructured data sets from your cloud and on-premise applications.
Data that is accessed less frequently costs less to store. Amazon S3 Intelligent Tiering saves you money by automatically moving objects between four access tiers (frequent, infrequent, archive, and deep archive) as your access patterns change. Intelligent tiering is the most cost-effective option for storing processed data with unpredictable access patterns in your data lake.
You can also leverage Amazon S3 Glacier for long-term storage of historical data assets or to minimize the cost of data retention for compliance/audit purposes.
Watch Free Webinar Recording: Three Ways to Make Your Data Lake Deliver
3. Implement Data Lifecycle Policies
Data lifecycle policies allow your cloud DevOps team to manage and control the flow of data through your AWS data lake during its entire lifecycle.
They can include policies for what happens to objects when they enter S3, policies for transferring objects to more cost-effective storage classes, or policies for archiving or deleting data that has outlived its usefulness.
While S3 Intelligent Tiering can help with triaging your AWS data lake objects to cost-effective storage classes, this service uses pre-configured policies that may not suit your business needs. With S3 lifecycle management, you can create customized S3 lifecycle configurations and apply them to groups of objects, giving you total control over where and when data is stored, moved, or deleted.
4. Utilize Amazon S3 Object Tagging
Object tagging is a useful way to mark and categorize objects in your AWS data lake.
Object tags are often described as “key-value pairs” because each tag includes a key (up to 128 characters) and a value (up to 256 characters). The “key” component usually defines a specific attribute of the object, while the “value” component assigns a value for that attribute.
Objects in your data lake can be assigned up to 10 tags and each tag associated with an object must be unique, although many different objects may share the same tag.
There are several use cases for object tagging in S3 storage - you can replicate data across regions using object tags, filter objects with the same tag for analysis, apply data lifecycle rules to objects with a specific tag, or grant users permission to access data lake objects with a specific tag.
5. Manage Objects at Scale with S3 Batch Operations
With S3 Batch Operations, you’ll be able to execute operations on large numbers of objects in your AWS data lake with a single request. This is especially useful as your AWS data lake grows in size and it becomes more repetitive and time-consuming to run operations on individual objects.
Batch Operations can be applied to existing objects, or to new objects that enter your data lake. You can use batch operations to copy data, restore it, apply an AWS Lambda function, replace or delete object tags, and more.

6. Combine Small Files to Reduce API Costs
When you store data in S3 as part of your AWS data lake solution, you’ll incur three types of costs:
- Storage costs, on a per-GB basis.
- API costs, based on the number of API requests you make.
- Data egress costs, charged when you transfer data out of S3 or to a different AWS region.
If you’re using your AWS data lake to support log analytics initiatives, you could be ingesting log and event files from tens, hundreds, or even thousands of sources. If you ingest frequently, you’ll end up with a huge number of small log files, each stored as a separate object. Now imagine you want to perform operations on those files: each object gets its own API call, billed separately.
By combining smaller files into larger ones, you’ll be able to cut down on the number of API calls needed to operate on your data. Combining one thousand 250 kilobyte files into a single 25MB file before performing an API call would reduce your costs by 99.9%.
Read: Top 5 AWS Logging Best Practices
7. Manage Metadata with a Data Catalog
To make the most of your AWS data lake deployment, you’ll need a system for keeping track of the data you’re storing and making that data visible and searchable for your users. That’s why you need a data catalog.
Cataloging data in your S3 buckets creates a map of your data from all sources, enabling users to quickly and easily discover new data sources and search for data assets using metadata. Users can filter data assets in your catalog by file size, history, access settings, object type, and other metadata attributes.
8. Query & Transform Your Data Directly in Amazon S3 Buckets
The faster your organization can generate insights from data, the faster you can use those insights to drive business decision-making. As it turns out, needing to move data between storage systems for analysis is the number-one cause of delays in the data pipeline.

AWS users report that needing to move data before analysis is the biggest challenge they face when using and managing AWS S3 object storage.
Image Source: ChaosSearch
Despite that, many organizations are using some sort of ETL process to transfer data from S3 into their querying engine and analytics platforms. This process can result in delays of 7-10 days or more between data collection and insights, preventing your organization from reacting to new information in a timely way (IDC). This is especially harmful for use cases like security log analysis, where timely threat detection and intervention protocols are necessary to defend the network.
Instead of moving data with ETL, your AWS data lake should be configured to allow for querying and transformation directly in Amazon S3 buckets. Not only is this better for data security, you’ll also avoid egress charges and reduce your time-to-insights so you can generate even more value from your data.
9. Compress Data to Maximize Data Retention and Reduce Storage Costs
Amazon S3 is the most cost-effective way to store a large amount of data, but with data storage billed on a per-GB basis, it still makes sense to minimize those costs as much as possible.
At ChaosSearch, we addressed this challenge by creating Chaos Index®, a distributed database that indexes and compresses your data by up to 95% (while enabling full text search and relational queries - not bad, huh?). Our ability to index and compress your raw data while maintaining its integrity means that you’ll need fewer storage, compute, and networking resources to support your long-term data retention objectives.
Read: Data Transformation & Log Analytics: How to Reduce Costs and Complexity
10. Simplify Your Architecture with a SaaS Cloud Data Platform
Data lake solutions are supposed to make your life easier, enabling you to search and analyze your data more efficiently at scale. At the same time, AWS data lake deployments can be complex and involve many different moving parts - applications, AWS services, etc. An overly complex data lake architecture could result in your organization spending hours each week (or each day!) managing and troubleshooting your data lake infrastructure.
With a SaaS cloud data platform like ChaosSearch, you can substantially simplify the architecture of your AWS data lake deployment. Available as a fully managed service, ChaosSearch sits on top of your AWS S3 data store and provides data access and user interfaces, data catalog and indexing functionality, and a fully integrated version of the Kibana visualization tool.
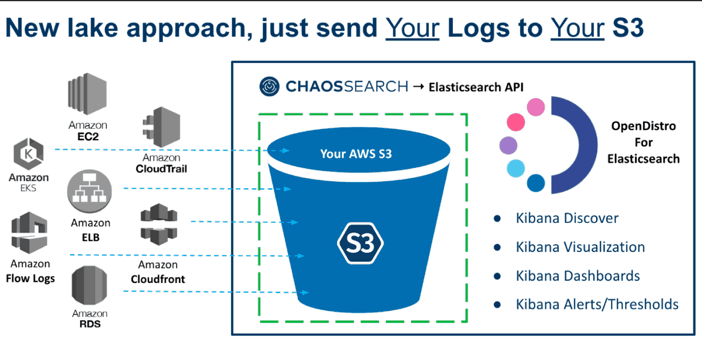
A simplified data lake architecture featuring the Chaos Search Platform
Image Source: ChaosSearch
By covering all of these key functions with a single tool you can significantly simplify your data lake architecture - that means less time tuning and tweaking, and more time developing new insights from your data.
Read: Identify Anomalies in your AWS CloudTrail Data
AWS Data Lake Use Cases
Log Analytics
Log analytics is a valuable use case for your AWS data lake. Log data is automatically generated by the networks, applications, and cloud services that make up your IT infrastructure. You can ingest log data from these sources into your AWS data lake and analyze them to:
- Assess application performance and gain deeper application insights to optimize customer experiences,
- Hunt for security anomalies and advanced persistent threats (APTs) within your IT infrastructure, and
- Troubleshoot AWS cloud services.
The unique architecture of ChaosSearch helps enterprise IT teams reduce AWS log analytics costs and overcome serverless log management challenges by eliminating unnecessary data movement.
Monitoring AWS Services
Monitoring the health and performance AWS services is critical to ensuring their availability and reliability, proactively detecting performance/functionality issues, capacity planning, maintaining cloud security, and optimizing your costs.
AWS customers can use tools like Amazon CloudWatch and Kinesis Firehose to collect log data from AWS cloud services, but face increased costs and complexity as they scale daily ingest and analytical workloads.
ChaosSearch overcomes these AWS monitoring challenges by allowing AWS customers to centralize log data from Amazon cloud services in an AWS data lake and analyze it with no data movement or complex ETL process.
Read: How to Optimize the AWS CloudWatch Log Process
Optimize Your AWS Data Lake Deployment with Best Practices
When data lakes were first imagined, organizations envisioned a world where democratized, cost-effective data access would drive the creation of valuable insights at scale - ideally without a lot of complexity and technical overhead.
With these AWS data lake best practices, you’ll be able to configure and operate a data lake solution that fulfills that vision and empowers your organization to extract powerful insights from your data faster than ever before.
Ready for the next step on your data journey?
For more AWS data lake best practices and insights on building an AWS data lake for your business, view our free recorded webinar on Advanced Analytics - Data Architecture Best Practices for Advanced Analytics.


